�����ַ�����������������䷨�Զ������㷨
������1, 4���� ��2, 3���� ��4��������4
(1. ���ϴ�ѧ ��������Ϣ����ѧԺ������ ��ɳ��410082��
2. ��۳��д�ѧ ���ķ��뼰����ѧϵ����� 999077��
3. ���ݴ�ѧ �������ѧ�뼼��ѧԺ������ ���ݣ�215006��
4. ���Ϲ�ҵְҵ����ѧԺ ��Ϣ����ϵ������ ��ɳ��410208)
ժ Ҫ�������ַ��ڴ�λ���ض���λ�������־�����ã�ʹ�÷�ӳ��������������Ե�������������䷨�����������ַ�������������䷨�Զ������㷨�����㷨ʹ�ô���ͷ2���ַ�����β�����1���ַ��Լ���β�����2���ַ���3�����͵��ַ���������ǿ��������ѧϰ�����õ�1�����͵���������ӳ����Ĵʻ���̬�ص㣬���ú�2�����͵��������ַ�ӳ������������ĺ��õ��������ԡ���CoNLL-2009�������Ͽ��Ͻ���ʵ���Լ�����ʵ����������������������������ȣ����㷨��Ч����߷�������UASָ��(���ޱ�������ϵ����ȷ��)��LASָ��(�����Ǵ���ǵ������ϵ����ȷ��)�������߷������ľ�������
�ؼ��ʣ������Ӧ�ã�����䷨�������ַ�������
��ͼ����ţ�TP391 ���ױ�ʶ�룺A ���±�ţ�1672-7207(2009)04-1035-05
Japanese dependency parsing based on character-level features
WEN Yi-min1, 4, ZHAO Hai2, 3, LI Jian4, HUANG Han-wen4
(1.College of Electrical and Information Engineering, Hunan University, Changsha 410082, China;
2. Department of Chinese Translation and Linguistics, City University of Hongkong, Hongkong 999077, China;
3. School of Computer Science and Technology, Soochow University, Suzhou 215006, China;
4. Department of Information Engineering, Hunan Industry Polytechnic, Changsha 410208, China)
Abstract: Based on the indicative impact of character located at a special position in a word, an algorithm was proposed to make use of character-level features that reflect the characteristics of Japanese to enhance the performance of Japanese dependency parsing. Three character-level features denoted by the first two characters, the last character, and the last two characters inside a word were adopted. The first type of features was used for the morphological purpose, and the latter two demonstrate that the emphasis in Japanese trends to locate at the end of an expression segment in the sentence. The results of experiments and evaluation on the Japanese corpus from CoNLL-2009 shared task show that the accuracy of Japanese dependency parser can be effectively improved by using the proposed features.
Key words: computer application; dependency parsing; character-level feature
�ڶ����ֵľ䷨�����У������ĵ�����䷨��������[1]��Ŀǰ��������������������䷨������Ϊ2�ࣺ����ͼģʽ(Graph-based)������䷨����ģ�ͺͻ���ת��(Transition-based)������䷨����ģ�͡�����ͼģʽ������䷨����ģ����ҪΪ�������ƶ�1�����ʺ��������˸��ʺ���ͨ���ֽ�Ϊ���������ʵ��ۼ�֮�͡��������ͼ������䷨����ģ�͵�������Ҫ���������������ʺ����Ķ���������㷨������ͼ������䷨����ģ�ͼ�����[2-4]������ת��������䷨����ģ��ͨ��ִ�������Ķ������(Action)��ת��(Transition)����������[5]���������ת��������䷨����ģ�͵�������Ҫ���ڶ�����ת�����ԵIJ�ͬ�Ͷ���������ʹ�õĻ���ѧϰģ��(��֧��������(SVM)�������)��ͬ[6]������ת��������䷨����ģ�ͼ�����[7-10]���������䷨��������һ�����������ĵ�����䷨���������ǻ��ڸ��ʷ����IJ�ȷ��������Duan��[10-11]֤����ȷ���Եľ䷨�������ܸ��ţ�ͬʱЧ�ʸ��ߡ����������ȷ���Է����ںܴ�̶��Ͽ��Թ��Ϊ�ƽ���Լ������Ҳ���ǵ��͵Ļ���ת���ķ��������ǣ���������͵�Nivre�㷨���ڲ��������[7]�е��㷨��Ҫ4�ַ���������������[10]���㷨ֻ��Ҫ3�֡�Iwatate��[12]��Ϊ������ͼģʽ�ķ��������ķ����в������������ƣ���ʵ������֤�����ĵ�����䷨�������ʺ��û���ת���ķ��������д����Ĺ۵㡣�ڴˣ��������߶���������䷨�����㷨���иĽ�������ʹ���ַ�(�������������֡����ȶ���������д�ɷ�)������������ǿ������ѧϰ�����о���ͬ�����е���Щ���ص㼯����ѧϰ��������Ĺ���������ǿ��ϵͳ��ʹ�÷�ӳ��������������Ե�������
1 ѧϰģ��
����Nivre��ʽ���ƽ���Լ�����Ϊ�����ľ䷨ѧϰ���[7]������ת���ľ䷨��������ʵ������һ�ִʶԵķ�����������ڴ���ͶӰ�͵�������ӡ�����;䷨ͳ��������˵��ǡǡ��һ�ָ߶�ͶӰ�Ե����ԣ���ˣ�����ת����ѧϰģ���ʺ�����ṹѧϰ��
��Nivre��ܵľ䷨�����У�����������һ������ɨ������ľ��ӣ�ͬʱ�������Ѿ��������IJ��־��ӵ�״̬��������˵��ʹ��1��ջ��ά���Ѿ��õ������IJ��־��ӡ���ÿ��״̬�����������2���ʣ�1����λ��ջ��(ͨ����TOP��ʾ)������1����λ����δ�����ľ��ӵ��ײ�(ͨ����NEXT��ʾ)�����ݷ�������������������Ƿ�������ʶ�֮�佨��һ���������ϵ�����û�����ʾ�����ϵ�������2�ֻ�������TOP��NEXT֮��Ĺ�ϵ���������������Ĵ�(��λ��)���һ�����ǰ�������Ĵʡ�����������Ҫ�ƽ���Լ2�����������ɨ����ӵIJ�������ˣ���1���ޱ�ǵ���������У���Ҫ4�������
a. ������1����NEXT��TOP�Ļ���ͬʱ����TOP����ջ��
b. �һ�������1����TOP��NEXT�Ļ���ͬʱ����NEXT����ջ��
c. ��Լ����TOP����ջ��
d. �ƽ�����NEXT����ջ��
�ڽ������һ��IJ����ϣ�ѡ�����������IJ��ԣ�Ҳ����˵�������������ķ������жϻ����ڣ����������������������ͺ�ȴ��������б�������������ɨ����ӵķ����ϣ�ʹ������ɨ�裬Ҳ���Ǵ�������ɨ�衣
���ĵ������ϵ��������������ǡ�����3�֣�D��I��P���һ�ֻ��1�֣�D��Ϊ�˽���1������ϵͳ��1����������ľ䷨�������Ҫ��չ�������һ����ޱ�Dz����������صĻ�����������������6�����ķ���������Ҫ�������ķ���������ɡ�
������һ���߶�ͶӰ�������ԣ����ǣ���Ȼ�������ķ�ͶӰ������Ӵ��ڣ�Ϊ�˴����ⲿ���������Σ�ʹ�þ��������δ�����αͶӰ������[13-14]������αͶӰ�������ǽ���ͶӰ����������Ĵ�ת�ƣ�������˵������������Ĵʵ�ԭʼ���Ĵʵ����Ĵʣ�ͬʱ�����Ӷ�������������룬�Ա��ڽ���ʱ�ָ�ԭ���ķ�ͶӰ�������ϵ�����ǣ���һ����/�ָ�����������һ�ָ߶�ͶӰ�������ԡ���Ӣ���ϲ�����ʹ�����ܵõ�����������������ʱ�ᵼ��ʼ��������ķ�ͶӰ�������ϵ����ˣ���Ҫʹ��2�����������������⣺��1����ֱ���������Ĵʶ�����Ҫ�κθ��ӵ����������룬Ҳ�����ڽ���ʱ���ٻָ�ԭʼ�ķ�ͶӰ�����棻��2�����ڳ���������ķ�ͶӰ������ʱ����������Ĵʣ���ͼ�����Ĵ�ת�Ƶ��ôʣ�һ���ҵ�������������������ʵ��֤�����������ֲ��������������������ķ�ͶӰ�����ϵ��
��ͳ�Ļ���ת�������������ʹ�õķ�����ͨ����֧��������(SVM)�����������ڱ߽�����ڼ���ķ��������ǣ���Щ������������ѧϰ�б���Ϊѵ��ʱ�䳤�ͽ����Ч�������Ȼ���ͼģʽ�ķ�����Ҫ���ܶࡣZhao��[14]ʹ���������Ϊ����������֤�����������Ϊ����ת������������ķ�������ʹ���������ܸ��š���ˣ����ļ���ʹ����һ����ߡ�
����䷨�����������������漰�������أ�Ϊ�˷����ʾ��������һ������Ǻţ����1��ʾ��
��1 ���ڱ�ʾ�����Ļ����Ǻ�
Table 1 Basic marks of features

���ݱ�1�еļǺţ��ó�ʹ�õIJ��ֻ��������������2��ʾ��
��2 ���ֻ���������
Table 2 Set of partial baseline features

2 �����ַ��ʹִ��Ե�����
�����ַ�������Ŀ������������д��ʽ�ͺ������һ���������ԡ������Ǽ������Ǻ��֣��ַ����ڴ�λ���ض�λ�÷����˱�־�����á��ر��ǣ������к��ֵ�ʹ�ýϹ㷺����һ�ĺ��־��ж��صĺ��塣��ˣ��ַ������п��ܽ�ʾ���������������Ϣ���ھ䷨������
����3�����͵��ַ�����������1���Ǵ���ͷ2���ַ�����ʾΪfirstTwoChar����2���Ǵ�β�����1���ַ�����ʾΪlastChar����3���Ǵ�β�����2���ַ�����ʾΪlastTwoChar��ע�ǰ1���ַ���������Ϊ�����ַ�����˵��������һ�����ĺ��õ����ԡ��ַ����������3��ʾ��
��3 �ַ�������
Table 3 Character-level features

���˿����ַ��������⣬���������ַ��������ʹִ��������Ľ�ϡ��ִ�������ԭʼ���Եļ�����2������Ĵִ��ԣ�ԭʼ���Եĵ�1����ĸ����Ϊcpos1��ԭʼ���Ե�ͷ2����ĸ����Ϊcpos2�����磬��ԭʼ����ΪNNP����cpos1=N����cpos2=NN����֤�����ִ��������ڹ⻬����Ĵ���������
3 �� ��
Ϊ��ϵͳ������������㷨���ܣ�ʹ�����µ�CoNLL-2009�������������������Ϊ�������ϣ���֤�����ַ�������������Ч��[14]��CoNLL-2009��������������������Ծ�����ѧ�ı����Ͽ�(Kyoto University Text Corpus 4.0)�����˹���ע���Դ������������[15]�����ǣ����ı�������Ҫ�õ���ÿ�����š�����Ȩ��
CoNLL-2009���������ṩ���ı��Ѿ�ת��Ϊ���ڴʵ�������ʽ����ˣ�����ֱ��ʹ����һ���ϡ����������ϵĸ��Ӿ䷨ѵ����(����33 257��)������ѵ�������ٽ���������ѧϰ��ѵ����(4 393�䣬ͬʱ�����䷨��Ϣ)��ǰ�벿����Ϊ����������벿����Ϊ���Լ������ñ��Ŀ�������ԭ���Ǹÿ�������ģ̫С������250�䣬��ʹ���������ͳ�������Բ�ǿ��
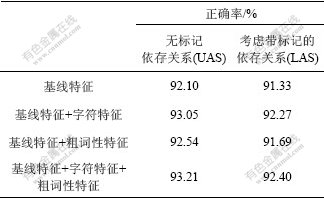
��������ʹ������䷨��������ͨ�е�UAS(���ޱ�������ϵ����ȷ��)��LAS(�����Ǵ���ǵ������ϵ����ȷ��)��ʵ�������4��ʾ�����Կ���������ʹ�û��������Ѿ���ýϸߵ����ܣ������ַ�������UAS��LASָ����ȷ��������1%����ͬʱ�����������ʹִ�������ʱ��ϵͳ������������1%��
��4 ʵ�����Ƚ�
Table 4 Experimental results
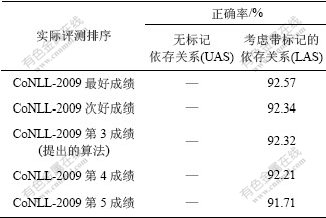
��5��ʾΪ��CoNLL-2009����ʵ���Լ�������������CoNLL-2009�������У�û��ʹ�ôִ�����������ʹ�����ַ������ͻ���˽ӽ����ŵĽ����ͬʱ��CoNLL-2009����䷨�IJ��Լ���С��Լ400�䡣��ˣ���4�н����ͳ�������Ը��š�
��5 CoNLL-2009��������䷨���������Ƚ�
Table 5 Evaluation of Japanese dependency parsing on CoNLL-2009
4 �� ��
a. �����ַ��ڴ�λ���ض���λ�õı�־�����ã�ʹ�÷�ӳ��������������Ե�������������䷨��ʹ�ô���ͷ2���ַ�����β�����1���ַ��ʹ�β�����2���ַ���3�����͵��ַ�����������ǿ��������ѧϰ�������˻����ַ�������������䷨�Զ������㷨��
b. ��CoNLL-2009�������Ͽ��ϵ�ʵ���Լ�CoNLL-2009�ϵ���ʵ���Լ���������������������ַ�������ʹUASָ���LAS��ȷ��������1%��ͬʱ�������������ʹִ�������ʱϵͳ������������1%����ˣ������������ȣ����㷨��Ч������˷��������ܡ�
�ο����ף�
[1] Safir K. The syntax of (in)dependence[M]. Cambridge: MIT Press, 2004.
[2] McDonald R, Pereira F, Ribarov K, et al. Non-projective dependency parsing using spanning tree algorithm[C]// Proceedings of the Joint Conference on Human Language Technology and Empirical Methods in Natural Language Processing (HLT/EMNLP). Vancouver: ACL, 2005: 523-530.
[3] Nakagawa T. Multilingual dependency parsing using global features[C]//Proceedings of the Joint Meeting of the Conference on Empirical Methods on Natural Language Processing and the Conference on Natural Language Learning(EMNLP/CoNLL). Prague: A CL, 2007: 952-956.
[4] Carreras X. Experiments with a high-order projective dependency parser[C]//Proceedings of the Joint Meeting of the Conference on Empirical Methods on Natural Language Processing and the Conference on Natural Language Learning(EMNLP/CoNLL). Prague: ACL, 2007: 957-961.
[5] ������, �� ��, �� ��. ���ڶ�����ģ����������䷨����[J]. ������Ϣѧ��, 2007, 21(5): 25-30.
DUAN Xiang-yu, ZHAO Jun, XU Bo. Chinese dependency parsing based on action modeling[J]. Journal of Chinese Information Processing, 2007, 21(5): 25-30.
[6] Yamada H, Matsumoto Y. Statistical dependency analysis with support vector machines[C]//Proceedings of the 8th International Workshop on Parsing Technologies. Nancy: ATOLL, 2003: 195-206.
[7] Nivre J. An efficient algorithm for projective dependency parsing[C]//Proceedings of the 8th International Workshop on Parsing Technologies. Nancy: ATOLL, 2003: 149-160.
[8] Titov I, Henderson J. A latent variable model for generative dependency parsing[C]//Proceedings of the Tenth International Conference on Parsing Technologies. Prague: ACL, 2007: 144-145.
[9] Yamada H, Matsumoto Y. Statistical dependency analysis with support vector machines[C]//Proceedings of the 8th International Workshop on Parsing Technologies. Nancy: ATOLL, 2003: 195-206.
[10] Duan X, Zhao J, Xu B. Probabilistic parsing action models for multi-lingual dependency parsing[C]//Proceedings of The Joint Meeting of the Conference on Empirical Methods on Natural Language Processing and the Conference on Natural Language Learning(EMNLP/CoNLL). Prague: ACL, 2007: 940-946.
[11] Kudo T, Matsumoto Y. Japanese dependency analysis using cascaded chunking[J]. Transactions of Information Processing Society of Japan, 2002, 43(6): 1834-1842.
[12] Iwatate M, Asahara M, Matsumoto Y, Japanese dependency parsing using a tournament model[C]//Proceedings of the 22th International Conference on Computational Linguistics. Manchester:ACL, 2008: 361-368.
[13] Nivre J, Jens N. Pseudoprojective dependency parsing[C]// Proceedings of the 43th Annual Meeting on Association for Computational Linguistics. AnnArbor: ACL, 2005: 99-106.
[14] Zhao H, Kit C. Parsing syntactic and semantic dependencies with two single-stage maximum entropy models[C]//Proceedings of the Twelfth Conference on Computational Natural Language Learning. Manchester: ACL, 2008: 203-207.
[15] Kawahara D, Kurohashi S, Hasida K. Construction of a Japanese relevance-tagged corpus[C]//Proceedings of the 3rd International Conference on Language Resources and Evaluation. Las Palmas de Gran Canaria: European Language Resources Association, 2002: 2008-2013.
�ո����ڣ�2008-09-05�������ڣ�2008-11-25
������Ŀ�����ҡ�863���ƻ���Ŀ(2007AA04Z244)��������Ȼ��ѧ�����ص�������Ŀ(60835004)������ʡ��ʿ���������ר��ƻ���Ŀ(2008RS4005)������ʡ������ѧ��ʮһ�塱�滮����(XJK08BXJ001)
ͨ�����ߣ�������(1969-)���У������ҽ��ˣ���ʿ�������ڣ����»���ѧϰ����Ȼ�������⼰ͼ�������о����绰��0731-88539059��E-mail: ymwen2004@yahoo.com.cn

