Network-aware perceptual error concealment method for H.264 video with side information
来源期刊:中南大学学报(英文版)2010年第4期
论文作者:马汉杰 陈耀武
文章页码:816 - 823
Key words:error concealment; reliability weight; perceptual weight map; weighted pixel interpolation; motion compensation; side information; H.264
Abstract: In order to improve the video quality of transmission with data loss, a spatial and temporal error concealment method was proposed, which considered both the state information of the network and the perceptual weight of the video content. The proposed method dynamically changed the reliability weight of the neighboring macroblock, which was used to conceal the lost macroblocks according to the packet loss rate of the current channel state. The perceptual weight map was utilized as side information to do weighted pixel interpolation and side-match based motion compensation for spatial and temporal error concealment, respectively. And the perceptual weight of the neighboring macroblocks was adaptively modified according to the perceptual weight of the lost macroblocks. Compared with the method used in H.264 joint model, experiment results show that the proposed method performs well both in subjective video quality and objective video quality, and increases the average peak signal-to-noise ratio (PSNR) of the whole frame by about 0.4 dB when the video bitstreams are transmitted with packets loss.
J. Cent. South Univ. Technol. (2010) 17: 816-823
DOI: 10.1007/s11771-010-0561-x![]()
MA Han-jie(马汉杰), CHEN Yao-wu(陈耀武)
Institute of Advanced Digital Technologies and Instrumentation, Zhejiang University, Hangzhou 310027, China
? Central South University Press and Springer-Verlag Berlin Heidelberg 2010
Abstract: In order to improve the video quality of transmission with data loss, a spatial and temporal error concealment method was proposed, which considered both the state information of the network and the perceptual weight of the video content. The proposed method dynamically changed the reliability weight of the neighboring macroblock, which was used to conceal the lost macroblocks according to the packet loss rate of the current channel state. The perceptual weight map was utilized as side information to do weighted pixel interpolation and side-match based motion compensation for spatial and temporal error concealment, respectively. And the perceptual weight of the neighboring macroblocks was adaptively modified according to the perceptual weight of the lost macroblocks. Compared with the method used in H.264 joint model, experiment results show that the proposed method performs well both in subjective video quality and objective video quality, and increases the average peak signal-to-noise ratio (PSNR) of the whole frame by about 0.4 dB when the video bitstreams are transmitted with packets loss.
Key words: error concealment; reliability weight; perceptual weight map; weighted pixel interpolation; motion compensation; side information; H.264
1 Introduction
The applications of video communications, especially over the wireless channels, are rapidly increasing and in the meanwhile, the requirements for good video quality transmission are also growing. The difficulty lies in that the data packets may be lost or damaged due to either traffic congestion in the current Internet or bit errors in the wireless networks caused by impairments of physical channels [1]. Moreover, the use of predictive coding and variable length coding in video compression makes the transmitting data more sensitive to data errors. In order to solve this problem, many techniques were proposed, such as forward error correcting (FEC), automatic repeat request (ARQ), error resilient encoding and error concealment.
Error concealment is always applied at the decoder side and carries less overhead bandwidth and has no delay. It recovers the lost information by utilizing the smoothing property of image or video signals and the spatial/temporal interpolation [2-3]. ZENG and LIU [4] proposed a spatial error concealment method based on geometric structure, CHEN et al [5] proposed an error concealment method using a context-based model, and YE et al [6] presented a content-based error concealment method by block classification. In order to improve the performance of error concealment, error resilient tools, such as scalable coding [7], multi-description coding [8], reference picture selection [9] and redundant pictures [10], were combined in some other applications.
Side information is also a very useful tool to improve the error concealment. It can be embedded into the video information without much more overhead and delay [11-13], and can also be combined with other error resilient tools [14].
The latest video compression standard H.264 performs well in the compression ratio. Although there are many error resilient tools, it still needs error concealment at the decoder when there are some data loss presented [15]. In order to improve the video quality of this latest video compression standard, many video concealment tools were also proposed. WANG et al [16] proposed an error concealment method based on pixel interpolation and motion estimation, which was employed in the H.264 joint model. XU and ZHOU [17] refined the error concealment using sub-blocks and directional edges. BU et al [18] proposed an error concealment method with significant macroblock determination and protection. CHUNG et al [19] proposed an error concealment for the intra-frame with bit-error detection and directional concealment.
The above methods did not take the current channel state information into consideration. In other words, they did not consider the reliability of the reconstructed macroblocks to conceal the lost data. In this work, a network-aware perceptual error concealment method with side information was proposed. Depending on the current channel state information, the proposed method dynamically changed the reliability weight of the reconstructed macroblocks according to the packet loss rate. The content of the encoded video frame was also taken into consideration and the perceptual weight map of the video frame was utilized as the side information. Based on these two factors, the weight interpolation and side-match based motion compensation was used to perform spatial and temporal error concealment in order to reconstruct the lost video data, respectively.
2 Proposed spatial and temporal error concealment
The general flow diagram of the proposed spatial and temporal error concealment is shown in Fig.1. Assuming that the side information can be obtained from the other priority channels [11], embedding formation in the discrete cosine transform (DCT) coefficients [12], or from the user defined data in the bit-streams such as the supplemental enhancement information (SEI) messages in the H.264 standard [20]. The channel state information, such as packet loss rate, can also be obtained from the physical layer or dynamically measured through the real-time control protocol (RTCP). When data loss presents in the video bitstream, the video decoder will detect the bit errors in the parsing bitstream step. Then, the spatial and temporal error concealments are utilized using both the side information and the channel state information to conceal the lost data and improve the video quality of the reconstructed pictures in the decoder buffer.
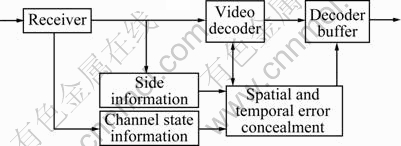
Fig.1 General flow diagram of proposed spatial and temporal error concealment
2.1 Reliability weight of reconstructed macroblacks
When data loss occurs in a bitstream slice, the rest macroblocks of the slice will also be damaged due to spatial prediction and variable-length coding. In addition, the data loss will affect the macroblocks in subsequent frames when temporal prediction is used. The above spatial and temporal error propagations are shown in Fig.2.
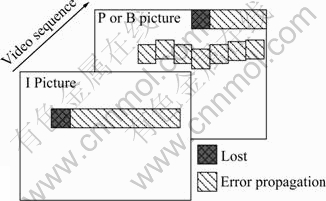
Fig.2 Diagram of data loss propagation
To reduce the impact of data loss on the visual information, smoothness based spatial and temporal error concealments are employed based on pixel interpolation and motion compensation [21]. These error concealment algorithms utilize the reconstructed neighboring macroblocks in the current frame or the reference frame, including correctly received and concealed macroblocks, to build the current lost or damaged macroblock shown in Fig.3.
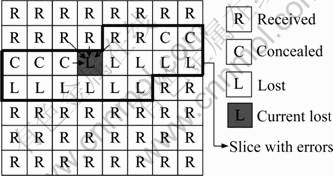
Fig.3 Macroblock status map with data loss
But not all the neighboring macroblocks should be treated with the same reliability weight with the data loss. When a macroblock datum is correctly received, it can be reconstructed correctly and should be totally reliable. But when a macroblock datum is lost, it will be “guessed” using the reconstructed neighboring macroblocks. Then, the distortion brought in for the “guess” is usually not accurate enough. Hence, the concealed macroblocks should not be treated with the same reliability as the correctly received macroblocks being treated. Moreover, if the concealed macroblocks are used to reconstruct the following lost macroblocks, the distortion will propagate and the reliability of the subsequently reconstructed ones will also be reduced.
From the above analysis, it can be seen that the reliability of the reconstructed macroblocks has an inverse ratio to the distortion. The distortion caused by data loss can be predicted using packet loss probability P [22] and then the reliability of the reconstructed macroblocks can be measured accordingly as shown in Eq.(1). Moreover, in the smoothness based error concealment, the reconstruction process of the lost or damaged macroblocks depends on the neighboring macroblocks. Thus, the reliability weight of the concealed macroblock should be measured according to the reliability of the neighboring macroblocks. Assuming that the correctly received macroblock has the reliability weight of 1, the lost macroblock will have the reliability weight of 0, and then the measurement of the reliability weight of the concealed macroblock can be defined as
![]() (1)
(1)
where WR denotes the reliability weight of the concealed macroblock; (i, j) denotes the coordination of the current macroblock in the current video frame; Mavg denotes the average of WR(m); Nmb denotes the neighbor macroblocks and P denotes the packet loss probability.
2.2 Side information of perceptual weight map
When a macroblock is damaged by data loss, smoothness based error concealment using neighboring macroblocks is always employed to reconstruct the lost macroblock [16]. As shown in Fig.4, the spatial error concealment uses distance based weighted pixel interpolation, and the temporal error concealment uses side-match based motion compensation. But these algorithms do not consider the content of the video frame, so they do not perform well in the details of the picture and in the subjective video quality.
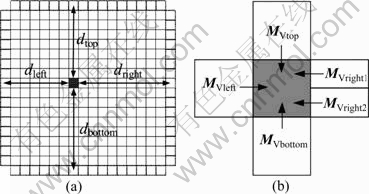
Fig.4 Spatial and temporal error concealment (d denotes pixel distances and MV denotes motion vectors): (a) Spatial; (b) Temporal
To improve the performance of the error concealment at the decoder, many kinds of side information are always utilized, such as error concealment model [12], important macroblock data [13] and motion vectors [14]. In this work, the perceptual weight map of the encoded video content was used as the side information. The perceptual weight map is calculated at the encoder side using a perceptual attention model which considers the three factors together: motion, skin tone and fovea. Motion is an important focus in video communication and the motion areas are always received more attention. Human face and hands are the most attractive parts of the human content in video communication. Fovea also affects human perceptual attention and people usually focus on the center region of the video scene. The perceptual weight maps of the test sequences are shown in Fig.5.

Fig.5 Perceptual weight maps: (a) Carphone sequence; (b) Foreman sequence; (c) Salesman sequence
When the error concealment employs neighboring macroblocks to reconstruct the lost macroblocks, the perceptual weight should be taken into consideration. When the concealed macroblock has a high perceptual weight, the neighboring macroblock with high perceptual weight should be given a high reconstructed weight and the one with low perceptual weight should be given a low reconstructed weight in pixel interpolation or block-match calculation, and vice versa. Let WP_mod represent the modified perceptual weight of the neighboring macroblock according to the perceptual weight of the current concealed macroblock, then it can be defined as
![]() (2)
(2)
where m denotes the index of the neighboring macroblock; WP denotes the perceptual weight of the neighboring macroblock; WP_con denotes the perceptual weight of the current concealed macroblock and Mperceptual denotes the maximum perceptual weight of the current video frame.
2.3 Spatial and temporal error concealment
In order to improve the performance of the error concealment and reduce the computation of the algorithm, some appropriate macroblocks should be picked from all the neighboring macroblocks based on the reliability weight. According to Ref.[16], the picking order using neighboring macroblocks with the same reliability weight can be defined, as shown in Fig.6.
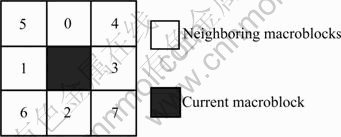
Fig.6 Order of neighboring macroblocks
2.3.1 Spatial error concealment
In order to get a satisfied performance of weighted pixel interpolation, enough appropriate neighboring macroblocks should be found to reconstruct the current lost or damaged macroblock. In the proposed error concealment, a given threshold Δintra_ralia for the total reliability weight of the neighboring macroblocks is set before decoding. For spatial error concealment, the four most overlapping sides: top, left, bottom and right neighboring macroblocks are picked as candidates. This can be written as
![]() ≥
≥![]() (3)
(3)
where Δintra_ralia equals 2.
When enough appropriate neighboring macroblocks are picked, the current lost macroblock can be reconstructed according to the perceptual weight and the distance weight. It can be defined as
 (4)
(4)
where Mcon represents the concealed data of the current lost macroblock; WD represents the distance weight of the neighboring macroblocks; and M represents the neighboring macroblocks.
2.3.2 Temporal error concealment
The motion compensation based temporal error concealment tries to “guess” the motion vectors of the current lost macroblock by some prediction schemes from available motion information of spatial or temporal neighbors [16]. If the average motion vector of the correctly received macroblocks in the current frame is smaller than a pre-defined value, e.g., 2 in H.264 joint model, the corresponding spatial positions in the reference frame will be picked. Otherwise, with the same spatial error concealment, enough appropriate neighboring macroblocks in the current frame should also be picked first, which can be written as
![]() ≥
≥![]() (5)
(5)
where Δinter_ralia equals 4.
When enough appropriate neighboring macroblocks are picked, the motion vector of each picked macroblock is used to calculate the lost macroblock from the reference frame. Corresponding to the spatial smoothness criteria, the edge distortion is measured to pick the most appropriate one. In order to improve the perceptual performance of the concealment, the perceptual weight is considered when calculating the edge distortion between the boundary of the concealed macroblock and the boundary of neighboring macroblocks in four directions, top, left, bottom and right. The edge distortion is defined as
![]() (6)
(6)
where D(m) denotes the edge distortion of the four directions; N denotes the block size; and Ynei and Ycon denote the boundary pixels in the neighboring and the concealed macroblocks, respectively. The schematic diagram of edge distortion is shown in Fig.7. When the minimum edge distortion is found, the lost macroblock will be concealed with the best performance, and the motion vector of the corresponding neighbor will be picked as the concealed macroblock’s motion vector.
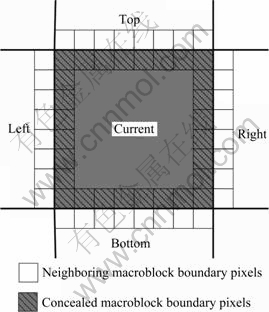
Fig.7 Edge distortion measurements for temporal error concealment
3 Simulation and discussion
3.1 Simulation setup
In this section, the performance of the proposed error concealment method (referred to henceforth as “proposed”) on the video quality was evaluated with the presence of packet loss and is compared against the method which was used in the H.264 reference software JM13.2 (“JM13.2”) [23]. In the experiments, the Carphone, Foreman and Salesman sequences at quarter common intermediate format (QCIF) (176?144) were examined and the H.264 baseline profile was employed as the video coding standard. The simulation was run using 1 000 coded pictures with I frames for every 100 pictures and each picture was encoded with 3 slices to simulate the real applications.
3.2 Results and discussion
Under different packet loss rates (PLR), 2.5%, 5.0%, 10.0%, 15.0% and 20.0%, the average frame luminance peak signal-to-noise ratio (PSNR) performances of the two methods are shown in Fig.8. It is observed that the proposed method outperforms “JM13.2” by about 0.4 dB and more. The reason is that the proposed method took the channel state information into consideration and adaptively changed the reliability of the neighboring macroblocks. Then, the lost macroblocks were concealed more accurately and the propagation of the errors was restrained more efficiently. As a result, the video quality of the sequence was improved.
The performances on subjective video quality of the two methods were compared in the following experiments. The simulation was run using different bit rates, 64, 128, 192 and 256 kb/s, respectively, and all with a packet loss of 10.0%. The subjective assessment of the video quality for the test sequences is shown in Fig.9. Assuming that the areas in the video frame with high perceptual weight are defined as attention-areas and the rest are defined as non-attention areas, the attention areas always impact the subjective video quality more obviously than the non-attention areas. The performances of the average luminance PSNR of attention-areas are shown in Fig.10. It is seen that the proposed method performs better than the “JM13.2”. This is because that the proposed method utilizes the perceptual weight of the video content to perform the interpolation in spatial error concealment and the prediction in temporal error concealment. The lost macroblocks, especially in the attention-areas, are also concealed more satisfactorily.
To further study the performance of the proposed method, the frame structural similarity (SSIM) index, which was proved to be more consistent with human eye perception than that of the traditional methods like PSNR and mean square error (MSE) [24], was employed to compare the performance of the two methods under the packet loss of 10.0% with different bit rates, 64, 128, 192 and 256 kb/s, respectively. As shown in Fig.11, the results of the proposed method are of significantly higher SSIM values compared with the “JM13.2”. Furthermore, the improvement of the performance increases as the increase of the bitrates of video bitstream. One explanation of the fact is that the “JM13.2” is based on simple smoothness between the lost macroblock and the neighboring macroblocks, and the proposed method takes the content of the video frame with side information into consideration. Hence, the details of the lost macroblocks, especially edges of the attention-areas, are concealed more reliably in the proposed error concealment method.
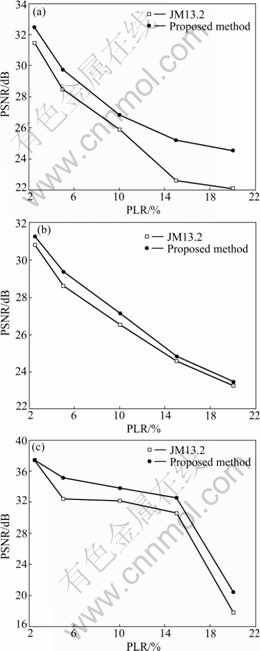
Fig.8 Average frame luminance PSNR performances of different test sequences: (a) Carphone sequence; (b) Foreman sequence; (c) Salesman sequence

Fig.9 Subjective video quality of different test sequences: (a) Carphone sequence; (b) Foreman sequence; (c) Salesman sequence
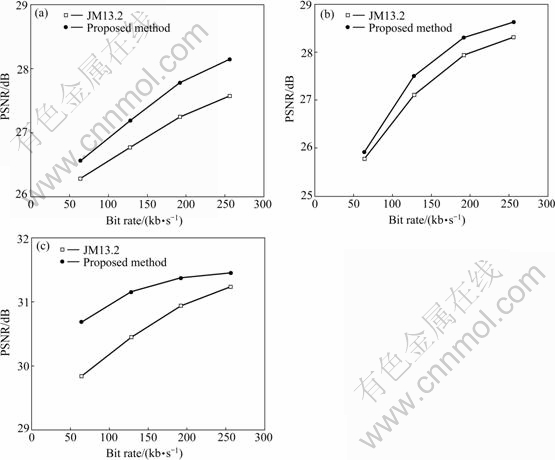
Fig.10 Attention-area luminance PSNR performance of different test sequences: (a) Carphone sequence; (b) Foreman sequence; (c) Salesman sequence
4 Conclusions
(1) A network-aware perceptual error concealment for H.264 video with side information is proposed. This method considers both the reliability weight of the reconstructed macroblocks and perceptual weight of the video content.
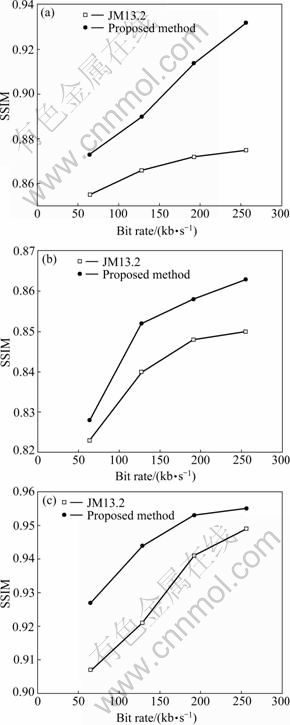
Fig.11 SSIM performance of different test sequences: (a) Carphone sequence; (b) Foreman sequence; (c) Salesman sequence
(2) The reliability weight of the reconstructed macroblocks based on the weights of the neighboring macroblocks dynamically changes according to the packet loss rate in the channel state information.
(3) Compared with the “JM13.2”, the proposed error concealment method improves the average frame luminance PSNR performance by about 0.4 dB when the video bitstreams with packet losses are transmitted.
(4) The measurement of subjective video quality also shows that the proposed method outperforms the method used in the “JM13.2”.
(5) The proposed method gains a better performance in SSIM than the method used in the “JM13.2”.
References
[1] HSU Ching-ting, CHEN Mei-juan, LIAO Wen-wei, LO Shen-yi. High-performance spatial and temporal error-concealment algorithms for block-based video coding techniques [J]. ETRI Journal, 2005, 27(1): 53-63.
[2] WANG Yao, ZHU Qin-fan. Error control and concealment for video communication―A review [J]. Proceedings of the IEEE, 1998, 86(5): 974-997.
[3] WANG Y, WENGER S, WEN J T, KATSAGGELOS A K. Error resilient video coding technologies [J]. IEEE Signal Processing Magazine, 2000, 17(4): 61-82.
[4] ZENG W J, LIU B D. Geometric-structure-based error concealment with novel application in block-based low-bit-rate coding [J]. IEEE Transactions on Circuits and Systems for Video Technology, 1999, 9(4): 648-665.
[5] CHEN T P, CHEN T. Second-generation error concealment for video transport over error-prone channels [J]. Wireless Communications and Mobile Computing, 2002, 2(6): 607-624.
[6] YE Shui-ming, LIN Xing-gang, SUN Qi-bin. Content based error detection and concealment for image transmission over wireless channel [C]// Proceedings of IEEE International Symposium on Circuits and Systems. New York: IEEE, 2003: II368-II371.
[7] CHEN Chih-ming, CHEN Chien-min, LIN Chia-wen, CHEN Yung-chang. Error-resilient video streaming over wireless networks using combined scalable coding and multiple-description coding [J]. Signal Processing: Image Communication, 2007, 22(4): 403-420.
[8] MA M Y, AU O C, GUO L W, CARY CHAN S H, WONG P H W. Error concealment for frame losses in MDC [J]. IEEE Transactions on Multimedia, 2008, 10(9): 1638-1647.
[9] TU W, STEINBACH E. Proxy-based reference picture selection for error resilient conversational video in mobile networks [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2009, 19(2): 151-164.
[10] ZHU C B, WANG Y K, HANNUKSELA M M, LI H Q. Error resilient video coding using redundant pictures [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2009, 19(1): 3-14.
[11] RANE S, AARON A, GIROD B. Systematic lossy forward error protection for error-resilient digital video broadcasting―A Wyner-Ziv coding approach [C]// Proceedings of International Conference on Image Processing. New York: IEEE, 2004: 3103-3104.
[12] ZENG Wen-jun. Adaptive spatial-temporal error concealment with embedded side information [J]. Journal of Visual Communication and Image Representation, 2005, 16(4/5): 499-511.
[13] KANG Li-wei, LEOU Jin-jang. An error resilient coding scheme for H.264/AVC video transmission based on data embedding [J]. Journal of Visual Communication and Image Representation, 2005, 16(1): 93-114.
[14] ADEDOYIN S, FERNANDO W A C, KARIM H A, HEWAGE C, KONDOZ A M. Scalable multiple description coding with side information using motion interpolation [J]. IEEE Transactions on Consumer Electronics, 2008, 54(4): 2045-2052.
[15] KUMAR S, XU L Y, MANDAL M K, PANCHANATHAN S. Error resiliency schemes in H.264/AVC standard [J]. Journal of Visual Communication and Image Representation, 2006, 17(2): 425-450.
[16] WANG Y K, HANNUKSELA M M, VARSA V, HOURUNRANTA A, GABBOUJ M. The error concealment feature in the H.26L test model [C]// IEEE International Conference on Image Processing. New York: IEEE, 2002: II729-II732.
[17] XU Yan-ling, ZHOU Yuan-hua. H.264 video communication based refined error concealment schemes [J]. IEEE Transactions on Consumer Electronics, 2004, 50(4): 1135-1141.
[18] BU Jia-jun, MO Lin-jian, SHAO Gen-fu, YANG Zhi, CHEN Chun. A novel fast error-resilient video coding scheme for H.264 [C]// Proceedings of 2006 IEEE 8th Workshop on Multimedia Signal Processing. Piscataway: IEEE, 2006: 252-257.
[19] CHUNG Y Y, CHEN L L F, ZHENG Z, CHEN X M, FAITH C. An optimized and adaptive error-resilient coding for H.264 Video [C]// TENCON 2006―2006 IEEE Region 10 Conference. Piscataway: IEEE, 2006: 414-417.
[20] ITU-T H.264, ISO/IEC 14496-10 AVC. Advanced video coding for generic audiovisual services [S]. 2009.
[21] FROSSARD P, VERSCHEURE O. AMISP: A complete content- based MPEG-2 error-resilient scheme [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2001, 11(9): 989-998.
[22] KUNG W Y, KIM C S, KUO C C J. Packet video transmission over wireless channels with adaptive channel rate allocation [J]. Journal of Visual Communication and Image Representation, 2005, 16(4/5): 475-498.
[23] H.264/AVC Reference Software [EB/OL]. 2007-08-07. http:// iphome.hhi.de/ suehring/tml/download/.
[24] WANG Z, LU L Q, BOVIK A C. Video quality assessment based on structural distortion measurement [J]. Signal Processing: Image Communication, 2003, 19(2): 121-132.
Foundation item: Project(2006C11200) supported by the Science and Technology Project of Zhejiang Province of China
Received date: 2009-12-15; Accepted date: 2010-04-01
Corresponding author: CHEN Yao-wu, PhD, Professor; Tel: +86-13605813934; E-mail: cyw@mail.bme.zju.edu.cn
(Edited by LIU Hua-sen)

