DOI: 10.11817/j.issn.1672-7207.2015.02.024
���ڸĽ�������LDAģ�͵������ݻ�����
�ν��ƣ���������������
(�Ĵ���ѧ �����ѧԺ���Ĵ� �ɶ���610065)
ժҪ��Ϊ�˽��OLDAģ���е������Ϻ������ⲻ�ܼ�ʱ���ֵ����⣬����OLDAģ�����һ�ָĽ�������LDAģ��(improved online LDA��IOLDA)����ģ��������ǿ��Ϊÿ���������ò�ͬ���Ŵ��ȣ����һ���µ�����ǿ�ȶ��������������ĵ�-����ֲ��ļ��г̶�Ϊ�ĵ����ò�ͬ��Ȩֵ���÷���������Ч���Ϳ��������ǿ�ȵ÷֣�����ģ�����������ص㣬����Jensen-Shannon���������㻰���Ĺ�����ʵ������������������ķ����ܹ���Ч�����߷���������ݻ���
�ؼ��ʣ������ݻ��������Ŵ�������ǿ�ȣ�LDAģ��
��ͼ����ţ�TP391 ���ױ�־�룺A ���±�ţ�1672-7207(2015)02-0547-07
Topic evolution analysis based on improved online LDA model
HE Jianyun, CHEN Xingshu, DU Min, JIANG Hao
(College of Computer, Sichuan University, Chengdu 610065, China)
Abstract: To sove the problem of topic mixing and new topic untimely detection in the traditional OLDA, an improved online LDA(IOLDA) model was presented based on OLDA. The different heritability for each topic was set according to the topic intensity. Furthermore, a new method was introduced to evaluate topic intensity. By calculating a weight for each document according to the concentration of the mixture distribution over topics, this method can effectively reduce the score of broad topics. Since the model is able to align topics across the epochs, topic association can be captured easily via Jensen-Shannon Divergence. The results show that the proposed method is efficient for analyzing topic evolution online.
Key words: topic evolution; topic genetic; topic intensity; LDA model
���Ż��������ռ�����̳����������ý���ѳ�Ϊ���ǻ�ȡ�ͷ�����Ϣ����Ҫƽ̨��Ҳ��Ϊ�����������Ҫ���塣�����������Ҫ�����Ǽ�ʱ���������е��ı����ݣ����з����ȵ����Ⲣ�����ݻ���������ˣ��о��ȵ�����ķ��ֺ��ݻ����ƣ������ش�����������Ӧ�ü�ֵ�����������ص����ڹ�����Ҫ�����ڻ����������(topic detection and tracking��TDT)��������TDT�������о���û����Ч�������ϵ�ʱ����Ϣ����ʱ�����Ϸ�������ķֲ�[1]������������LDA(latent dirichlet allocation)Ϊ����������ģ�͵õ��������о�[2-4]������LDA�������еĻ��⽨ģ�������ڻ����ݻ����������������ơ�����LDA��һЩ��չģ��Ҳ�������������練ӳ������ʱ����ǿ�ȱ仯��TOT(topic over time)ģ��[5]������״̬�ռ��¼�������ݺ�ǿ���ݻ���Ϣ��DTM(dynamic topic model)ģ��[6]�Լ����Ƕ�ʱ�����������ݻ���MTTM(multiscale topic tomography)ģ��[7]�ȡ�������ģ�Ͷ���Ҫȫ�ֽ�ģ�����������ߴ������ı���������OLDA(online LDA)ģ��[8]��������ʷ�ֲ���Ϊ��ǰʱ�䴰��ģ�͵����飬�������ߴ�������������OLDA�������������Ϻ�����߽�ģ����ȱ�㡣��������[9]����LDAģ���������ݻ���������Ϊ����������������ԣ��÷�����Ҫ��������ʱ��Ƭ�����������������ƶȡ������Ե�[10]��LDA��AP�����㷨��ϣ����ڷ����ȵ��������⣬����û�н����ݻ�����������[11]�����һ�����������ݻ��ھ�ģ�ͣ����õ�˼����OLDA���ƣ���������[12-13]����OLDA���л�������ݺ�ǿ�ȵ��ݻ���������Щ�о���û�п���OLDAģ�ͱ�����ȱ�㡣����������⣬�����������Ȼ���OLDA���һ�ָĽ�������LDAģ��(improved online LDA, IOLDA)��ģ��Ϊÿ�������������ǿ�ȣ�ǿ�ȵ͵�������Ŵ���Ҳ�ϵͣ���������¸�ʱ��Ƭ���⽨ģ��Ӱ�졣���ֵ�������Ч���OLDAģ�����׳��������ϵ�ȱ�㡣Ȼ�������һ���µ�����ǿ�ȼ��㷽�����÷�������Ч���Ϳ�������ĵ÷֡�
1 LDAģ����OLDAģ�ͽ���
1.1 LDAģ�͵Ļ���˼��
LDA�����ĵ�����ģ��(��ͼ1��ʾ)���������ĵ��Ƕ�����������ϵĻ�Ϸֲ�������������һ���̶��ʱ��ϵĻ�Ϸֲ�����K��ʾ������Ŀ��M��ʾ�ĵ���Ŀ��Nm��ʾ��m���ĵ��ĵ�����Ŀ���ĵ������ɹ����������£�
1) �Ӳ���Ϊ�µ�Dirichlet�ֲ���Ϊÿ�������������-���ʷֲ�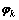 ������
������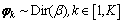 ��
��
2) �Ӳ���Ϊ����Dirichlet�ֲ���Ϊÿ���ĵ������ĵ�-����ֲ� ������
������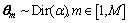 ��
��
���ĵ�m��n(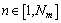 )���ʣ�
)���ʣ�
1) �Ӳ���Ϊ�Ķ���ʽ�ֲ��в���1������ ������
������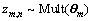 ��
��
2) �Ӳ���Ϊ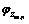 �Ķ���ʽ�ֲ��в���1�����嵥��
�Ķ���ʽ�ֲ��в���1�����嵥�� ������
������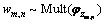 ��
��
��LDA�У��������ͦ��ǹ̶�ֵ�����û�����ָ�����ĵ��еĸ��������ǿɹ۲�����ݣ��ĵ�-����ֲ�������-���ʷֲ�����ʽ��������Ҫͨ�������Ƶ���⡣���IJ���Gibbs���������������ʽ������
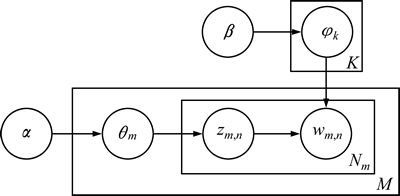
ͼ1 LDA��ͼģ�ͱ�ʾ
Fig. 1 Graphical model representation of LDA
1.2 �����Ŵ���OLDAģ��
���ı����������У����ڡ������Ŵ������������Ŵ�����ָ������г����Ժ��ȶ��ԡ��Թ̶�ʱ��Ƭ��С�����ı�������ô����ʷʱ��Ƭ�г��ֵ�����ܿ����ڵ�ǰʱ��Ƭ�м������ڣ�������һ������������������ͨ������-���ʷֲ������֡���ˣ���ʷʱ��Ƭ�еĺ������ݿ���Ϊ��ǰʱ��Ƭ����ֲ��������ṩָ����
OLDAģ������ʷʱ��Ƭ�е�����-���ʷֲ����㵱ǰʱ��Ƭ�������������ʷ��Ϣ�����ھ���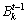 �У����ṩһ��Ȩ������
�У����ṩһ��Ȩ������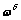 ����ƽ�������ʷʱ��Ƭ�����ݶԵ�ǰ��ģ���̵�Ӱ�죬����
����ƽ�������ʷʱ��Ƭ�����ݶԵ�ǰ��ģ���̵�Ӱ�죬����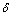 ��ʾʱ�䴰�ڵĴ�С����ˣ���OLDA�У�ʱ��Ƭt�е��� ��-���ʷֲ���������Dirichlet�ֲ���
��ʾʱ�䴰�ڵĴ�С����ˣ���OLDA�У�ʱ��Ƭt�е��� ��-���ʷֲ���������Dirichlet�ֲ���
 (1)
(1)
OLDAģ�Ͱ����ı�������ʱ���Ⱥ����ζԸ�ʱ��Ƭ�е��ĵ���ģ���ʺ����ߵĻ����ݻ����������⣬ͨ������֪ʶ�Ĵ��ݣ�OLDAģ�Ϳ����Զ��������ʱ��Ƭ���ƶϳ������⣬��ˣ����Է���ظ���1�������ǿ�Ⱥ���������ʱ��ı仯��
2 �Ľ�������LDAģ��
��OLDAģ���У���ʷʱ��Ƭ�е�����Ȩ�ئ���һ���̶�ֵ������������Ķ�̬�仯��������������ͬһʱ��Ƭ�и��������1����ͬ��Ȩ�أ�û�п��������IJ��죬�ص�ѡȡ�Ƚ����ѡ��������ù�С����ǰ�����ⲻ�ܶ��룻�������ù�����ᵼ��һЩ����ͬһ�¼����������ڹ��ʵij��ֶ���ǿ�ƶ�����һ���ر��ǵ�tʱ��Ƭ�����������ʱ��������������ij������������һ��ͬ��t-1�е����������룬���������������ѡ����⣬OLDAά��1���������µĴʱ���ÿ��ʱ��Ƭ�е��´ʶ�������ʱ��С����ջ���ʱ�̫��������ڴ���������Ҵ���ά��������Ҳ��������ʱ�����ࡣ
Ϊ����������⣬�������������һ�ָĽ�������LDAģ��(��ͼ2��ʾ)�����������¹۲죺��ÿ��ʱ��Ƭ���ֵ������У�ǿ��Խ�ߵ�����Խ��������һ��ʱ��Ƭ���ֲ��Ŵ��϶�������������෴��ǿ�Ƚϵ͵�������ܿ�������һ��ʱ��Ƭ������ͻ��Ϊ�������⡣��ˣ����Ը��ݵ�ǰʱ��Ƭ�������ǿ���������������Ŵ��ȡ�����֮���ǿ��������ǰ��ʱ��Ƭ����Ȼ�ܹ����������������������������һ��ʱ��Ƭ��ʧ������һ���µ����⡣

ͼ2 IOLDA��ͼģ�ͱ�ʾ
Fig. 2 Graphical model representation of IOLDA
ģ�ͼ���tʱ��Ƭ����ֲ�������ֻ��t-1ʱ��Ƭ��ģ�����Ӱ�죬��������ʷʱ��Ƭ�أ���һ���������ɷ���ģ�͡����ȶ���1���������� ����
���� ��|Vt|��ʾʱ��Ƭt�еĴʱ�Vt�Ĵ�С����ʱ��Ƭt������-���ʷֲ���Dirichlet�������㣺
��|Vt|��ʾʱ��Ƭt�еĴʱ�Vt�Ĵ�С����ʱ��Ƭt������-���ʷֲ���Dirichlet�������㣺
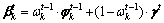 (2)
(2)
���У�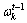 ��ʱ��Ƭt-1������k���Ŵ����ӣ�����k��ǿ��Խ�ߣ�Խ�������Ŵ���Խ�ߡ���
��ʱ��Ƭt-1������k���Ŵ����ӣ�����k��ǿ��Խ�ߣ�Խ�������Ŵ���Խ�ߡ���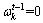 ʱ�˻�Ϊ��ͳ��LDAģ�͡�ע���ڳ�ʼʱ��Ƭt=1ʱ����LDAģ��һ�����������
ʱ�˻�Ϊ��ͳ��LDAģ�͡�ע���ڳ�ʼʱ��Ƭt=1ʱ����LDAģ��һ�����������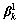 ��1�������½��г�ʼ������t��1ʱ��
��1�������½��г�ʼ������t��1ʱ��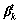 ��ʽ(2)����ó���
��ʽ(2)����ó���
��a��b�ֱ��ʾ�Ŵ����ӵ��ϡ����ޣ�����ǿ������Ϊ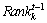 �����⣬�Ŵ������������£�
�����⣬�Ŵ������������£�
 (3)
(3)
�ڼ���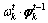 ʱ������
ʱ������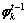 �Ǵʱ�
�Ǵʱ�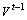 ֮�ϵķֲ�����Ҫת��Ϊ��ǰ�ʱ�Vt�ϵķֲ���Ϊ����ʱ���������������ڴ����Ӻ�����ʱ�����ӵ����⣬��ģ��ֻ������ʱ��Ƭ�Ĵʱ��Ľ�����Χ�ڴ��ݲ�������ʱ���ݵĵ��ʷֲ�֮��
֮�ϵķֲ�����Ҫת��Ϊ��ǰ�ʱ�Vt�ϵķֲ���Ϊ����ʱ���������������ڴ����Ӻ�����ʱ�����ӵ����⣬��ģ��ֻ������ʱ��Ƭ�Ĵʱ��Ľ�����Χ�ڴ��ݲ�������ʱ���ݵĵ��ʷֲ�֮�� �����ڵ�����ʧ����ʧ�ķֲ�ֵ
�����ڵ�����ʧ����ʧ�ķֲ�ֵ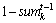 ƽ���������ʱ��Ƭ���³��ֵĵ��ʡ�Ϊ�˱�ʾ�ļ�࣬ʽ(2)��ֱ��ʹ����Ϊ��t-1�̳е�����-���ʷֲ���
ƽ���������ʱ��Ƭ���³��ֵĵ��ʡ�Ϊ�˱�ʾ�ļ�࣬ʽ(2)��ֱ��ʹ����Ϊ��t-1�̳е�����-���ʷֲ���
�������ϼ�����ĸ�����֮��Ϊ1����LDAģ���У�������һ��ȡ����ֵ0.1����ʱ����ȡ�ý��ŵ����⽨ģЧ����Ϊ���ģ�͵�ȷ�ԣ����������µ���������ƽ����������ʹ��ӽ���ֵ�����������ά��ֵ�������ų��ԷŴ�����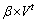 ��ʹ��ά�ľ�ֵ���ڳ�����(����ȡ0.1)��������ʽ���£�
��ʹ��ά�ľ�ֵ���ڳ�����(����ȡ0.1)��������ʽ���£�
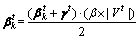 (4)
(4)
���ϣ�IOLDA�㷨�ľ���������¡�
�㷨1��IOLDA
���룺������
t=1
loop
��ȡ�ĵ�����Dt����Ӧ�ʱ�ΪVt
if t=1 then
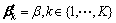
else
��������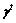 ��
��
for k=1 to K
�������Ŵ���
����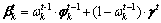
�� �����
�����
end for
end if
[ ]
]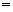 Gibbs Sampling(
Gibbs Sampling( ,,
,, )
)
������������
t=t+1
end loop
3 �����ݻ�����
�����ݻ���Ϊǿ���ݻ��������ݻ�[1]������ǿ���ݻ���Ҫ����һ�������ڸ�ʱ��Ƭ�е�ǿ�ȣ����IJ���һ���µ�����ǿ�ȼ��㷽�����������ݻ��ϣ�����IOLDAģ�;������������ص㣬����Jensen-Shannon��������������ʱ��Ƭͬһ�������������ԣ���������ķ�չ���ơ�
3.1 ����ǿ�ȶ���
����ij��ȷ��������ĵ�������һ�������������������нϸ߸��ʷֲ�ֵ���������������Ϸֲ�ֵ�ܵͻ�û�зֲ����෴����1���ĵ��ڸ��������ϵķֲ��Ƚ�ƽ��������ĵ�̸�۵����ݱȽϿ�����û����ȷ�����������ĸ����ĵ��ķֲ����Ϊ�����ĵ�����1��Ȩֵ��������ȷ����������ĵ��÷ֽϸߣ����ݹ��ڿ������ĵ��÷ֽϵ͡�
�����غ����ĵ�-����ֲ��ļ��г̶ȣ������ؼ����ĵ�Ȩ�أ�
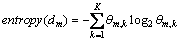 (5)
(5)
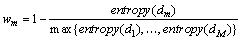 (6)
(6)
ʽ�У� ��ʾ�ĵ�m�ڵ�k�������Ϸֲ��Ĺ���ֵ�����ĵ�ֻ����1������ʱ��Ȩ��ȡ���ֵ1�����ĵ���K�������Ͼ��ȷֲ�ʱ��Ȩ�شﵽ��Сֵ0����ʱ��Ϊ�ĵ��Ը������ⶼ�����ṩ֧�֡��õ������ĵ�Ȩ�غ�����ǿ�ȸ���ʽ(7)���㣺
��ʾ�ĵ�m�ڵ�k�������Ϸֲ��Ĺ���ֵ�����ĵ�ֻ����1������ʱ��Ȩ��ȡ���ֵ1�����ĵ���K�������Ͼ��ȷֲ�ʱ��Ȩ�شﵽ��Сֵ0����ʱ��Ϊ�ĵ��Ը������ⶼ�����ṩ֧�֡��õ������ĵ�Ȩ�غ�����ǿ�ȸ���ʽ(7)���㣺
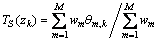 (7)
(7)
3.2 ���������Զ���
���������Լ���һ�����KL����(Kullback-Leibler divergence)[14]��������2�������ڴʼ��Ϸֲ��IJ����ԡ���������ʱ��Ƭ�б��Ϊk��2������ֲ��� ��KL���붨�����£�
��KL���붨�����£�
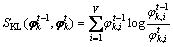 (8)
(8)
KL�����Dz��ԳƵģ���2������ľ���Ӧ���ǶԳƵĸ�����IJ���Jensen-Shannon�������2������ֲ��IJ����ԡ�Jensen-Shannon������KL���붨�壬��������ֲ�����JS����Ϊ

 (9)
(9)
����ʱ��Ҫ��2������-���ʷֲ�ӳ�䵽ͬһ���ʼ��ϡ�ʵ��������1����ֵ�ţ���JS����С�ڦţ���ǰ������ǰһ�����������������Ϊ���ⷢ���˸ı䡣
4 ʵ�鼰�������
���IJ��ô����������ġ�������̸�����ץȡ�����������ⷢ�����ݻ�������ʵ�����ݼ�����2013-06-19��2013-07-08��67 832ƪ���ӣ���1 d��Ϊʱ��Ƭ�������ݼ���
Ԥ������ֻ�����ĵ��е����ʺͶ��ʣ���ɸѡTF-IDF�÷���ߵ�ǰ75%�ĵ�������ά������ʵ��������������ĿK=100���Ŵ��ȵ��ϡ�����ȡ����ֵ0.6��0.1�����ƶ���ֵ��=0.35��
4.1 ����IOLDAģ�͵����ⷢ��
OLDAģ�͵�����߽�Ƚ�ģ���������������IJ�������ʧ���������������׳��ֻ�϶��������1��ʾΪ����ͻ������Ƚ�IOLDA��OLDA��������Ч����
��1 OLDA��IOLDA����������
Table 1 Topic discovering results of OLDA and IOLDA
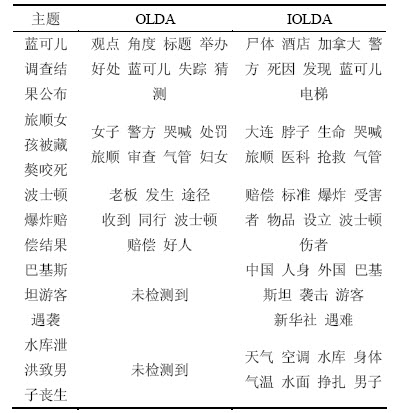
�ӱ�1���Կ�����OLDA��2������δ��ʱ���֣�����3������Ҳ���ֲ�ͬ�̶ȵĻ�����������⡰Ů��������ҧ����������Ϊ���������������顱�ȴʵĹ��ֶ��롰��������ɫ����ҵ������������һ�𡣶���IOLDAģ���У�����������������Ŵ��Ȼᱻ���ͣ��´ʻ��Ȩ����Ծ�һЩ����������������ǰһ��ʱ��Ƭ����������(һ���ڱ�ʱ��Ƭ����)���룬���������ǿ�ƻ�϶��������
ʵ���һ���Ƚ���IOLDAģ�ͺ�OLDAģ�͵������(Perplexity)[2]������Ⱥ�������ģ�Ͷ���δ�۲����ݵ�Ԥ�������������ԽС��ģ��Ԥ������Խǿ��ģ�͵��ƹ���Խ�ߡ�����ȶ������£�
 (10)
(10)
���У�DtestΪ���Լ���wdΪ�ĵ�d�еĿɹ۲ⵥ�����У�NdΪ�ĵ�d�ĵ�����Ŀ��ʵ����ÿ��ʱ��Ƭ���ѡ��10%���ĵ���Ϊ���Լ�������90%�ĵ���Ϊѵ����������õ���OLDA��IOLDA���������ͼ3��ʾ��

ͼ3 OLDA��IOLDAģ�͵�����ȶԱ�
Fig. 3 Comparisons of perplexities of OLDA and IOLDA
��ͼ3���Կ�����IOLDAģ�͵�����ȸ�С��ģ�͵��ƹ��Ը��á�
4.2 ����ǿ�ȶ������ݻ�����
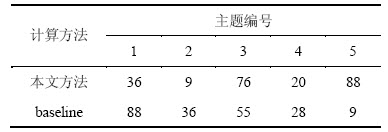
������[1��11��15]�еķ�����Ϊbaseline�������÷�����������ͬһʱ��Ƭ���ĵ��зֲ�ֵ��ƽ��ֵ����������ǿ�ȡ���2��ʾΪʹ��2��ǿ�ȼ��㷽���õ���6��20��ǰ5���������š��������Ŷ�Ӧ����������3��ʾ��
�Ѳ������Կ�������������¼�����������������⡣���С��߿���ء�����������ء��͡�������ء����ⶼ���ڿ������⡣��������һ���ڸ���ʱ��Ƭ������֣���Ӧ��Ϊ��ע�ص㡣�������ڿ���������ĵ���������û����ȷ�������������ԣ������ĵ������������ϵļ��г̶ȸ����ĵ�1��Ȩ�أ�������Ч���Ϳ�������ĵ÷֡����ķ��������ǰ5���������У�ֻ��1��������������������baseline����������3���������⣬��������ǰ��
��2 ǰ5����������
Table 2 Numbers of the top 5 topics
��3 ��������������
Table 3 Keywords of the topics

��������ǿ�ȵ÷ֺɽ�һ���۲���������ǿ�ȷ�չ���ơ�ͼ4��ʾΪ����ǿ�ȵ��ݻ�����ͼ4���Կ����������д��ȵ�������С�Ѹ�ٳ�Ϊ�ȵ㲢�������������ص㣺�¼�����������ʱ���ھͳ�Ϊһ���ȵ㣬��֮��2~3 d��������������Ҳ�и�������������¼��Ľ��г��ڴ��ڣ����硰�⾵���¼�����
4.3 ���������ݻ�����
ͬһ�������ڷ�չ�����в��ص�������仯�����嵽����ģ���о��������ڴ����ϵĸ��ʷֲ��ᷢ���仯����4��ʾΪ����ʮ���䡱����������ʱ��Ƭ�и��ʷֲ���ߵ�10������ʡ��ӱ�4���Կ����������ʼʱ����������ƽ̫���ڿΣ������Ǻ��켼�������ۣ��������ʮ���ص��档
ͨ��Jensen-Shannon������Լ�����ĸı䡣�ԡ��ͻ�˹̹�ο���Ϯ������Ϊ������������2013-06-23���֣�2013-06-29������ͼ5��ʾΪ��2013-06-23��ʼ����ʱ��Ƭ������������������ͼ5���Կ�����2013-06-23��2013-06-29�������������������ֵ(���߱�ʾ)��˵����������2 d�з����˸ı䡣

ͼ4 ����ǿ�ȵ��ݻ�
Fig. 4 Topic intensity evolution
��4 ����ʮ���䡱����������ݻ�
Table 4 Content evolution for topic ��launch of Shenzhou-10��


ͼ5 ����仯�ļ��
Fig. 5 Topic change detection
5 ����
1) ����OLDAģ�������һ�ָĽ�������LDAģ��(IOLDA)��ģ��������ǿ�Ⱦ���ÿ��������Ŵ��ȣ�������OLDA���׳��������Ϻ������ⲻ����ȱ�ݡ���������̳�����ϵ�ʵ��������������ģ�;��и��͵�����Ⱥ��ŵ�������Ч����
2) ������һ���µ�����ǿ�ȼ��㷽�����÷��������ĵ�-����ֲ��ļ��г̶�Ϊ�ĵ����ò�ͬ��Ȩֵ��������Ч���Ϳ��������ǿ�ȵ÷֡�
3) ����ģ�;������������ص㣬���Է���ط��������ǿ���ݻ��������ݻ�������������С�Ѹ�ٳ�Ϊ�ȵ㲢�������������ص㡣
�ο����ף�
[1] ����, �. ����LDA�����ݻ��о���������[J]. ������Ϣѧ��, 2010, 24(6): 43-49, 68.
SHAN Bin, LI Fang. A survey of topic evolution based on LDA[J]. Journal of Chinese Information Processing, 2010, 24(6): 43-49, 68.
[2] Blei D M, Ng A Y, Jordan M I. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003(3): 993-1022.
[3] ���, �����. ��Ȼ���Դ���������ģ�͵ķ�չ[J]. �����ѧ��, 2011, 34(8): 1423-1436.
XU Ge, WANG Houfeng. The development of topic models in natural language processing[J]. Chinese Journal of Computers, 2011, 34(8): 1423-1436.
[4] ������, ����ϼ. ����LDA��������������̽�⼼������[J]. �ִ�ͼ���鱨����, 2012(12): 58-65.
FAN Yunman, MA Jianxia. Review on the LDA-based techniques detection for the field emerging topic[J]. New Technology of Library and Information Service, 2012(12): 58-65.
[5] Wang X, McCallum A. Topics over time: A non-Markov continuous-time model of topical trends[C]// Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Philadelphia, USA, 2006: 424-433.
[6] Blei D M, Lafferty J D. Dynamic topic models[C]//Proceedings of the 23rd International Conference on Machine Learning. Pittsburgh, Pennsylvania, USA, 2006: 113-120.
[7] Nallapati R M, Ditmore S, Lafferty J D, et al. Multiscale topic tomography[C]//Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Jose, California, USA, 2007: 520-529.
[8] AlSumait L, Barbar�� D, Domeniconi C. On-Line LDA: Adaptive topic models for mining text streams with applications to topic detection and tracking[C]// Proceedings of the 8th IEEE International Conference on Data Mining. Pisa, Italy, 2008: 3-12.
[9] ������, �. ����LDA��������Ļ����ݻ�[J]. �Ϻ���ͨ��ѧѧ��, 2010, 44(11): 1496-1500.
CHU Keming, LI Fang. Topic evolution based on LDA and topic association[J]. Journal of Shanghai Jiaotong University, 2010, 44(11): 1496-1500.
[10] ������, ������, ������, ��. �������������Ӧ�����������ȵ㷢�ַ����������Ƽ�ϵͳ[J]. ����ѧ��, 2010, 38(11): 2620-2624.
WU Yonghui, WANG Xiaolong, DING Yuxin, et al. Adaptive on-line web topic detection method for web news recommendation system[J]. Acta Electronica Sinica, 2010, 38(11): 2620-2624.
[11] ��, �ܱ�, ����, ��. һ�ֻ���LDA �����������ݻ��ھ�ģ��[J]. �������ѧ, 2010, 37(11): 156-159, 193.
CUI Kai, ZHOU Bin, JIA Yan, et al. LDA-based model for online topic evolution mining[J]. Computer Science, 2010, 37(11): 156-159, 193.
[12] ������, ����, ��ά��. ����������һ�ֻ���OLDA���������ݻ�����[J]. �����Ƽ���ѧѧ��, 2012, 34(1): 150-154.
HU Yanli, BAI Liang, ZHANG Weiming. OLDA-based method for online topic evolution in network public opinion analysis[J]. Journal of National University of Defense Technology, 2012, 34(1): 150-154.
[13] ������, ����, ��ά��. һ�ֻ����ݻ���ģ���������[J]. �Զ���ѧ��, 2012, 38(10): 1690-1697.
HU Yanli, BAI Liang, ZHANG Weiming. Modeling and analyzing topic evolution[J]. Acta Automatica Sinica, 2012, 38(10): 1690-1697.
[14] �ڳ���. ͳ����Ȼ���Դ���[M]. ����: �廪��ѧ������, 2008: 22-22.
ZONG Chengqing. Statistical natural language processing[M]. Beijing: Tsinghua University Press, 2008: 22-22.
[15] Griffiths T L, Steyvers M. Finding scientific topics[J]. Proceedings of the National Academy of Sciences of the United States of America, 2004, 101: 5228�C5235.
(�༭ �Կ�)
�ո����ڣ�2014-03-16�������ڣ�2014-07-02
������Ŀ(Foundation item)�����ҿƼ�֧�żƻ���Ŀ(2012BAH18B05)��������Ȼ��ѧ����������Ŀ(61272447)(Project (2012BAH18B05) supported by the National Key Technology R&D Program of China; Project (61272447) supported by the National Natural Science Foundation of China)
ͨ�����ߣ�������ʿ�����ڣ�������Ϣ��ȫ���Ƽ�����о���E-mail��chenxsh@scu.edu.cn

