基于BPSO与神经网络的实时P2P协议识别算法
谭骏,陈兴蜀,杜敏
(四川大学 计算机学院,四川 成都,610065)
摘要:针对互联网中P2P协议以及加密协议无法使用传统方法进行识别的问题,提出一种新的基于会话流统计特征的网络协议识别算法。采用二进制粒子群算法(BPSO)定量选出最能体现不同协议区别的特征子集;并针对BP(Back Propagation)神经网络结构难以确定、易陷入局部极小值等缺陷进行分析,使用粒子群算法对BP神经网络进行优化以提高识别率。实验结果表明:该方法能够有效地从多种网络特征属性中选出最能体现不同协议区别的特征子集,且对于基于UDP协议的网络应用也有较高识别率,经优化后的BP神经网络具有更高识别率。该算法对常见的P2P协议平均识别率达到96%,且能够实时地对网络协议进行识别。
关键词:粒子群算法;神经网络;统计特征;流量识别;实时性
中图分类号:TP393.08 文献标志码:A 文章编号:1672-7207(2012)06-2190-08
A novel real-time p2p identification algorithm based on BPSO and neural networks
TAN Jun, CHEN Xing-shu, DU Min
(School of Computer Science, Sichuan University, Chengdu 610065, China)
Abstract: Due to the unclassifiable problem of P2P protocol and encryption protocol by traditional approach in network management, a novel approach considering internet traffic flow was proposed to classify network applications especially P2P applications based on binary particle swarm optimization (BPSO) and optimized back-propagation (BP) neural network. BPSO was used to select the best feature subset which can mostly reflect the difference among different network applications. And BP neural network was optimized by PSO algorithm. The experimental results demonstrate that the proposed approach has a high recognition rate of network applications using either TCP or UDP protocol, and the identification rate is improved to 96% with the use of BPSO and optimized BP neural network. Moreover, the proposed algorithm can be used for real-time identification.
Key words: particle swarm optimization; neural networks; statistical characteristic; traffic identification; real time
近几年来,以P2P技术为主的互联网新兴应用得到快速发展与广泛应用,人们利用互联网进行信息交流变得更加容易、频繁。P2P技术在文件下载、流媒体、协同计算等方面发挥重要的作用,已有大量基于P2P技术的应用软件,如BitTorrent,eDonkey,PPStream和迅雷等。P2P技术在给人们带来便利的同时,也带来较大安全隐患:一方面,P2P应用占用大量网络带宽,容易造成网络拥塞,降低其它业务的性能。据统计,P2P业务的带宽占用比率为40%~60%,极端情况下会占用80%~90%[1];另一方面,P2P开放式的结构使得病毒、木马加速传播,色情、暴力等不健康内容无限制分发,且容易造成用户信息泄露等安全隐患[2]。因此,对P2P流量进行有效的识别与控制就显得非常必要,这对网络的管理与审计、安全防护和流量控制等方面都具有非常重要的意义。总体而言,P2P应用的识别技术主要分为基于端口、基于应用层签名以及基于流量统计特征这3大类。早期的P2P应用采用默认端口号进行通信,Sen等[3]最早提出基于端口号的P2P协议识别技术,但随着端口隧道和动态端口技术的出现,此类方法的识别准确性受到影响。为解决这个问题,对典型的P2P应用如FastTrack,DirectConnect和BitTorrent进行分析,发现多数P2P应用层用户数据中具有独特的数据比特串,在此基础上提出基于应用层签名的协议识别方法[4],该方法具有精确性与实时性等优点。但由于P2P协议不断升级,同时,有的协议采用加密传输方式,使得基于应用层签名的识别方法不再有效。越来越多的研究者开始使用基于流量统计特征以及机器学习的方法对P2P协议进行识别。Karagiannis等[5]首先提出基于统计特征的协议识别方法,该方法具有普适性、可扩展性等特点。随后出现大量基于机器学习理论对网络协议进行识别的方法[6-8],这些方法在对1个或多个网络流量的属性进行统计的基础上对网络协议进行分类。目前主要采用的分类方法有支持向量机[9-10]、决策树[11]以及基于神经网络的识别方法[12-13]。现有这些研究主要存在以下几点不足之处:一是当前的研究主要集中在对网络中的TCP流量进行识别,而UDP协议由于其具有无连接状态等特性,使其难以被识别[14];二是基于流量统计特征的协议识别方法需要获取多种网络属性,但是目前在选择网络协议的特征进行后续分类时,只根据对协议特征的定性分析,从多种特征中选择出1种或几种特征作为分类的依据,往往会漏掉一些对分类重要的特征;三是当前的基于统计特征的识别方法需要对整个会话流中的数据进行获取,然后进行后续分类,这种方式虽然对于离线分类非常有用,但是,对于在线分类却不具有适用性,缺乏实时性。为此,本文作者提出一种新的基于二进制粒子群算法(BPSO)与改进的神经网络算法的实时P2P协议识别算法:对TCP与UDP会话流分别进行定义;使用BPSO算法从多种特征属性中选择出最能够区分不同网络协议的特征子集;使用普通PSO算法对神经网络初始权值与阈值进行优化;通过对TCP与UDP会话流持续时间进行测量,确定最优的会话流持续时间,使得该方法能够适用于实时在线流量识别。
1 基本概念与整体流程
1.1 基本概念与定义
网络中的单个数据包是网络应用在传输过程中的表现形式,但单个数据包携带的信息量太少,不足以对网络应用的分类产生较大的作用。因此,将单个数据包根据相应的规则与和它有联系的其他数据包结合形成会话流,并以会话流的形式对该数据包进行识别。
定义1 五元组。包括源IP地址、源端口号、目的IP地址、目的端口号与传输层协议(TCP/UDP)。
定义2 TCP会话流。设c为一条TCP会话流,则c中的所有数据包拥有相同的五元组,传输协议为TCP。c中的数据包为从该TCP连接的SYN包发起之后,第1个FIN包发送之前所有数据包,或c中的数据包为在t时间内五元组相同的所有数据包。
定义3 UDP会话流。设c为1条UDP会话流,则c中的所有数据包拥有相同的五元组,传输协议为UDP。c中的数据包为在t时间内五元组相同的所有数据包。
TCP与UDP会话流统称为会话流,由于TCP会话流的持续时间可能很长,从而影响网络协议识别的实时性,因此,对其会话流设置1个超时时间以保证实时性。
定义4 会话流属性特征向量。设r(c)为1条会话流c的某个属性特征,则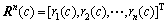 为会话流c的n个属性的特征向量。
为会话流c的n个属性的特征向量。
Auld等[12]中使用246种基于流特征作为分类的标准,其中大部分特征都是针对TCP协议的,不能用于识别UDP协议。而目前大量的网络应用,尤其是基于P2P技术的应用广泛使用UDP协议,因此对UDP协议的识别也很重要,本文对现有研究中使用的特征属性进行归纳,总结出50种针对TCP与UDP会话流进行识别的特征属性,部分特征属性如表1所示。
表1 部分会话流特征
Table 1 Partial features of session

1.2 整体流程
本文提出的训练与测试过程如图1所示。
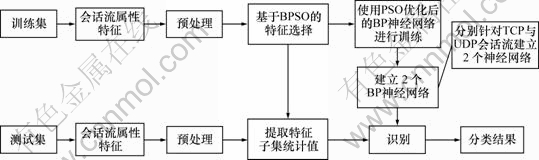
图1 系统整体流程图
Fig.1 System flow chart
首先,对网络中的数据包进行获取,并按照流的定义将数据包重组为会话流样本集,将该样本集分为训练集与测试集。根据表1中所列出的属性对会话流中的特征进行统计并使用归一化进行预处理。其次,由于所获取的数据流的特征较多,但并不是每一种特征都能够对协议的分类有效,因此需要对其进行选择,以找出最能够体现不同协议差别的特征子集。此处根据类别可分性判据,使用BPSO对特征进行选择,获得最优特征子集。最后,使用优化后的BP神经网络对训练集进行训练,根据训练结果得到相应的神经网络结构,并将该神经网络用于对测试集中的样本进行识别,得到最终的识别率。
由于需要同时对TCP与UDP会话流进行识别,而这2种协议在传输模式上存在较大的区别,因此本算法同时使用2个神经网络对网络流量进行训练与识别。通过训练分别得到2个BP神经网络,针对待测试会话流,首先判断其传输层协议类型,然后,使用对应的神经网络对其进行分类。
2 基于BPSO的特征选择
2.1 会话流属性特征选择
定义5 会话流属性特征选择。设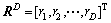 为会话流属性特征向量,属性特征选择是指从向量RD中选择出1个子集
为会话流属性特征向量,属性特征选择是指从向量RD中选择出1个子集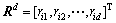 ,d≤D,使得不同协议类别之间的可分性判据函数取得最大值。
,d≤D,使得不同协议类别之间的可分性判据函数取得最大值。
设D维特征向量RD的特征子集有ND个,则:
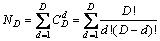 (1)
(1)
由式(1)可知:若采用遍历的方式来确定最优子集则需要判断ND次,若D较大,则时间复杂度将很大,使得难以得到计算结果。因此,需要采用合适的方式对特征子集进行选择,使得在不影响准确率的情况下极大地提高计算性能。
为对不同的类别进行分类,需要定义相应的判定准则。在分类识别中,不同类别能够被区分是因为它们所属类别在特征空间中处于不同的区域,且特征空间中相同类别的样本距离越近,不同类别的样本距离越远,类别的可分性就越好,称为类别可分性判据。此处设类别可分性判据为:
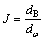 (2)
(2)
其中:dB表示不同类别的样本之间的距离和;dω表示同一类别中样本的距离之和。当dB越大而dω越小,即可分性判据J越大时,则越能够更好地对不同类别的样本进行分类。
在D维特征空间中,令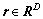 。设
。设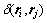 为特征空间中2个样本点之间的距离,特征空间中的N个样本{rl},l=1,2,…,N分别属于c类,第i类样本模式为:
为特征空间中2个样本点之间的距离,特征空间中的N个样本{rl},l=1,2,…,N分别属于c类,第i类样本模式为:
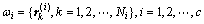 (3)
(3)
令m(i)和m分别为第i类样本和所有样本的均值向量,则有:
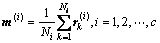 (4)
(4)
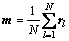 (5)
(5)
第i类样本的类内距离之和dω与不同类别间的样本距离之和dB分别为
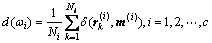 (6)
(6)
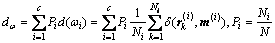 (7)
(7)
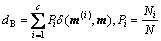 (8)
(8)
则有:
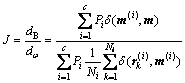 (9)
(9)
本文以式(9)作为类别的可分性判据,同时,距离函数δ设为欧氏距离。
2.2 离散二进制粒子群算法(BPSO)
粒子群算法(PSO)最初由Kennedy与Eberhart [15] 提出,是1种进化计算技术,其基本概念源于对鸟类觅食行为的研究。系统初始化为1组随机解,通过迭代搜寻最优值。设在α维搜索空间中,由β个粒子组成的种群为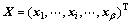 ,其中第i个粒子的位置为
,其中第i个粒子的位置为 ,其飞行速度为
,其飞行速度为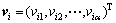 ,该粒子迄今为止得到的最优解为
,该粒子迄今为止得到的最优解为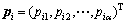 ,整个种群得到的最优解为
,整个种群得到的最优解为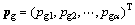 。其迭代过程为:
。其迭代过程为:
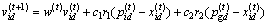 (10)
(10)
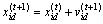 (11)
(11)
其中:i=1,2,…,m表示种群规模;d=1,2,…,α表示粒子群算法解的搜索空间;t为当前进化代数;r1与r2为[0,1]之间的随机数;c1与c2为正常数;w为非负数,称为惯性权重,它描述该粒子上一代的速度对当前代速度的影响程度。
为使PSO算法能够用于组合优化领域,Eberhart等[16]又提出PSO算法的离散二进制版本(即BPSO)。BPSO采用二进制编码形式,将每一维的xid,pid,pgd限制为0或者1,而速度vid不做这种限制,用速度的Sigmoid函数表示位置状态改变的可能性,BPSO模型中,速度更新方式如式(10)所示,位置更新方式如下:
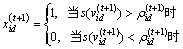 (12)
(12)
其中Sigmoid型函数:
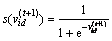 (13)
(13)
其中: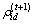 是随机向量,其分量为区间(0,1)中的随机数。
是随机向量,其分量为区间(0,1)中的随机数。
2.2.1 适应度函数
特征选择的目的是选出最优的特征组合,从而使其分类的准确率达到最高。为更好地对不同类别的样本进行分类,需要使类别的可分性判据最大,适应度函数可设为:
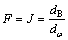 (14)
(14)
2.2.2 编码与解码
在BPSO中,需要将问题的每1个解编码为1个基因链。在进行特征选择时,1个特征可能被选中也可能不被选中。为从1个D维特征中选出d个子特征,因此使用一个D位的二进制串来表示,其中数字1表示该特征被选中,数字0表示该特征未被选中。本文统计到的特征属性有50种,因此其基因串的长度为50。最后通过得到的个体中为1的二进制位所对应的会话流属性来决定选取哪些属性作为后续分类器的设计标准。
2.2.3 基因突变规则
为了改善粒子群优化算法的全局搜索能力以及防止出现早熟现象,在粒子位置更新过程中引入变异算子。粒子的位置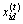 在第(t+1)次迭代更新之后进入基因突变阶段,对适应度值较低的粒子以γt+1的概率对基因串进行反转。突变概率γt+1满足下式:
在第(t+1)次迭代更新之后进入基因突变阶段,对适应度值较低的粒子以γt+1的概率对基因串进行反转。突变概率γt+1满足下式:
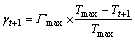 (15)
(15)
其中:Γmax为最大突变概率;Tmax为最大迭代次数,算法初始时人为设定。Tt+1为本次时迭代的代数。由式(5)可知:随着迭代次数的增加突变概率γt+1会动态地线性降低。这就保证了算法在迭代前期能够扩大粒子的搜索范围以防止进入局部最优,而在迭代后期能够快速收敛以提高算法的性能。
3 基于PSO优化的BP神经网络
3.1 BP神经网络
人工神经网络是由大量简单的处理单元连接组成的非线性系统,由于其具有良好的非线性映射能力、自学习能力以及泛化性,使之在模式识别、智能控制等领域得到成功应用。而BP神经网络是应用最广泛的神经网络之一。其学习过程分为2部分:前向传播与反射传播[17]。前向传播让输入信息在相应权值、阈值与激活函数的作用下传递到输出层,当输出结果与期望值的误差大于指定精度时,将误差进行反向传播,逐级修正各层的权值与阈值。如此反复迭代,最后使误差达到指定精度。1个典型的3层BP神经网络结构如图2所示。
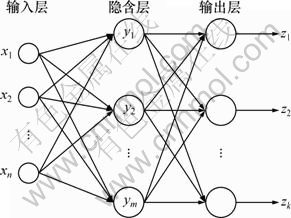
图2 3层BP神经网络结构
Fig.2 Three-floor structure typical BP neural network
设3层神经网络有A个输入,C个输出,隐层神经元个数为B。输入节点xa(a=1,2,…,A)与隐层节点yb(b=1,2,…,B)之间的连接权值为ωba,隐层节点yb与输出节点zc(c=1,2,…,C)之间的连接权值为vcb。隐层节点yb的阈值为θb,输出节点zc的阈值为δc。设隐层神经元的激活函数为f(x),输出层神经元的激活函数为p(x)。则隐层神经元yb与输出节点zc为:
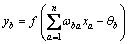 (16)
(16)
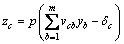 (17)
(17)
设有H个样本,第h个样本的第c个输出节点的期望值为thc,通过神经网络前向传播的实际输出值为zhc,则输出节点的均方误差为:
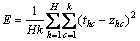 (18)
(18)
使用3层神经网络进行训练与分类,输入层的数据为会话流的特征向量,其个数为经过BPSO特征选择之后的特征子集的特征数,输出层为该样本流量所对应的类别,每一个输出神经元取值为0或1,若为1表示此会话流样本属性该类别。在隐层神经元中使用的激活函数为Sigmoid函数,输出神经元中使用的激活函数为线性传递函数。
3.2 基于粒子群优化的BP神经网络
基本的BP神经网络是基于梯度的最速下降法,以误差平方为目标函数,所以存在以下几个方面的缺陷:训练易陷入局部极小值、学习过程收敛速度慢、网络结构难以确定等[18]。PSO算法收敛速度快,尤其适合全局搜索,本文作者结合PSO与BP算法,通过PSO的特性弥补BP算法的缺陷,提出基于粒子群优化的BP神经网络,使用PSO算法对网络的初始权值与阈值进行优化,首先使用PSO算法对网络初始权值与阈值进行优化,然后以该优化后的权值与阈值作为初始值,使用基本的最速下降法进行训练,得到最终的神经网络。
为对神经网络的初始权值与阈值进行优化,对权值与阈值的编码方式如下所示:
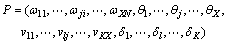 (19)
(19)
其中:N为输入结点个数;X为隐层神经元个数;K为输出结点个数。
在使用PSO算法对神经网络初始权值与阈值进行优化时,适应度值由式(18)中均方误差决定。均方误差越小,神经网络的性能则越优。适应度函数定义如下:
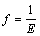 (20)
(20)
其中:E为均方误差。
基于PSO优化的BP神经网络算法如下所示。
算法1 PSO优化BP神经网络

设粒子群的种群个数为20,在使用粒子群进行迭代时,若训练精度小于1×10-2或迭代次数大于20代,则停止粒子群算法的迭代,并以此时得到的最优权值与阈值作为初始值进行后续基于最速下降法的迭代 过程。
4 实验设计与结果分析
4.1 数据采集与实验设计
本文针对目前主流的网络应用进行识别,选择以下6类P2P与非P2P应用进行测试:HTTP,BitTorrent,eDonkey,PPTV,PPStream和Skype。其中:HTTP属于传统的网络应用;BitTorrent与eDonkey属于P2P技术中的文件共享类应用;PPTV与PPStream属于P2P技术中的流媒体应用;Skype属于P2P技术中的即时通信应用。数据包采集方式如图3所示。
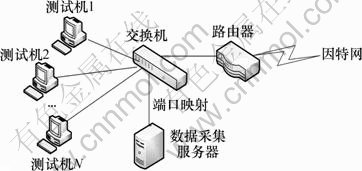
图3 数据包采集环境
Fig.3 Data collection environment
在1次采集过程中,所有测试机在同一时间段只运行前述6类应用中的某1种网络应用,如只运行BitTorrent,使得此时所获取的数据仅包含该类别的样本,因此样本具有较高的纯度,同时使用端口映射的方式将N个测试机上的数据包镜像到数据采集服务器,通过该方法获取1×104条某1类别网络的会话流。按照此步骤分别获取前述6种网络应用的数据包。对每一应用中的1×104条会话流,将其平均分为训练集与测试集。对训练集中的样本首先进行特征选择,然后使用选择出的特征子集使用算法1对神经网络进行训练。将训练得到的神经网络对测试集中的样本进行测试。
对于前述6种网络应用,有的应用既包含TCP协议,又包含UDP协议,如eDonkey与PPStream等,由于本方法对TCP与UDP协议的流量分别进行识别,因此对该类型流量的识别率计算方式如下:设该类流量中TCP数据包的流量所占比例为ptcp;UDP数据包流量所占比例为pudp;对TCP会话流的识别率为rtcp;对UDP会话流的识别率为rudp。则对该类型流量的整体识别率为:
rt=ptcp×rtcp+pudp×rudp (21)
其中:ptcp+pudp=1。
4.2 特征子集的确定
在对特征子集进行选择时,采用类别可分性判据作为标准,以BPSO算法对其进行确定。而粒子群算法是一种迭代算法,不同的迭代次数可能产生不同的特征子集。针对不同的BPSO迭代次数对应的可分离性判据进行测试,并选择出最优的特征子集作为后续分类的依据。又由于TCP与UDP协议在传输方式上存在不同之处,因此将TCP与UDP会话流的特征分别进行选择,如图4所示。
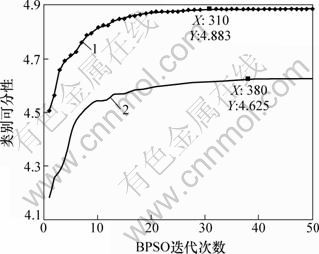
图4 BPSO迭代次数的确定
Fig.4 Determination of BPSO’s iterations
由图4可知:对于TCP与UDP协议,当迭代次数分别超过31与38时,其可分性判据的值达到稳定状态,因此在特征选择时,分别设TCP与UDP会话流的特征选择迭代次数为31与38。此时,选择出的TCP与UDP会话流的特征个数分别为14与19,特征向量维数大大减少。
4.3 神经元个数确定
在对BP神经网络进行训练时,不同的隐层神经元个数将会得到不同的神经网络架构,从而得到不同的协议识别率。而目前并没有合适的准则选择出最优的隐层神经元个数。针对不同神经元个数的神经网络进行训练,并选择最优的神经网络架构。同时,在对神经网络进行训练时,不同的迭代次数将产生不同的权值与阈值,最后得到不同的最优识别率。此外,针对不同神经元个数以及不同迭代次数分别进行训练,然后对测试集中的会话流进行测试,得到平均识别率,并设神经元个数与迭代次数范围均为1~50。又由于需要对TCP与UDP会话流进行识别,构造2个神经网络分别对其进行训练。图5和6所示分别为针对TCP与UDP协议采用不同神经元个数以及迭代次数进行训练后所得到的平均识别率,此处设置TCP与UDP会话流的持续时间为80 s。
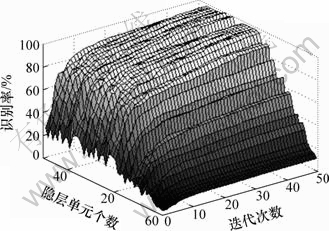
图5 不同神经元个数与迭代次数下的TCP会话流平均识别率
Fig.5 Average identification rates of different hidden numbers and iterations for TCP traffic
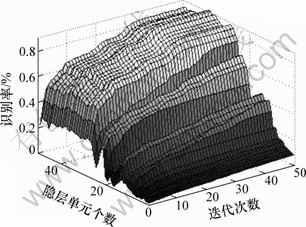
图6 不同神经元个数与迭代次数下的UDP会话流平均识别率
Fig.6 Average identification rates of different hidden numbers and iterations for UDP traffic
实验结果表明:针对TCP与UDP会话流,随着迭代次数的增加,会话流的平均识别率也稳定上升,并且当迭代次数超过40代时,其识别率达到稳定状态,表明神经网络的收敛性。同时,对于不同的神经元个数,其平均识别率也有所不同,且随着神经元个数的增加,平均识别率也在逐渐增加并趋于稳定,当会话流持续时间为80 s时,针对TCP与UDP会话流的隐层神经元个数分别为25与29时,其平均识别率达到稳定。
4.4 会话流持续时间的确定
在定义2与3中对TCP与UDP会话流进行定义时,会话流被定义为t时间内同一五元组发送与接收的所有数据包的集合,t的确定对协议识别率以及计算性能均有关系,若t过小,则由于获取的数据包过少而不能形成具有统计特征的信息;若t过大,则对计算性能造成较大影响,不能实时地对网络协议进行识别。此处分别对t从10秒到80秒进行测试,对每一持续时间的TCP与UDP会话流的平均识别率通过4.3节中的方法进行确定,取最优神经元个数时的识别率,测试结果如图7所示。

图7 不同时间t所对应的会话流识别率
Fig.7 Identification rate of traffic session using different time t
通过测试,对于TCP与UDP会话流,当t分别大于35 s与45 s之后,其识别率趋于平稳。因此,最终选择TCP与UDP会话流的持续时间分别为35 s与45 s,通过该方法,能够满足对网络协议的实时识别。
4.5 识别率对比
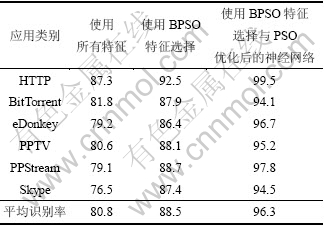
根据本文提出的方法,并选择最优神经元个数、会话流持续时间等因素。为体现特征选择的作用,分别针对经过特征选择与未经过特征选择2种情况下的平均识别率进行测试。为验证PSO对神经网络优化的效果,在使用特征选择的情况下,分别对未使用PSO优化与使用其优化后的神经网络的识别率进行测试。对6种常见协议的识别率如表2所示。
从表2可知:该方法对六种常见协议有较高的识别率,同时经过特征选择后的平均识别率有一定提高,其原因是特征选择能够从多种特征中定量地选择出最能够区分不同网络协议的特征子集,能够有效地提高识别率。并且使用PSO对神经网络优化之后的识别率也有较大提高,其原因在于使用PSO对神经网络的初始权值与阈值进行优化,能够有效防止其陷入局部最优解。
表2 网络应用识别率
Table 2 Identification rates of network applications %
5 结论
(1) 通过对UDP会话流的合理定义与测量,克服目前协议识别中只针对TCP协议进行识别的缺陷。同时,使用BPSO算法对多种特征进行选择,从中选择出最优的特征子集,最后通过对现有神经网络算法进行改进,对其初始权值与阈值进行优化,提高对协议的整体识别率。
(2) 测试结果表明:本文提出的方法其识别率有较大提高,同时能从多个特征中选择出最优特征子集,提高算法的识别率。通过对会话流时间的测定,该算法对网络协议识别具有实时性,具有良好的可扩展性与实用性。
参考文献:
[1] Nadia B A, Fabrice G. Impact of peer-to-peer applications on wide area network traffic[C]//Proc of IEEE Global Telecommunications Conference. Texas: IEEE, 2004: 1544-1548.
[2] Kim J T, Park H K, Paik E H. Security issues in peer-to-peer systems[C]//The 7th International Conference on Advanced Communications Technology. Phoenix Park: IEEE, 2005: 1059-1063.
[3] Sen S, WANG Jia. Analyzing peer-to-peer traffic across large networks[J]. IEEE Trans on Networking, 2004, 2(2): 219-231.
[4] Sen S, Spatscheck O, WANG D. Accurate, scalable in-network identification of P2P traffic using application signatures[C]//Proceedings of ACM WWW’04. New York: ACM, 2004: 512-521.
[5] Karagiannis T, Broido A. Transport Layer Identification of P2P Traffic[C]//Proceedings of the 4th ACM SIGCOMM conference on Internet measurement. Sicily: ACM, 2004: 121-134.
[6] LIU Feng, LI Zhi-tang, YU Jun-feng. P2P applications identification based on the statistics analysis of packet length[C]//Proceedings of the 2009 International Symposium on information Engineering and Electronic Commerce. Ternopil: IEEE, 2009: 160-163.
[7] XU Ke, ZHANG Ming, YE Ming-jiang, et al. Identify P2P traffic by inspecting data transfer behavior[J]. Computer Communications, 2010, 33(10): 1141-1150.
[8] Filho H, Fontenelle do Carmo R, Maia M F. An Internet traffic classification methodology based on statistical discriminators[J]. Network Operations and Magament Symposium, 2008: 907-910.
[9] Este A, Gringoli F, Salgarelli L. Support vector machines for TCP traffic classification[J]. Computer Networks, 2009, 53(14): 2476-2490.
[10] LI Zhu, YUAN Rui-xi, GUAN Xiao-hong. Accurate classification of the internet traffic based on the SVM method[C]//IEEE International Conference on Communications. Glasgow: IEEE, 2007: 1373-1378.
[11] Raahemi B, ZHONG Wei-cai, LIU Jing. Peer-to-peer traffic identification by mining IP layer data streams using concept-adapting very fast decision tree[C]//Proc of the 20th IEEE International Conference on Tools with Artificial Intelligence. Dayton, OH: IEEE, 2008: 525-532.
[12] Auld T, Moore A W, Gull S F. Bayesian neural networks for internet traffic classification[J]. IEEE Transaction on Neural Networks, 2007, 18(1): 223-239.
[13] CHEN Hong-wei, HU Zheng-bing, YE Zhi-wei, et al. Research of P2P traffic identification based on neural network[C]//International Symposium on Computer Network and Multimedia Technology. Wuhan: IEEE, 2009: 1-4.
[14] Callado A, Kelner J, Sadok D, et al. Better network traffic identification through the independent combination of techniques[J]. Journal of Network and Computer Applications. 2010, 33(4): 433-446.
[15] Eberhart R, Kennedy J. Particle swarm optimization[C]// Proceedings of IEEE International Conference on Neural Networks. Perth: IEEE, 1995: 1942-1947.
[16] Eberhart R, Kennedy J. A discrete binary version of the particle swarm algorithm[C]//IEEE Conference on Systems, Man, and Cybemetics. Orlando. FL: IEEE, 1997: 4104-4109.
[17] Sedki A, Ouazar D, Ei Mazoudi E. Evolving neural network using real coded genetic algorithm for daily rainfall-runoff forecasting[J]. Expert Systems with Applications, 2009, 36(3): 4523-4527.
[18] YU Shi-wei, ZHU Ke-jun, DIAO Feng-qin. A dynamic all parameters adaptive BP neural networks model and its application on oil reservoir prediction[J]. Applied Mathematics and Computation, 2008, 195(1): 66-75.
(编辑 邓履翔)
收稿日期:2011-06-05;修回日期:2011-08-02
基金项目:国家重点基础研究发展规划(“973”计划)项目(2007CB311106);国防重点实验室基金资助项目(NEUL20090101);科技部支撑项目(2012BAH18B05)
通信作者:陈兴蜀(1968-),女,教授,四川成都人,从事信息安全、机器智能方面的研究;电话:13981857689;E-mail:chenxs@scu.edu.cn

