DOI: 10.11817/j.issn.1672-7207.2016.09.023
几种基于统计的词聚类方法比较
袁里驰
(江西财经大学 信息管理学院,数据与知识工程江西省高校重点实验室,
江西 南昌,330013)
摘要:基于数据稀疏问题是影响语言统计模型系统性能的主要问题,而基于词类的语言统计模型是解决这一问题的主要方法之一,利用相邻词语的互信息定义一种词语相似度,在词语相似度的基础上定义词语集合的相似度,进而提出一种能得到全局最优结果、自下而上的词聚类算法。研究结果表明:该词聚类算法执行效率高,聚类效果较好;根据该词聚类模型的结果所构造的基于词类和基于词语的线性插值模型,能较好地缓解统计语言模型中的数据稀疏问题。
关键词:自然语言处理;词聚类;互信息;词相似度
中图分类号:TP391.1 文献标志码:A 文章编号:1672-7207(2016)09-3079-06
A comparison of several statistical word clustering methods
YUAN Lichi
(Jiangxi Key Laboratory of Data and Knowledge Engineering, School of Information Technology,
Jiangxi University of Finance and Economics, Nanchang 330013, China)
Abstract: Considering that sparse-data problem is a main issue that influences the performances of statistical language models, statistical language model based on word classes is an effective method to solve sparse-data problems. A definition of word similarity was proposed by utilizing mutual information of adjoining words, and the definition of word set similarity was given based on word similarity; a bottom-up hierarchical word clustering algorithm which can get global optimum was put forward. The results show that the word clustering algorithm has high executing speed and good clustering performances. The class-based models interpolated with the word-based models can mitigate remaining sparse-data problems of statistical language models.
Key words: natural language processing; word clustering; mutual information; word similarity
在自然语言理解的研究中,人们越来越重视统计语言模型,其最具代表性的n元语言统计模型根据词序列已出现的前n-1个词预测后1个词出现的概率。构造n元语言模型通常需要非常大的训练语料,有2个问题越来越突出:1) 系统的开销。随着语料资源的不断扩大,语言模型的参数规模急剧膨胀,语言模型的计算使现有的计算机硬件资源难以承受。2) 对某些特定领域来说,n元语言模型会遇到数据稀疏问题,即使使用的训练语料库庞大,也无法覆盖所有可能出现的语言现象。因此,在n元语言模型的实际使用中,很难避免会遇到大量从未出现的语言现象,如何估计这些语言现象的发生概率,是n元语言模型的主要问题之一。基于词类的n元语言模型是解决语言统计模型数据稀疏问题的重要方法之一。由于词类的数量要远小于词的数量,因此,基于词类的n元语言统计模型成功地缓解了基于词的n元语言模型所遇到的稀疏数据问题,而且因为词类的数量较少,使得统计基于词类的高阶语言模型成为可能。词的分类方法主要有2种:1) 语言学家根据语义语法知识,人工归纳词的分类,通常划分为几十个到几百个词类,这种词分类方法分类过粗,难以充分运用从语料库中获取的大量统计知识描述复杂多变的语言现象;2) 词的自动聚类算法。随着计算机科学与技术的发展,大规模的语料资源已成为开展语言研究的有力工具,通过对语料库进行统计实现词自动聚类成为可能。这种词分类方法可根据需要自动确定合适的词类数目,从而在一定程度上可以避免前一种词分类方法面临的问题。传统的词聚类统计方法[1-4]通常以贪婪原则为基础,以语料库的似然函数或困惑度作为判别函数。其基本思想是:随机地尝试合并2个词类,计算困惑度或似然函数的变化,将使困惑度最小的2个词类合并。这种传统的词聚类统计方法的主要缺点是聚类速度较慢,初始选择对聚类结果影响大,易陷入局部最优。本文作者利用基于邻接关系的词的互信息定义词相似度[5-6],在词相似度定义的基础上定义词集合(即词类)的相似度,进而提出一种能得到全局最优结果、自下而上的分层词聚类算法。
1 N元语言统计模型及其主要性能 评价
语言统计模型[7-10]最重要的任务是在已知前面出现的一些词的情况下,预测下一个词出现的概率。基于词的n(n≥1,为自然数)元语言统计模型是最具代表性的语言统计模型,能在已知前面出现的n-1个词的情况下,确定下一个词wi(i为自然数,i≥2)可能出现的概率为
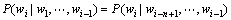 (1)
(1)
其中: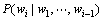 为条件概率。实际使用的n元语言统计模型中n一般取值2,3和4,分别称作二元统计语言模型、三元统计语言模型和四元统计语言模型。例如在基于词的三元语言统计模型中,假定1个词可能出现的概率只与前面2个词有关:
为条件概率。实际使用的n元语言统计模型中n一般取值2,3和4,分别称作二元统计语言模型、三元统计语言模型和四元统计语言模型。例如在基于词的三元语言统计模型中,假定1个词可能出现的概率只与前面2个词有关:
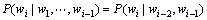 (2)
(2)
概率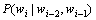 的估计由下式确定,称作最大似然估计法:
的估计由下式确定,称作最大似然估计法:
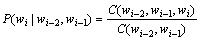 (3)
(3)
其中:计数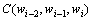 表示词序列
表示词序列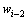 ,
,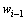 和
和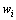 在训练语料库中出现的总次数。评价语言统计模型最常用的标准是语言模型的困惑度[3]。语言统计模型的困惑度
在训练语料库中出现的总次数。评价语言统计模型最常用的标准是语言模型的困惑度[3]。语言统计模型的困惑度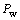 是测试语料分布概率的几何平均的倒数,其具体定义如下:
是测试语料分布概率的几何平均的倒数,其具体定义如下:
 (4)
(4)
其中:Nw为测试语料集中全部词的数量。对于1个语言统计模型来说,测试语料集困惑度越低,则该语言统计模型越好。
2 布朗词聚类算法
BROWN等[11]提出了一种经典的基于互信息和贪婪原则的词聚类统计方法。其基本思想是:随机地尝试合并2个词类,计算互信息的变化,将使互信息损失最小的2个词类合并。布朗词聚类统计方法初始设置词表中的每个词各代表一词类,设训练语料集中词的数量为V,经过V-K次合并后,还有K个词类:
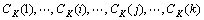
其中:1≤i<j≤K。下面计算合并词类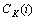 和
和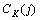 引起的互信息变化。
引起的互信息变化。
设
 (5)
(5)
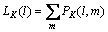 (6)
(6)
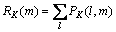 (7)
(7)
其中:1≤l<m≤K;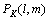 为词类
为词类 和
和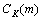 出现的联合概率。并设
出现的联合概率。并设
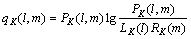 (8)
(8)
经过V-K次合并后,保留下来的平均互信息为
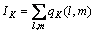 (9)
(9)
记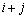 表示词类和合并成的新词类,则有
表示词类和合并成的新词类,则有
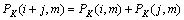 (10)
(10)
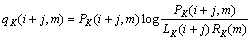 (11)
(11)
且词类和合并后保留下来的平均互信息为
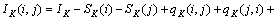
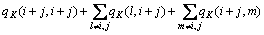 (12)
(12)
其中:
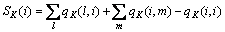 (13)
(13)
平均互信息损失为
 (14)
(14)
将息损失最小的2种词类合并成1种新的词类。
3 基于长距离二元模型的词聚类算法
BASSIOU等[12]提出了一种基于概率潜在语义分析(probabilistic latent semantic analysis)和线性插值长距离二元模型的词聚类方法。概率潜在语义分析的核心思想是示象模型(aspect model),该模型使得每个类变量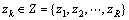 与每次观测值相关。在聚类模型中,观测值即为文本(或文档)
与每次观测值相关。在聚类模型中,观测值即为文本(或文档)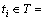
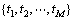 中的某个词,而不可见的类变量则为生成某个文本的主题建立的模型变量。据示象模型的基本假设,所有的观测对
中的某个词,而不可见的类变量则为生成某个文本的主题建立的模型变量。据示象模型的基本假设,所有的观测对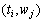 独立分布,并且关于各自的潜在类
独立分布,并且关于各自的潜在类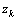 条件独立,此由,在潜在类生成的1文本
条件独立,此由,在潜在类生成的1文本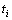 及文本中的1词
及文本中的1词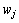 的联合概率分布可由下式给出:
的联合概率分布可由下式给出:
 (15)
(15)
而概率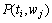 可通过如下线性插值长距离二元概率计算:
可通过如下线性插值长距离二元概率计算:
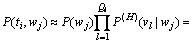
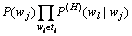 (16)
(16)
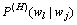 可通过在所有的可能实现上求和获得:
可通过在所有的可能实现上求和获得:
 (17)
(17)
权重参数 满足
满足 ,0≤≤1。概率
,0≤≤1。概率 ,
, 的对数似然函数的最大值由下式给出:
的对数似然函数的最大值由下式给出:

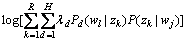 (18)
(18)
其中: 。式(18)使用概率潜在语义分析EM算法计算。
。式(18)使用概率潜在语义分析EM算法计算。
E-步(计算期望,利用对隐藏变量的现有估计值计算其最大似然估计值):
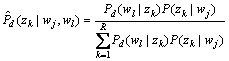 (19)
(19)
M-步(最大化在E步上求得的最大似然值来计算参数值):
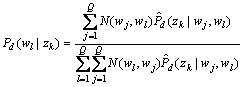 (20)
(20)
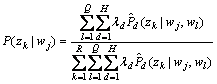 (21)
(21)
交替计算式(19),(20)和(21),直到对数似然函数值收敛到局部最大值为止。每个词由下式分配到1个词类:
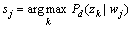 ;j=1, 2, …, Q (22)
;j=1, 2, …, Q (22)
其中:
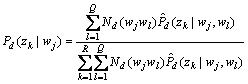 (23)
(23)
4 基于词相似度的聚类算法
4.1 基于互信息的词相似度和词类相似度
与前面提到的2种贪婪词聚类统计方法不同,本文提出的词聚类方法基于词对之间的相似度和词集合 (词类)的相似度。因此,首先要找到一种可靠的、适于计算的词与词间相似度、词类之间相似度的定量计算标准。基于语料库的传统统计方法通常认为某个词的意义可能与该词所处的上下文中出现的其他词语有关,即可能与该词的语言环境有关。因此,2个词在训练语料中所处的语言环境若总是很相似,则可以认为这2个词彼此之间可能很相似[13]。
若2个词w1和w2很相似,则可以推断这2个词w1和w2与其他词之间的互信息也很相似。记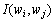 表示相邻的词对
表示相邻的词对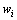 和之间的互信息:
和之间的互信息:
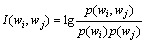 (24)
(24)
其中: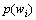 和
和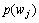 分别为词和在训练语料库中出现的概率;
分别为词和在训练语料库中出现的概率;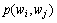 为词和出现的联合概率。定义
为词和出现的联合概率。定义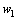 和
和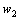 之间的相似度为
之间的相似度为
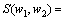
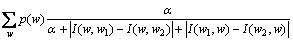 (25)
(25)
其中:参数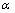 >0,
>0,
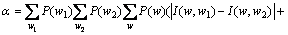
 (26)
(26)
由式(26)可知:若2个词w1和w2与它们的左右相邻词之间的互信息差别越小,则这2个词之间的相似度越高,因而,这种词相似度的定义较合理的。基于词相似度定义,2个词类(词集合) C1和C2之间的相似度S(C1, C2)定义如下:
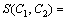
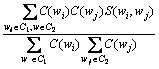 (27)
(27)
其中: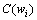 和
和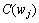 分别为词和在训练语料中出现的数量。
分别为词和在训练语料中出现的数量。
4.2 词聚类算法
为了使本文提出的词聚类算法更接近于汉语语义真实分类体系[14-15],选择分层聚类方法作为词聚类算法。分层词聚类方法采用自底向上的算法,即首先每个词分别代表1个词集合(词类),而词集合(词类)的数目就是该词表的大小(V),然后找出具有最大词相似度的2个词集合(词类)。将这2个词集合(词类)合并成1个新的词集合(词类),直到达到聚类结束的要求为止。整个词聚类算法过程如下。
1) 计算任意2个词之间的相似度。
2) 初始化。设词表中的每个词分别代表1个词集合(词类),词表共包括V个词集合(词类)(其中,V为该词表中包含的词的个数)。
3) 找出词集合(词类)中具有最大相似度的2个词集合(词类),并将这2个词集合(词类)合并成1个新的词集合(词类)。
4) 计算刚合并的词集合(词类)与其他词集合(词类)的相似度。
5) 检查算法是否达到聚类结束的条件(任意2个词类之间的最大相似度都小于某个预先确定的门槛值,或词表中的词类数目达到聚类的要求)。若是,则程序可以结束;否则,转步骤3)。
本文提出的基于词相似度的聚类算法与2种贪婪聚类算法相比,有2个较突出的优点:1) 基于长距离二元模型的词聚类方法,其对数似然函数值收敛到局部最大值,而基于词相似度的分层聚类方法能得到全局最优结果;2) 分层词聚类算法的速度远远高于2种贪婪聚类算法的速度。布朗词聚类算法复杂度为 ,本文词聚类算法可以分为3部分:1) 计算任意2个词或词类之间的互信息,其计算复杂度为
,本文词聚类算法可以分为3部分:1) 计算任意2个词或词类之间的互信息,其计算复杂度为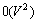 ;2) 找出词表中具有最大相似度的2个词类,其计算复杂度仍为;3) 计算刚合并的词类与其他词类的相似度,其计算复杂度为
;2) 找出词表中具有最大相似度的2个词类,其计算复杂度仍为;3) 计算刚合并的词类与其他词类的相似度,其计算复杂度为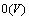 。综上所述,基于词相似度的分层词聚类算法的计算复杂度为。基于词相似度的分层词聚类算法其算法复杂度要远比使平均互信息损失最小的布朗词聚类算法的复杂度小。
。综上所述,基于词相似度的分层词聚类算法的计算复杂度为。基于词相似度的分层词聚类算法其算法复杂度要远比使平均互信息损失最小的布朗词聚类算法的复杂度小。
5 实验结果验证
在前面所介绍的3种词聚类统计语言模型的基础上,选取1998年的《人民日报》标注语料库用作实验语料。该《人民日报》标注语料库以1998年《人民日报》语料为加工对象,由富士通研究开发中心有限公司和北京大学计算语言学研究所共同制作,包含13 000多篇文章和2 600万字。本文从实验语料中选取大约6 M语料作为测试语料,其余语料作为训练语料,用3种词聚类统计方法进行测试,其困惑度测试结果如表1所示。
从表1可见:基于词相似度的词聚类算法的困惑度只有213,其聚类效果要明显比2种经典的词聚类统计方法好。虽然这2种经典的词聚类统计方法是以训练语料的困惑度作为指导进行分类,但这2种贪婪词聚类算法很容易陷入局部最优,因而,其聚类结果的困惑度要远高于本文提出的基于词相似度的分层聚类算法的困惑度。现从词聚类实验结果中随意选择一些词类,其分类如下。
表1 3种词聚类算法的困惑度测试结果比较
Table 1 Perplexities of three clustering algorithms

词类1:合肥,湛江,长沙,南昌,巴格达,伦敦,上海,北京,等等。
词类2:两样,一致,雷同,平等,不相上下,一如,异口同声,同一,相等,一律,相同,一样,等于,同样,不等,异曲同工,势均力敌,大同小异,对等,一模一样,等等。
词类3:偷盗,骗取,制黄,抄袭,偷窃,持枪,卖淫,逃税,恐怖,掺假,贩黄,抗税,等等。
词类4:近似,宛如,相近,一般,类似,譬如,比如,恰似,似,好似,如同,相似,仿佛,犹如,接近,相仿,貌似,有如,好像,形似,似乎,等等。
词类5:大,超越,超出,胜,后来居上,压倒,等等。
词类6:相形见绌,逊色,不及,望尘莫及,等等。
词类7:不比,相左,悬殊,不同,等等。
从聚类结果可以看到,基于词相似度的聚类统计方法比较接近真实的自然语言语义分类体系。本文第2个实验是比较基于词的模型、基于词类的模型(基于词相似度的聚类算法构造)、使用线性插值的基于词类和基于词相结合的语言模型对数据稀疏问题的承受能力。 将训练语料从6 M递减到3 M再减小到1 M,分别训练基于词的二元模型、基于词类的二元模型和线性插值二元模型,然后用全部的6 M语料测试困惑度变化,结果如表2所示。
表2 3种模型的困惑度变化
Table 2 Changes of perplexity of three clustering algorithms

从表2可以看出:在训练语料较充分的情况下,基于词的二元模型的性能远远优于基于词类的二元模型的性能,但在训练语料数据非常稀疏的情形下,基于词的二元语言统计模型的性能急剧下降。然而,基于词类的二元语言统计模型在训练语料数据非常稀疏时,其性能也有所下降,但其性能始终相对平稳,即使在训练语料数据极端稀疏的情形下,模型性能的下降幅度也不太大。并且无论语料在什么情况下,线性插值二元模型均能明显提高系统性能。
6 结论
1) 利用基于相邻关系的词的互信息定义了一种词相似度,再在词的相似度定义基础上定义词类(词集合)的相似度,进而提出了一种能得到全局最优结果、自下而上的分层词聚类算法。
2) 本文提出的分层词聚类算法其计算复杂度要远远比基于贪婪原则的传统统计词聚类算法的计算复杂度小,以较小的计算代价取得了比较好的聚类效果。
3) 对3种词聚类统计方法进行测试,其中基于词相似度的分层词聚类算法的困惑度为213,远低于其他2种词聚类统计方法的困惑度。
4) 根据新的词聚类模型的结果所构造的基于词类的语言统计模型、基于词类和基于词的线性插值语言模型能较好地解决统计语言模型的稀疏数据问题,且基于词类和基于词的线性插值二元语言模型的困惑度为94,低于基于词的二元语言模型的困惑度(105)。由于词类的数量要远小于词的数量,因而,基于词类的语言模型遇到的数据稀疏问题要远比基于词的语言模型少,系统性能明显稳定。
参考文献:
[1] 陈浪周, 黄泰翼. 一种新颖的词聚类算法和可变长统语言模型[J]. 计算机学报, 1999, 22(9): 942-947.
CHEN Langzhou, HUANG Taiyi. A novel word clustering algorithm and vari-gram language mode[J]. Chinese Journal of Computers, 1999, 22(9): 942-947.
[2] 孙静, 朱杰, 徐向华. 一种新的中文词自动聚类算法[J]. 上海交通大学学报, 2003, 37(Suppl): 139-142.
SUN Jing, ZHU Jie, XU Xianghua. A new algorithm of Chinese words automatic clustering[J]. Journal of Shanghai Jiaotong University, 2003, 37(Suppl): 139-142.
[3] MATSUZAKI T, MIYAO Y. An Efficient clustering algorithm for class-based language models[C]// Proceedings of the 7th Conference on Natural Language Learning at HLT-NAACL. Edmonton, Canada, 2003: 119-126.
[4] LIU Ying, WANG Nan, ZHANG Tie. Spectral clustering for Chinese word[C]// Proceedings of the Sixth International Conference on Fuzzy Systems and Knowledge Discovery. Tianjin, China, 2009: 529-533.
[5] 袁里驰. 基于相似度的词聚类算法和可变长语言模型[J]. 小型微型计算机系统, 2009, 30(5): 912-915.
YUAN Lichi. word clustering based on similarity and vari-gram language model[J]. Journal of Chinese Computer Systems, 2009, 30(5): 912-915.
[6] 袁里驰. 基于词聚类的依存句法分析[J]. 中南大学学报(自然科学版), 2011, 42(7): 2023-2027.
YUAN Lichi. Dependency language paring model based on word clustering[J]. Journal of Central South University (Science and Technology), 2011, 42(7): 2023-2027.
[7] 刘水, 李生, 赵铁军, 等. 头驱动句法分析中的直接插值平滑算法[J]. 软件学报, 2009, 20(11): 2915-2924.
LIU Shui, LI Sheng, ZHAO Tiejun, et al. Directly smooth interpolation algorithm in head-driven parsing[J]. Journal of Software, 2009, 20(11): 2915-2924.
[8] 吴伟成, 周俊生, 曲维光. 基于统计学习模型的句法分析方法综述[J]. 中文信息学报, 2013, 27(3): 9-19.
WU Weicheng, ZHOU Junsheng, QU Weiguang. A survey of syntactic parsing based on statistical learning[J]. Journal of Chinese Information Processing, 2013, 27(3): 9-19.
[9] 代印唐, 吴承荣, 马胜祥, 等. 层级分类概率句法分析[J]. 软件学报, 2011, 22(2): 245-257.
DAI Yintang, WU Chengrong, MA Shengxiang, et al. Hierarchically classified probabilistic grammar parsing[J]. Journal of Software, 2011, 22(2): 245-257.
[10] JURAFSKY D, MARTIN J H. Speech and language processing[M]. New Jersey: Prentice Hall, 2009: 210-265.
[11] BROWN P F, PIETRA V J D, DE SOUZA P V, et al. Class-based n-gram models of natural language[J]. Computational Linguistics, 1997, 18(4): 467-479.
[12] BASSIOU N, KOTROPOULOS C. Long distance bigram models applied to word clustering[J]. Pattern Recognition, 2011, 44(1): 145-158.
[13] DAGAN I, et al. Context word similarity and estimation from sparse data[J]. Computer Speech and Language, 1995, 9(2): 123-152.
[14] 袁里驰. 融合语言知识的统计句法分析[J]. 中南大学学报(自然科学版), 2012, 43(3): 986-991.
YUAN Lichi. Statistical parsing with linguistic features[J]. Journal of Central South University (Natural Science), 2012, 43(3): 986-991.
[15] YUAN Lichi. Improving head-driven statistical models for natural language parsing[J]. Journal of Central South University, 2013, 20(10): 2747-2752.
(编辑 陈灿华)
收稿日期:2015-11-13;修回日期:2015-12-28
基金项目(Foundation item):国家自然科学基金资助项目(61262035,61562034);江西省自然科学基金资助项目(20142BAB207028);江西省科技支撑计划项目(20151BBE50082);江西省教育厅科技项目(GJJ14335) (Projects(61262035, 61562034) supported the National Natural Science Foundation of China; Project(20142BAB207028) supported the Natural Science Foundation of Jiangxi Province; Project(20151BBE50082) supported the Key Technology Support Program of Jiangxi Province; Projects(GJJ14335) supported the Scientific Research Foundation of Education Department of Jiangxi Province)
通信作者:袁里弛,博士,副教授,从事自然语言处理研究;E-mail: yuanlichi@sohu.com

