A free search algorithm with double populations for QoS multicast routing
KONG Sun(����), CHEN Zeng-qiang(����ǿ)
(Department of Automation, Nankai University, Tianjin 300071, China)
Abstract: In this paper, we introduce a modified free search (FS) algorithm to solve QoS multicast routing problem. Based on basic FS, the algorithm introduces an auxiliary population to retain the suboptimal solutions searched in order to keep the algorithm from falling into local optimum. In addition, the algorithm is improved by variable neighbor space and preserving excellent members. Considering the operation mode of FS algorithm, we adopt path-based method to construct multicast trees and transform tree optimization problem into function optimization problem. The performance and efficiency of the proposed algorithm are evaluated in comparison with other common algorithms. The results of the experiments show that the new algorithm has the better comprehensive performance.
Key words: QoS; multicast routing; free search algorithm; double populations
CLC number: TP301 Document code: A Article ID: 1672-7207(2011)S1-0124-06
1 Introduction
At present, more and more multimedia applications require strict quality of service (QoS) guarantee during the communication between a single source and multiple destinations. This gives rise to the need for an efficient QoS multicast routing (QMR) strategy. Hence, the research in QMR problem is very important for the development of the network theory and applications. Searching for such QoS-based optimal multicast routes basically leads to a multi-objective optimization problem. Unfortunately, this problem is computationally intractable in polynomial time due to the uncertainty of resources in networks[1].
Many intelligent optimization algorithms have been proposed to solve this problem[2-13]. Genetic algorithm (GA) is one of the most popular algorithms applied to QMR problem[5-8]. In Ref.[7], a multicast tree is produced by the means of finding the paths from the source node to each destination node and merging the paths into a tree. The optimization of a multicast tree is finished through a serial path selection. The method can make the crossover and mutation operation easy to realize. However, the GA algorithm adopted needs a long time to converge. A heuristic genetic algorithm for bandwidth-delay-constrained least-cost multicast routing problem has been proposed in Ref.[8]. They have used a tree structure for genotype representation, but the crossover scheme leads to discontinuity among sub-trees in encoding scheme and it is difficult to connect the sub-trees. In recent years, several algorithms based on particle swarm optimization (PSO) have been proposed to solve multicast routing problem[9-10]. Liu et al[9] have proposed a path-based PSO. This algorithm performs better than standard GA in converging speed and searching capability for a 20-node network. In addition, a novel probability convergence based PSO for the optimization of QoS multicast routing has been proposed in Ref.[10] that has introduced a probability based updating process. However, both of the Refs.[9] and [10] conduct simulation experiment in a given network. So the results of the experiment only show the superiority of the algorithms in the current network, but not in random networks. Up to now, although many intelligent optimization algorithms are adopted for multicast routing problem, most of them can��t solve this problem very well.
Free search (FS)[11] is a novel population-based optimization method. It models behavior of the animals. The difference from all other population based optimization methods is that the behavior of the animals in FS is not defined. It is not strictly controlled and can only be described by some probability. In FS algorithm, the animals have a freedom to take a decision where and how to search. FS algorithm is based on the assumptions: with an uncertainty can cope other uncertainty. With infinity can cope other infinity. At present, FS algorithm is popular with many researchers because of less parameter and good robustness[12-13].
In order to solve QMR problem better, we propose a multicast routing algorithm based on a modified FS. In the improvement, an auxiliary population set is adopted to retain the suboptimal solutions. The method can avoid local optimum and improves algorithm performance. Experiment simulations on a variety of network topologies show that the proposed algorithm can solve QMR problem more effectively.
2 Network model and problem formulation
A network is usually modeled as a weighted graph G=(V, E), where V denotes the set of nodes and E denotes the set of communication links connecting the nodes. Let 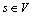 be the source node and
be the source node and 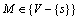 be the set of destination nodes. We refer to M as the multicast group. Generally, supposed there is only one link between a pair of nodes in network. Let R+ be non-negative real numbers set.
be the set of destination nodes. We refer to M as the multicast group. Generally, supposed there is only one link between a pair of nodes in network. Let R+ be non-negative real numbers set.
Four non-negative real value functions are associated with each node n(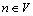 ): delay function
): delay function 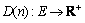 , delay Jitter function
, delay Jitter function 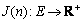 , packet-loss function
, packet-loss function 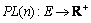 and cost function
and cost function 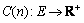 .
.
Four non-negative real value functions are associated with each link 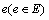 : delay function
: delay function 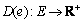 , delay Jitter function
, delay Jitter function 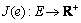 , bandwidth function
, bandwidth function 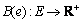 and cost function
and cost function 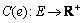 .
.
For a given source node s and a set of destination nodes M, a multicast tree T(s, M) which is a sub-graph of G spans the source node s and the set of destination nodes M has the following relations:
1) 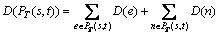
2) 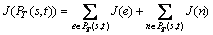
3) 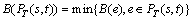
4) 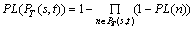
5) 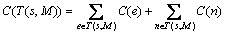
where 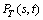 is the path from source node s to each destination node
is the path from source node s to each destination node 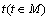 in the multicast tree
in the multicast tree 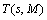 .
.
The constraints of the multicast tree are defined by:
a) Delay constraint, 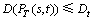 ;
;
b) Delay Jitter constraint, 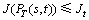 ;
;
c) Bandwidth constraint, 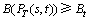 ;
;
d) Packet-loss constraint, 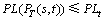 .
.
where Dt is the delay constraint, Jt is the delay jitter constraint, Bt is the bandwidth constraint and PLt is the packet-loss constraint.
The multi-constrained least-cost multicast problem is minimizing the cost of the multicast tree T(s, M) which satisfies all of the constraint conditions above a) �C d). The expression of minimizing the cost of the multicast tree is of the form:
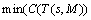 (1)
(1)
In this paper, we assume every destination node has the same delay constraint, delay Jitter constraint, bandwidth constraint and packet-loss constraint.
3 A brief description of FS
The FS algorithm attempts to imitate behavior of the animals and operates on a set of solutions called population W. The m individuals of this population are called animals. In the model, the animals can move step by step through multi-dimensional non-discrete search space. The Xmini and Xmaxi are the search space borders, where i(i=1, ��, n) is the dimension of variables and n is the number of dimensions. During the search process, each animal takes exploration walks T in order to find a better solution. The location of the jth (j=1, ��, m) animal is initialized as
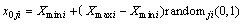 (2)
(2)
where random(0, 1) is a random value between 0 and 1.
The exploration walk consists of a number of steps. For the current step t, each animal generates coordinates of a new location xtji as
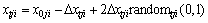 (3)
(3)
During the exploration walk, the animals step within the variable neighbor space is Rji. The neighbor space is limited as 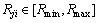 , which is a tool for tuning rough and precise searches. Then the modification strategy
, which is a tool for tuning rough and precise searches. Then the modification strategy 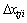 is defined as
is defined as
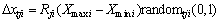 (4)
(4)
The individual behavior, during the walk, is described as
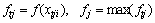 (5)
(5)
where f(xtji) is the evaluation function of the jth individual after each step walk, max(ftj) is the best evaluation function value of the jth individual after walk.
After an exploration walk, each animal distributes a pheromone, which indicates locations�� quality. The pheromone is fully replaced with a new one after each walk. The animals abstract the information about the locations marked with pheromone essential for the search. The pheromone generation is
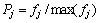 (6)
(6)
where fj is the only location marked with pheromone from an animal after the walk and max(fj) is the best individual function value after walking.
Each animal has a sense and propensity for pheromone. The animal uses its sense for selection of location for the next step. Different animals have different sensibilities. It also varies during the optimization process, and one animal can have different sensibilities before different walks. The animals can select, for start of the exploration walk, any location marked with pheromone, which fits its sense. The sensibility generation is
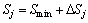
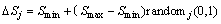 (7)
(7)
where Smin and Smax are minimal and maximal possible values of the sensibility. Pmin and Pmax are minimal and maximal possible values of the pheromone trials.
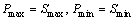
Selecting and decision-making for a start location 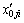 for an exploration walk,
for an exploration walk,
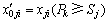 (8)
(8)
where k (k=1, ��, m) is the coordination point of marked pheromone.
4 FS with double populations (FSDP)
In this section, we present a modified FS algorithm, namely FSDP algorithm. Before presenting the FSDP algorithm, we differentiate between FS and FSDP. There are three differences between them. The first difference is that FSDP uses two population sets, namely the sets W1 and W2 as opposed to the only one set W in FS. Each of the sets contains m individuals. We call W2 the auxiliary population set. The function of W1 in FSDP is the same as that of W in FS. The function of the auxiliary set W2 in FSDP is to keep record of the suboptimal individuals that are discarded in FS. These potential individuals in W2 are then used for further explorations. The second difference between the two algorithms is the way they implement the neighbor space Rj. FSDP uses a variable neighbor space Rj for each animal as opposed to FS which uses a set of fixed Rj parameters. Thirdly, FSDP differs from FS in that it adopts a method of preserving excellent members.
4.1 Description of the FSDP algorithm
Initially, two sets W1 and W2 are generated by Eq. (2). Two individuals are iteratively sampled from the search region. The best individual x0j is going to W1 and the suboptimal individual x0j to W2. The process continues until each set has m individuals. The FSDP procedure then gradually drives the set W1 towards the global optimum through the repeated cycles of taking exploration walk, distributing pheromone, generating sensibility, selection and preserving the best individual. For each animal, there are two starting locations: One location is from W1 and the other is from W2. During the search process, each animal takes exploration walks respectively from two different starting locations, by Eq.(3) and Eq.(4). The locations from W1 take exploration walks T 1 and the ones from W2 take exploration walks T2. In this algorithm, we adopt variable neighbor space Rj. The rule is as following:
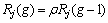 (9)
(9)
where g is the exploration generation, �� is the radius contract coefficient 0�ܦѡ�1. When ��=1, the algorithm turns to be the basic FS. If the value of �� is low, the search neighbor search space becomes narrow quickly. Selecting an appropriate value of �� will greatly benefit for good performance of the FS algorithm.
After exploration walks, each animal has two tracks. For each animal, we combine the two tracks. The locations in tracks are evaluated by given evaluation function. Then we can obtain the best location and suboptimal location. The best location is marked. In addition, the suboptimal one replaces the corresponding one in W 2 for next generation. The pheromone is calculated by Eqs. (5) and (6). After that, the sensibility for each animal can be obtained.
At the selection phase, if 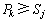 , a starting location xji is obtained by the jth animal. If the starting location which the animal randomly selects is better than the corresponding location in W 1, then replace.
, a starting location xji is obtained by the jth animal. If the starting location which the animal randomly selects is better than the corresponding location in W 1, then replace.
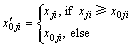 (10)
(10)
where is the start location for the next generation.
4.2 Time complexity degree of FSDP algorithm
In this paper, we only analyze the influence of main parameters on the time complexity of the proposed algorithm, which mainly depends on four parts. Table 1 shows the results.
Table 1 Time complexity analysis of FSDP algorithm

5 FSDP algorithm for multicast routing
5.1 Coding
According to the characters of FS, a route encoding scheme[5] is adopted, which is the most natural and simplest representing method. The encoding method uses a population vector to denote a multicast tree. Obviously, a vector represents a candidate solution for the multicast routing problem since it concludes paths between the source node and any of the destination nodes. Each population vector is composed of a series of integers which show the path numbers for each source-destination. Hence, the routing table for each source-destination pair needs to be constructed firstly.
5.2 Evaluation of Population
We suppose that the constraint of each property is the same for all the destinations and 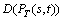 ,
, 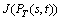 ,
, 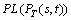 separately take the maximum value of corresponding property for all destinations. The fitness function is defined as follows:
separately take the maximum value of corresponding property for all destinations. The fitness function is defined as follows:
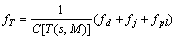
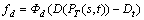
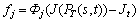
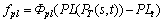 (11)
(11)
where 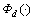 is the penalty function of delay, its value is 60, or else rd (rd��0) when the vector satisfies the delay constraint (D(PT(s,t))��Dt);
is the penalty function of delay, its value is 60, or else rd (rd��0) when the vector satisfies the delay constraint (D(PT(s,t))��Dt); 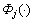 is the penalty function of delay-Jitter, its value is 10, or else rj (rj��0) when the vector satisfies the delay-jitter constraint (J(PT(s,t))��Jt);
is the penalty function of delay-Jitter, its value is 10, or else rj (rj��0) when the vector satisfies the delay-jitter constraint (J(PT(s,t))��Jt); 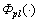 is the penalty function of packet-loss, its value is 10, or else rpl (rpl��0) when the vector satisfies the packet-loss constraint (PL(PT(s,t))��PLt); The value of rd, ri and rpl determine the degree of penalty. In our experiment simulation, we select rd=rj=rpl=0.5.
is the penalty function of packet-loss, its value is 10, or else rpl (rpl��0) when the vector satisfies the packet-loss constraint (PL(PT(s,t))��PLt); The value of rd, ri and rpl determine the degree of penalty. In our experiment simulation, we select rd=rj=rpl=0.5.
5.3 FSDP-based QoS Multicast Routing Algorithm
Input: The number of destination nodes (equal to the dimension of the animal�� locations) ; Population size; Parameters of the network model.
Output: The best fitness value after FSDP executes for the maximal generation; Optimal multicast tree.
The procedures of applying FSDP algorithm to QoS multicast routing is described as follows:
1) Construct routing table. Construct the routing table for each source-destination pair.
2) Initialize population. For each destination, randomly select one path from the routing table. After every destination node has a path connected to source node, integrate these paths into a multicast tree. Continue until each set has m multicast trees. Generate two population sets by this way.
3) Search optimal multicast tree. In this step, the multicast tree is optimized by FSDP algorithm. Note the following points: Firstly, a new path number generated may be out of range during the exploration walk. The solution to this problem is selecting a path number randomly from the routing table. Secondly, loops may exist in the multicast tree in that path combinations may generate loops. If so, we must delete loops.
6 Simulation results
The simulation network topology is generated by adopting the Waxman topology models[14]. The source node, destination node and link weight are generated randomly. The network topology with network features in reality is generated by selecting the values of 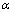 and
and 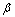 in the Waxman model.
in the Waxman model.
In order to testify the effectiveness of FSDP algorithm, we compare it with basic FS algorithm, Hwang-GA-based algorithm (Hwang-GA)[7] and the path-based PSO (Liu-PSO) in Ref.[9]. The simulation network is generated by the Waxman model.
Five different 60-node networks are generated randomly. Multicast group member number is set to 10. The four algorithms are tested in the same constraint conditions: Bt=60, Dt=90, DJt=30, PLt=0.001. For each network, four algorithms can find its optimal multicast tree. Fig.1 shows the results. In Fig.1, the multicast tree cost, delay and jitter of four algorithms are compared. Simulation data is the average result obtained in five different networks.
It can be seen from Fig.1 that the multicast tree obtained by FSDP has the lowest average cost on the premise of satisfying all constraint conditions.
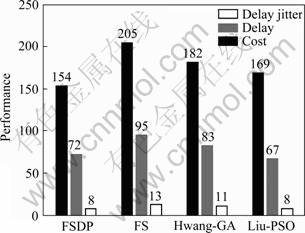
Fig.1 Comparison of performance of four algorithms
Based on a lot of simulations, we find that the number of destination nodes can affect the performance of the algorithms. To testify the validation of the algorithm for multicast groups of different scale, the four algorithms are used to construct multicast trees on network topology of 60 nodes. We choose ten multicast groups which account for 5%-50% of the total number of the network nodes. Fig.2 illustrates the comparison results. As shown in Fig.2, with the gradual increase of the multicast group scale, the FSDP algorithm can find better solutions than other algorithms.
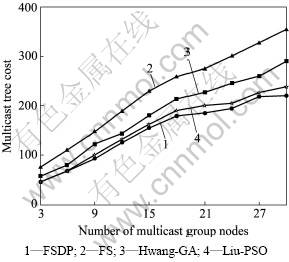
Fig.2 Comparison of multicast tree cost in multicast groups of different scales
In addition, the number of network nodes also has a great impact on the simulation results. We test the robustness of FSDP by varying the network size. In this simulation, the proposed algorithm is still compared with the three algorithms mentioned before. The average success rate and the relative convergence time are used as the measurements of performance.
For each algorithm, the average success rate changes with the increasing number of network nodes. Among the solutions obtained by all the algorithms, the best one is recorded for each random network. The success rate is defined as 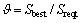 , where Sbest is the number of the best solution obtained, Sreqt is the total number of all solutions. Fig.3 shows the results.
, where Sbest is the number of the best solution obtained, Sreqt is the total number of all solutions. Fig.3 shows the results.
Fig.4 shows the relative convergence time ratio of basic FS algorithm, Hwang-GA and Liu-PSO. The relative convergence time ratio 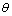 is defined as
is defined as 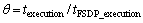 , where texecution represents the average convergence time for each algorithm, tFSDP_execution is the average convergence time of the proposed algorithm in this paper.
, where texecution represents the average convergence time for each algorithm, tFSDP_execution is the average convergence time of the proposed algorithm in this paper.
It can be seen from Figs.3-4 that FSDP performs better than other algorithms. The path-based PSO (Liu-PSO) algorithm has higher success ratio but it takes longer convergence time. The convergence time of the basic FS algorithm is close to FSDP, but the algorithm has defects in solving discrete questions so that it performs poor. The Hwang-GA easily gets into local optima with the increase of network size, which can result in decline of the success ratio. Compared with the three algorithms, the improved algorithm has the highest success rate in networks of 60-300 nodes. It can be seen from the simulation results that FSDP shows the better comprehensive performance by comparison.
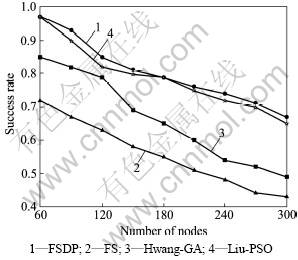
Fig.3 Comparison of average success ratio in different network scales
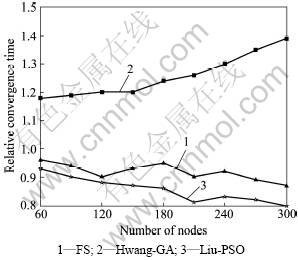
Fig.4 Comparison of average execution time ratio in different network scales
7 Conclusions
For the QoS multicast routing problem, we propose a free search algorithm with double populations. Based on basic FS algorithm, this algorithm adopts two populations to optimize multicast trees. The method enables the populations to retain the suboptimal solutions and search for better solutions around the suboptimal solutions. Compared with the FS algorithm, the modified algorithm can improve the accuracy of the searching. In addition, the methods of variable neighbor space and preserving excellent members are used in this algorithm to improve the search efficiency of FS algorithm.
In this paper, we have tested the effect of population size, exploration walk and adjustable parameter on the performance of the FSDP algorithms to solve the QoS multicast routing problem. The simulation results show that the FSDP makes it possible to find feasible solutions for multicast routing problem. In our study, we compare the proposed algorithm with several common optimization algorithms in different scales of network topology. These experiments have shown that our algorithm�� comprehensive performance is superior to other algorithms mentioned in this paper for larger networks.
References
[1] Wang Z, Crowcroft J. Quality of service for supporting multimedia applications[J]. IEEE Journal on Selected Areas in Communications, 1996, 14(7): 1228-1234.
[2] Sun W S, Liu Z M. Multicast routing based neural networks[J]. Journal of China Institute of Communications, 1998, 19(11): 1-6 .
[3] Zhang L, Cai L B, Li M. A method for least-cost QoS multicast routing based on genetic simulated annealing algorithm[J]. Computer Communications, 2009, 32: 105-110.
[4] Kong S, Chen Z Q. QoS multicast routing based on double- population differential evolution algorithm[J]. Journal of Computational Information Systems, 2010, 6(6): 1717-1725.
[5] Shimamoto N, Hiramatu A, Yanmasaki K. A dynamic routing control based on a genetic algorithm[C]//IEEE the International Conference on Neural Network. 1993: 1123-1128.
[6] Fei X, Luo J Z, Wu J Y. QoS routing based on genetic algorithm[J]. Computer Communications, 1999, 22(9): 1394-1399.
[7] Hwang R H, Do W Y, Yang S C. Multicast routing based on genetic algorithms[J]. Journal of Information Science and Engineering, 2000, 16(5): 885-901.
[8] Wang Z Y, Shi B X, Zhao E D. Bandwidth-delay-constrained least-cost multicast routing based on heuristic genetic algorithm[J]. Computer Communications, 2001, 24(7): 685-692.
[9] Liu J, Sun J, Xu W. QoS multicast routing based on particle swarm optimization[C]//LNCS 4224. 2006: 936-943.
[10] JIN Xing, BAI Lin, JI Yue-feng. Probability convergence based particle swarm optimization for multiple constrained QoS multicast routing[C]//2008 Fourth International Conference on Semantics, Knowledge and Grid. Beijing: China; IEEE, 2008: 412-415.
[11] Penev K, Littlefair G. Free-search : A comparative analysis[J]. Information Sciences, 2005, 172: 173-193.
[12] ZHU Guang-yu, WANG Jin-bao, GUO Hong. Research and improvement of free search algorithm[C]//2009 International Conference on Artificial Intelligence and Computational Intelligence. Shanghai, China: IEEE, 2009: 235-239.
[13] Zhou H, Li D M, Shao S H. Novel swarm intelligence algorithm and its improvement[J]. Systems Engineering and Electronics, 2008, 30(2): 337-340.
[14] Waxman B M. Routing of multipoint connections[J]. IEEE Journal on Selected Areas in Communications, 1988, 6(9): 1617-1622.
(Edited by CHEN Can-hua)
Received date: 2011-04-15; Accepted date: 2011-06-15
Foundation item: Project (60774088) supported by the National Natural Science Foundation of China; Project (2009AA04Z132) supported by the National ��863�� Program; Project (20090031110029) supported by the Doctoral Program of National Education Ministry under Grant
Corresponding author: KONG Sun, PhD; Tel: +86-13702090831, E-mail: ksuser@mail.nankai.edu.cn

