J. Cent. South Univ. (2016) 23: 1383-1389
DOI: 10.1007/s11771-016-3190-1
Bag-of-visual-words model for artificial pornographic images recognition
LI Fang-fang(李芳芳), LUO Si-wei(罗四伟), LIU Xi-yao(刘熙尧), ZOU Bei-ji(邹北骥)
School of Information Science and Engineering, Central South University, Changsha 410083, China
 Central South University Press and Springer-Verlag Berlin Heidelberg 2016
Central South University Press and Springer-Verlag Berlin Heidelberg 2016
Abstract: It is illegal to spread and transmit pornographic images over internet, either in real or in artificial format. The traditional methods are designed to identify real pornographic images and they are less efficient in dealing with artificial images. Therefore, criminals turn to release artificial pornographic images in some specific scenes, e.g., in social networks. To efficiently identify artificial pornographic images, a novel bag-of-visual-words based approach is proposed in the work. In the bag-of-words (BoW) framework, speeded-up robust feature (SURF) is adopted for feature extraction at first, then a visual vocabulary is constructed through K-means clustering and images are represented by an improved BoW encoding method, and finally the visual words are fed into a learning machine for training and classification. Different from the traditional BoW method, the proposed method sets a weight on each visual word according to the number of features that each cluster contains. Moreover, a non-binary encoding method and cross-matching strategy are utilized to improve the discriminative power of the visual words. Experimental results indicate that the proposed method outperforms the traditional method.
Key words: artificial pornographic image; bag-of-words (BoW); speeded-up robust feature (SURF) descriptors; visual vocabulary
1 Introduction
With the rapid development of the Internet, people benefit more and more from the sharing of information. However, the proliferations of pornographic images are widely available, which has done great harm to social stability and human’s physical and mental health, especially for adolescents. Therefore, how to identify and filter the pornographic images effectively and automatically is very important [1]. In recent years, some well-known social networks can supervise the releasing of such pictures by criminals automatically. Thus, these criminals turn to release artificial pornographic images in order to escape this kind of supervision.
Artificial pornographic images are produced by computer software and contain exaggerated erotic elements, which are different from real pornographic images. Images in erotic games are belonging to this kind. In the process of releasing information, criminals often mingle normal information with artificial pornographic images to attract users to click, and then bring users into illegal websites. Nowadays, artificial pornographic images become a new way for criminals to escape supervision. Therefore, how to recognize these images becomes an open issue.
There are four categories of methods for the recognition of real pornographic image:
1) Methods based on body structure: the pornographic image recognition based on body structure was proposed by FORSYTH and FLECK in 1996 [2-3]. In this kind of method, skin color regions were detected and the prior body structure information was utilized to organize and combine the identified regions into a body, and thus the pornographic image could be recognized. This kind of method is quite straightforward and easy to be realized. However, as human bodies are non-rigid object and humans have a wide variety of postures, it is difficult to build a comprehensive body grouper effectively. Thus, the recognition accuracy is usually not high [4-5].
2) Methods based on image retrieval: these methods aimed to find the best matching images to those recognized in the pre-classified database, instead of analyzing a certain single image directly [6-7]. If the number of the matched pornographic images from the database exceeded a certain threshold, then the target image would be recognized as a pornographic image. However, the recognition effectiveness relies on the sample database greatly. Since both the pornographic and non-pornographic images have various forms, how to establish a database with complete samples has become an open issue. To improve the recognition accuracy, large numbers of samples are required, which will lead to low recognition speed [5].
3) Methods based on features of skin color region: these methods treat the recognition as the classification problem [8]. The images were classified to be pornographic or normal. In the methods, the features that represent skin information, such as color and texture, were extracted firstly and then the pattern classifier was utilized to determine the recognition results [9-11]. Multi-agent learning neural and Bayesian methods were utilized to extract skin regions in Ref. [12] and the features from the skin were extracted to classify the images into either pornographic or non-pornographic. The most challenging task of those methods is how to extract the effective features for distinguishing the pornographic images from the normal ones. As mentioned above, the pornographic images usually have various forms, and hence it is hard to extract the effective features for representing the pornographic images [5].
4) Methods based on visual words: in recent years, the technology of pornographic images recognition based on visual words has attracted more and more attention and gained enormous popularity in object classification. Inspired by the text content analysis, researchers realized the feasibility to view an image as a word combination, and thus, applied the text analysis method to image semantic annotation, which provides a novel insight into resolving the recognition of pornographic image [13]. In this kind of methods, visual words usually were extracted from images in order to describe the semantics content of images. Afterwards, bag-of-words (BoW) model is introduced to the pornographic image recognition [14]. Visual words and the semantic information of associated tags were used to estimate the relevance scores of user tagged images simultaneously [15-16]. In addition, the BoW model has been developed for more accurate and efficient multimedia tagging, such as tag ranking, tag recommendation, and tag refinement [17]. BoW model was also used to identify pornographic images [18]. Scale invariant feature transform (SIFT) descriptors was used to create visual vocabulary and then pornographic images were identified by using an SVM classifier [19]. Bag-of-visual-words and text information was used in Ref. [20] to detect pornographic images. Instead of SIFT descriptor, SURF (Speeded up robust features) descriptors was used and color information was combined together to construct visual words [21]. Local feature points in sex scene were firstly detected [22] using the SURF [23] descriptors, and then high-level semantic dictionary was constructed. SIFT descriptors was presented in 2004 [24]. Then, a novel scale and rotation invariant interest point detector and descriptor, named SURF was proposed [23-26]. The compare of SURF features with PCA-SIFT was described in Ref. [27]. Their experiments demonstrate that SURF approximates or even outperforms previously proposed schemes in terms of repeatability, distinctiveness, and robustness with much lower computation cost.
The above approaches are mainly for real pornographic images recognition. However, there is no relevant research for artificial pornographic images currently. Moreover, the features of artificial pornographic images are quite different from those of real pornographic images. In particular, the above mentioned methods based on body structure or skin color mostly use skin as important features, which are different in artificial pornographic images. Therefore, those methods are not suitable for the recognition of artificial pornographic images. To solve this problem, a bag-of-visual-words model for artificial pornographic images recognition is proposed in this work. There are four steps in this approach, features extraction, visual vocabulary creation, BoW encoding for image representation and pornographic images recognition. Considering the specific features of artificial pornographic images, SURF is adopt for feature extraction and K-means clustering is adopt for visual words creation. Different from the traditional visual vocabulary creation method, the proposed method sets a weight on each visual word according to the number of features each cluster contains, in order to improve the distinguish abilities between different visual words. Moreover, based on the traditional BoW encoding method, a non-binary encoding method and cross-matching strategy are utilized to make the BoW encoding results contain more original image information. Finally, different machine learning methods are compared and the one with the best results is chosen in our scheme for pornographic images recognition.
2 Artificial pornographic images recognition
The workflow of the approach is shown as Fig. 1.
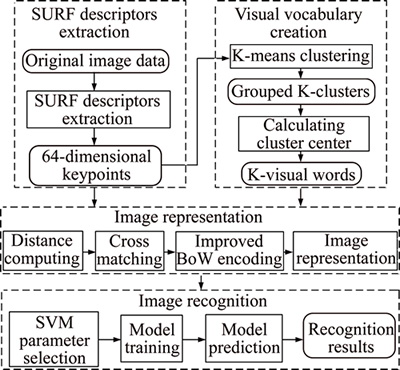
Fig. 1 Workflow of method
In the step of feature extraction, speeded-up robust features (SURF) is adopted to extract artificial pornographic images features, the reason is as follows: artificial pornographic images are made by computer software, therefore, image processing operations and noises are performed and added usually in the production processes, such as size zooming, symmetry transformation, tone changing, image rotation, etc., which leads to high requirement of the feature extraction algorithm in great invariance to the translation, brightness changes, rotation and noise in the image. In addition, information dissemination in social networks has wide range and fast speed, the longer existing of these images will bring about greater harm, which leads to the requirement of high feature extraction speed. SUFR descriptor is adopted in this paper to extract the features of artificial pornographic images due to its strong robustness and low computation cost.
In the phase of visual vocabulary creation, as K-means algorithm has characteristics in fast calculation and simple implementation, and high efficiency for large data sets, etc., it is used as the clustering algorithm. All feature points that extracted by the above phase are grouped by K-means into K clusters and the center of each cluster is viewed as a visual word. In this phase, considering the specific features of artificial pornography images, an improved weights assigning method for visual word is proposed.
In the phase of image representation, in order to obtain the semantic information of the artificial pornographic images as much as possible, an improved BoW encoding algorithm is proposed to represent the images.
Finally, after all images are represented as bag-of-visual-words, whether an image is pornographic or non-pornographic is judged. As SVM classifier has unique advantages in the classification of two categories, it is applied to the image recognition phase.
The following sections will describe each phase in detail.
2.1 SURF descriptors extraction
There mainly exists three robust feature detection methods: SIFT, Principal Component Analysis (PCA)- SIFT and SURF. SIFT presents its stability in most situations although it is slow. PCA-SIFT shows its advantages in rotation and illumination changes. SURF is the fastest one with the similar performances with SIFT. Since the recognition of artificial pornographic images in social network is required to be robustness and real-time, SURF descriptors is adopted in this work to extract features of artificial pornographic images. The feature extracted by SUFR descriptors is a 64-dimensional vector. The detailed algorithm about SURF is described [23-26].
2.2 Visual vocabulary creation
Bag-of-words (BoW) model is commonly used in natural language processing and information retrieval. In this model, a text (such as a sentence or a document) is represented as the bag of its words, disregarding the grammar and word order but keeping its multiplicity. Recently, BoW has also been used for computer vision, such as image classification, which represent an image into a number of visual words. The visual words here are not simply refer to the original image block, but refer to the feature representation of the block due to the following reasons: if a certain pieces of image blocks are used as visual words, then the template matching method has to used to search for each visual word when encoding an image by BoW. On one hand, it is very time consuming. On the other hand, a rotated image which is very common in the artificial pornographic images may not find any matched word, that is, its BoW code may be a zero vector, which is obviously unreasonable. Therefore, the visual word should be some meaningful feature representation of the block, and blocks with similar meanings will have the same feature representations. In this way, each image can be represented as a collection of a number of visual words.
Therefore, after SURF features are extracted from images, bag-of-visual-words are built based on the features. In social networks, there are huge numbers of images with many varieties, hence a complete visual vocabulary for all images could not be created. Since the issue covered in this work is a special classification problem that identifying the artificial pornographic images from all images, we only need to create a visual vocabulary for this particular issue. Therefore, the features of artificial pornographic images in training dataset are used as basic visual words to build visual vocabulary. Detailed steps are shown in Algorithm 1.
Algorithm 1
Step 1: Suppose the training dataset has M artificial pornographic images and extract SURF features for each image Ii (i=1, 2, …, m) in it.
Step 2: Denote the extracted SURF feature set and the number of its elements for each image as Si and ni respectively. Each element is a 64-dimensional vector.
Step 3: Extract n1+n2+…+nm SURF features for all images in the training dataset.
Step 4: Group the SURF features into K clusters using the K-means method.
Step 5: Calculate the center of each cluster to get the result of a 64-dimensional vector, which is viewed as a visual word.
Step 6: Create a visual vocabulary of K visual words for the total training dataset, denote as Ω.
Step 7: Assign the corresponded weight to visual words according to the number of features each cluster contains.
In traditional method, the weight of each visual word is assigned equally the same. In this work, considering that the grouped clusters have different numbers of features and the cluster with more features contains more information about the images and hence have greater distinguish abilities, accordingly, different visual words that generated by the center of different cluster should be assigned different weights. Therefore, in the process of visual vocabulary creation, corresponding weight is assigned to each visual word according to the number of features each cluster contains. Detailed processes are shown in Fig. 2.
2.3 Image representation
After the visual vocabulary is created, all images are then represented by the visual words in the vocabulary. Supposing the visual vocabulary Ω has K visual words, denoted as ω1, …, ωK, and for an image I, its SURF feature set is denoted as S. The image representation based on traditional BoW encoding model is as follows:
2.3.1 Traditional BoW encoding
The encoding results for image I based on traditional BoW model is a K-dimensional vector, denoted as f:
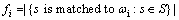 (1)
(1)
where fi is the i-th dimensional value of vector f, which is depending on whether the SURF feature of image I matched with the visual word ωi. If they are matched, it is set to be 1, otherwise it is set to be 0.
As can be seen, the above coding is a kind of binary-coding, that is, whether the feature is matched with the visual word or not. But the match itself is a relatively vague concept, depending on the specific matching rules. For example, supposing the matching SURF feature set is S, and the feature set to be matched is p, a common matching rule is as follows: supposing q and r in S are the most nearest two features from p, if dist(p, q)<0.75×dist(p, r), then p is considered matched with q.
The traditional BoW encoding model is likely to lose some important information, for example, a pair of points with high similarity and another pair of points with relative lower similarity are both considered to be matched points. Furthermore, they are considered haveequal contributions for the encoding and thus their corresponding weights are all set to be 1. On the contrary, a pair of points with large difference and another pair of points with relative smaller difference are both considered mismatched points, they are considered have equal contribution to the encoding and thus their corresponding weights are all set to be 0. Such encoding model can’t reflect the disparity between different degrees of matched pairs. A more precise way should be set different weights to the pairs according to their matched degrees.
2.3.2 Improved BoW encoding
In order to make the BoW encoded results containing more information of the original image, an improved BoW encoding model is proposed in this work. Firstly, the Euclidean distances between feature points (64-dimensional vector) of image I and visual words (64-dimensional vector) are calculated; then cross-matching algorithm is applied to derive the matched pairs of feature point and visual word. Detailed steps are shown in Algorithm 2.
Algorithm 2
Input: 1) Visual vocabulary Ω, which includes k visual words ω1, …, ωK; 2) SURF feature set S of image I, which includes n SURF features s1, …, sn; 3) Parameter m.
Step 1: Calculate the Euclidean distances from each Si(1≤i≤n) in S to each visual word in Ω.
Step 2: Sort the visual words by the distances in an ascending way and select the top m visual words, which is denoted as S2Ωi.
Step 3: Calculate the Euclidean distances from each ωj(1≤j≤k) in Ω to each keypoint in S.
Step 4: Sort the keypoints by the distances in an ascending way and select the top m keypoints, which is denoted as Ω2Sj.
Step 5: If 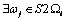 makes
makes 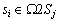 satisfy, denote a matched pair of points (si, ωj).
satisfy, denote a matched pair of points (si, ωj).
Step 6: Repeat the above steps.
Output: The set of all matched pair of points (si, ωj).
Then, for each matched pair, their contributions to BoW encoding is inverse to their Euclidean distance and the higher similarity of the pairs, the greater weights of the visual words in the encoding model. Finally, the image I is encoded according to the BoW model. Detailed steps are shown in Algorithm 3.
Algorithm 3
Input: 1) The set of all matched pair of points (si,ωj); 2) Distance threshold parameters D1, …, DK.
Step 1: Initialize the encoding vector f=(f1, …, fK) to zero vector.
Step 2: For each matched pair of point (si, ωj), if dist(si,ωj)j(1≤j≤k), then fj+=(Dj-dist(si, ωj))/Dj.
Output: BoW encoding vector (f1, …, fK) of image I.

Fig. 2 Process of visual vocabulary creation
2.4 Image recognition
Logistic and SVM classifiers are utilized in the phase of image recognition. Logistic is a traditional pattern recognition method which has been widely used in image classification. Moreover, it is simple to implement and has good stability. SVM is a supervised learning model with associated learning algorithms that analyze data and recognize patterns. Moreover, it has unique advantages in two-category classification problem. LIBSVM [28] software package is used to carry out SVM classification in this work. The default parameters that LIBSVM provided are used during the experiment, and radial basis function is selected as kernel function.
In this phase, Logistic is used firstly to recognize artificial pornographic images under different number of visual words, in order to figure out the best choice of the number of visual words in the recognition process. Secondly, based on the Logistic algorithm and the obtained best choice of number of visual words, comparisons are drawn between the traditional and improved Bow encoding, in order to demonstrate that the improved Bow method is more suitable for image representation. Thirdly, based on the best choice of the number of visual words and the improved Bow method, comparisons are drawn between the Logistic and SVM algorithm, in order to demonstrate which algorithm could achieve better results. Finally, the algorithm with the best result is utilized to artificial pornographic images recognition in this work.
3 Experimental results and analysis
In order to evaluate the performance of the proposed method, the world’s largest Chinese community which named Baidu Post Bar is taken as the data resource. A total number of 9808 images released by its users in 2014 are collected. Among them, 7860 images are selected as training dataset in which 1191 images are artificial pornographic. 1948 images are selected as testing dataset in which 308 images are artificial pornographic. The ratio of normal images to artificial pornographic images is about 6 to 1. Examples of selected images are shown as Fig. 3.
Evaluating indicators including precision (p), recall (r), F1 measure (F1), which are shown as follows. Where System.Correct (CS) is the matching number of recognition results with the manual annotation results, System.Output (OS) is the number of recognition results and Human.Labeled (HL)is the manual annotation results.
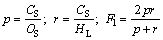 (2)
(2)
Three groups of experiments are established, which are listed in Table 1.
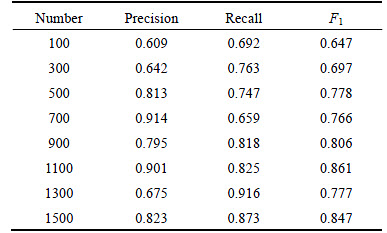
The number of visual words is essential to the image recognition accuracy. Whether the number is too little or too much will reduce the final accuracy. Too little number of visual words will lead to too simple classification model and occur under fitting phenomenon, while too much number will lead to too complex classification model and occur over fitting phenomenon. Table 2 is the experimental results of experiment A. As listed in Table 2, the numbers of visual words that get the top three recall values are 1300, 1500 and 1100, respectively. The number of visual words that get the top three precision values are 700, 1100 and 1500 respectively, and the numbers of visual words that get the top three F1 values are 1100, 1500 and 900, respectively. Since F1 measure is the comprehensive results of precision and recall, the number with the highest F1 value that is 1100, is chosen in our work.

Fig. 3 Examples of artificial pornographic (first row) and non-pornographic images (second row)
Table 1 Three groups of experiments
Table 2 Results under different numbers of visual words
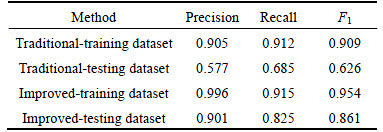
In Experiment B, under the case of 1100 visual words, contrast experiments on the traditional and improved BoW encoding is conducted. As shown in Table 3, the first two rows are the results of the traditional method in the training dataset and the testing dataset respectively and the rest two rows are the results of the improved method in the training dataset and the testing dataset respectively. For the traditional method, although it get high accuracy on the training dataset, it has low results on the testing dataset, which means the traditional method is unstable and the training model appears over fitting phenomenon. For the improved method, its precision, recall and F1 on both the training dataset and testing dataset are very high. Especially, the improved method get 0.825, 0.901 and 0.861, respectively on the testing dataset, which are muchhigher than the traditional method. Those results show that the improved method is more stable and precise.
Table 3 Contrast experiments on traditional and improved Bow
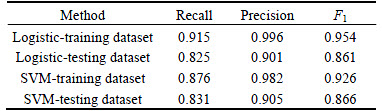
In Experiment C, under the case of 1100 visual words and the improved BoW encoding method, contrast experiments on Logistic and SVM algorithm are established. As listed in Table 4, the precision rates of the two algorithms on testing dataset are both above 0.905, which indicates in most cases the two algorithms can recognize the artificial pornographic images accurately. But the recall rates of the two algorithms on testing dataset are slightly lower, with 0.825 and 0.831 respectively, which indicates that there are still a small part of artificial pornographic images are not recognized. Compared with Logistic algorithm, although SVM get lower results on training dataset, it get higher results on testing dataset, which proves that SVM is more stable and suitable for the recognition of artificial pornographic images, and its generalization ability is stronger than Logistic.
Table 4 Contrast experiments on Logistic and SVM
4 Conclusions and future work
In this work, a new bag-of-visual-words model is proposed for artificial pornographic images recognition. The model has following merits. Firstly, by utilizing the proposed model, the experimental results of precision, recall and F1 reached 0.831, 0.905 and 0.866, respectively, which is better than the traditional method. Secondly, in the visual vocabulary creation process, by placing a weight on each visual word according to the number of features each cluster contains, the distinguish abilities between different visual words is improved. Thirdly, in the image representation process, by applying non-binary encoding and cross-matching algorithm in the improved BoW method, the original image information reserved in the encoding results is enhanced. In the future, we will try to use the method based on multiply features such as color features, texture features and histogram features to further enhance the performance of the recognition for artificial pornographic images.
Acknowledgment
The authors thanks for the support from postdoctoral research station of Central South University, China
References
[1] CHANTRAPORNCHAI C, PROMSOMBAT C. Experimental studies on pornographic web filtering techniques [C]// Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Krabi: IEEE, 2008: 109-112.
[2] FORSYTH D A, FLECK M M. Identifying nude pictures [C]// Proceedings of the 3rd IEEE Workshop on Applications of Computer Vision, Sarasota: IEEE, 1996: 103-108.
[3] FLECK M M, FORSYTH D A, BREGLER C. Finding naked people [C]// Proceedings of European Conference on Computer Vision, Cambridge: Springer, 1996: 593-602.
[4] HU W, WU O, CHEN Z, FU Z, MAYBANK S. Recognition of pornographic web pages by classifying texts and images [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(6): 1019-1034.
[5] ZHUO Li, ZHANG Jing, ZHAO Ying-di, ZHAO Shi-wei. Compressed domain based pornographic image recognition using multi-cost sensitive decision trees [J]. Signal Processing, 2013, 93(8): 2126-2139.
[6] WANG J Z, LI J, WIEDERHOLD G, FIRSCHEIN O. System for screening objectionable images [J]. Computer Communications, 1998, 21(5): 1355-1360.
[7] WANG M, HUA X S. Active learning in multimedia annotation and retrieval: A survey [J]. ACM Transactions on Intelligent Systems and Technology, 2011, 2(2): 10-31.
[8] ZHENG H, DAOUDI M, JEDYNAK B. Blocking adult images based on statistical skin detection [J]. Electronic Letters on Computer Vision and Image Analysis, 2004, 4(2): 1-14.
[9] WANG M, HUA X S, TANG J H, HONG R C. Beyond distance measurement: Constructing neighborhood similarity for video annotation [J]. IEEE Transactions on Multimedia, 2009, 11(3): 465-476.
[10] WANG M, HUA X S, HONG R C, TANG J H, QI G J, SONG Y. Unified video annotation via multi-graph learning [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2009, 19(5): 733-746.
[11] WANG Meng, HUA Xian-sheng, MEI Tao, HONG Ri-chang, QI Guo-jun, SONG Yan, DAI Li-rong. Semi-supervised kernel density estimation for video annotation [J]. Computer Vision and Image Understanding, 2009, 113(3): 384-396.
[12] ZAIDAN A A, AHMAD N N, ABDUL KARIM H, LARBANI M, ZAIDAN B B, SALI A. On the multi-agent learning neural and Bayesian methods in skin detector and pornography classifier: An automated anti-pornography system [J]. Neurocomputing, 2014, 131: 397-418.
[13] ZHANG Jing, SUI Lei, ZHUO Li, LI Zhen-wei, YANG Yun-cong. An approach of bag-of-words based on visual attention model for pornographic images recognition in compressed domain [J]. Neurocomputing, 2013, 110: 145-152.
[14] WANG Yu-shi, LI Yuan-ning, GAO Wen. Detecting pornographic images with visual words [J]. Transactions of Beijing Institute of Technology, 2008, 28(5): 410-413. (in Chinese)
[15] GAO Yue, WANG Meng, ZHA Zheng-jun, SHEN Jia-lie, LI Xue-long, WU Xin-dong. Visual-textual joint relevance learning for tag-based social image search [J]. IEEE Transactions on Image Processing, 2013, 22(1): 363-376.
[16] WANG Meng, YANG Kui-yuan, HUA Xian-sheng, ZHANG Hong-jiang. Towards a relevant and diverse search of social images [J]. IEEE Transactions on Multimedia, 2010, 12(8): 829-842.
[17] WANG Meng, NI Bing-bing, HUA Xian-sheng, CHUA Tat-seng. Assistive tagging: A survey of multi-media tagging with human-computer joint exploration [J]. ACM Computing Surveys, 2012, 44(4): 1-24.
[18] ULGES A, STAHL A. Automatic detection of child pornography using color visual words [C]// Proceedings of the 2011 IEEE International Conference on Multimedia and Expo, Washington D. C: IEEE, 2011: 1-6.
[19] SUI Lei, ZHANG Jing, ZHUO Li, YANG Yun-cong. Research on pornographic images recognition method based on visual words in a compressed domain [J]. IET Image Processing, 2012, 6(1): 87-93.
[20] DONG Kai-kun, GUO Li, FU Quan-sheng. An adult image detection algorithm based on bag-of-visual-words and text information [C]// 10th International Conference on Natural Computation, Xiamen: IEEE, 2014: 556-560.
[21] LIU Y Z, XIE H T. Constructing SURF visual-words for pornographic images detection [C]// Proceedings of the 12th International Conference on Computers and Information Technology, Dhaka: IEEE, 2009: 404-407.
[22] LV Lin-tao, ZHAO Cheng-xuan, SHANG Jing, YANG Y X. Pornographic images filtering model based on high-level semantic bag-of-visual-words [J]. Journal of Computational and Applied Mathematics, 2011, 31(7): 1847-1849.
[23] BAY H, TUYTELAARS T, van GOOL L. SURF: Speeded-up robust features [C]// European Conference on Computer Vision, Graz: Springer, 2006: 404-417.
[24] LOWE D. Distinctive image features from scale-invariant keypoints [J]. International Journal of Computer Vision, 2004, 60(60): 91-110.
[25] KE Y, SUKTHANKAR R. PCA-SIFT: “A More Distinctive Representation for Local Image Descriptors” [C]// Proceedings of Conference on Computer Vision and Pattern Recognition, Washingtion D. C.: IEEE, 2014: 511-517.
[26] BAY H, ESS A, TUYTELAARS T, van GOOL LUC. Speeded-up robust features (SURF) [J]. Computer Vision and Image Understanding, 2008, 110(3): 346-359.
[27] CAO Jian, CHEN Hong-qian, MAO Dian-hui, LI Hai-sheng, CAI Qiang. Survey of image object recognition based on local features [J]. Journal of Central South University: Science and Technology, 2013, 44(S2): 258-262. (in Chinese)
[28] CHANG Chih-Chung,LIN Chih-Jen. LIBSVM―A library for support vector machines [EB/OL]. [2015-11-19]. http://www.csie. ntu.edu.tw/~cjlin/libsvm/.
(Edited by DENG Lü-xiang)
Foundation item: Projects(41001260, 61173122, 61573380) supported by the National Natural Science Foundation of China; Project(11JJ5044) supported by the Hunan Provincial Natural Science Foundation of China
Received date: 2015-06-15; Accepted date: 2015-11-19
Corresponding author: LIU Xi-yao, Lecture, PhD; Tel: +86-15111327037; E-mail: lxyzoewx@csu.edu.cn

