一种基于知识颗粒的高效完备属性约简算法
赵 洁1, 2,肖南峰1
(1. 华南理工大学 计算机科学与工程学院,广东 广州 510641;
2. 广东工业大学 管理学院,广东 广州 510520)
摘 要:为获取高效算法,结合Rough集和粒计算理论,基于知识颗粒设计出获取等价类的算法及计算正区域的等价算法,使用动态SQL语句直接获取已排序的对象集,省略类似算法必需的排序算法,降低了实现的复杂度。给出一种增量式的属性约简算法,设计5种选择属性的新启发策略供算法使用,可避免无用属性入选,更有效去除可省属性及缩减搜索空间等,确保约简算法的完备性,简化了中间步骤,从而保证算法的高效性。理论分析及实验结果表明:采用该约简算法的时间复杂度和实际求解时间均比采用现有算法的时间复杂度和实际求解时间低,并能更好地适应海量数据集的挖掘。
关键词:粒计算;粗糙集;属性约简;启发策略
中图分类号:TP18 文献标志码:A 文章编号:1672-7207(2009)06-1623-07
An efficient and complete attribute reduction algorithm based on knowledge granular
ZHAO Jie1, 2, XIAO Nan-feng1
(1. School of Computer Science and Engineering, South China University of Technology, Guangzhou 510641, China;
2. School of Management, Guangdong University of Technology, Guangzhou 510520, China)
Abstract: To gain an ideal algorithm, based on the theories of rough set and granular computing, the basic algorithms of indiscernibility relation and computing positive region were designed, in which dynamic SQL was used to directly get the sorted object sets so that the sort algorithm was left out. Thus an incremental efficient algorithm for reduction of attributes was proposed, and several heuristic strategies were designed to select attributes to avoid useless attributes selected, wipe off attributes that can be omitted more efficiently and reduce the search space etc, which assured the completeness and simplified the mid result so as to ensure the efficiency. The theoretical analysis and experimental results show that the reduction algorithm is more efficient than the existing ones and more adaptive to very large databases.
Key words: granular computing; rough set; attribution reduction; heuristic strategy
粗糙集(Rough set)理论已广泛应用于人工智能模式识别和数据挖掘等方面。属性约简是Rough集研究的重要内容之一,是指在保证信息系统分类或决策能力不变的条件下,删除条件属性中的冗余属性,从而减少数据挖掘要处理的数据量。粒计算(Granular computing)概念的提出标志着涉及多科学的一个应用研究领域产生。粒计算是模糊信息粒理论的超集,而粗糙集理论和区间计算是粒数学的子集[1]。粒计算主要用于处理不确定的、模糊的、不精确的、部分真的和海量的信息,其基本思想是利用不同粒度的信息进行问题求解[2]。
约简计算已成为粗糙集方法的瓶颈,寻求快速高效的算法具有重大意义。结合粗糙集和粒计算,更容易理解知识的本质,这为属性约简提供了很好的思路,基于此可设计出高效的知识约简算法。目前,属性约简算法的研究焦点集中在2个方面:一是采用何种启发式来选择加入到约简结果集中的属性;二是如何高效地计算核属性,从而提高算法的效率,减小算法的时间空间复杂性。在现有算法中,基于区分矩阵的约简算法时间复杂度一般为O(|A|2|U|2)(|U|为论域U中的个体数目,|A|为属性个数)。当处理海量数据时,算法的速度较慢。而使用重要性作为启发式函数时,时间复杂度一般为O(|A|2|U|lg|U|),当核不存在时,可能影响算法的完备性[2-6]。
本文作者利用粗糙集和粒计算理论,研究现有的属性约简算法,给出等价类和正区域的算法,基于此设计高效完备的属性约简算法,使用多个启发策略,解决使用属性重要度作为启发式函数时效率低的问题,当不存在核时,算法依然具有完备性。
1 基于知识粒的基本算法
1.1 现有算法的分析
本文算法所使用的相关概念见文献[1-4]。求取最小属性约简已被证明是一个NP-Hard问题[5],因此,在属性约简算法中,需要利用启发式选择加入到约简结果集中的属性。目前,属性约简算法中所采用的选择属性的启发式主要有:基于Rough集的属性重要性(或正区域)[6-9],基于分辨矩阵中属性频率[10-11],基于分辨矩阵的分辨函数[12-14],基于信息熵[15]以及基于遗传算法[16]等。以重要度作为属性选择标准的一般算法步骤[2]如下。
输入:信息系统IS=(U, A, V, f);
输出:约简RED(A)。
步骤1 计算核CORE(A): 对"p?A,计算SigA-{p}(p),所有SigA-{p}(p)大于0的属性构成核CORE(A) (CORE(A)可能是空集)。
步骤2 RED(A):=CORE(A)。
步骤3 判断IND(RED(A))=IND(A)是否成立,若成立,则转步骤6,否则,转步骤4。
步骤4 计算所有x?A-RED(A)的值SigRED(A)(x),取x1满足:
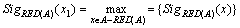 。
。
步骤5 RED(A):RED(A)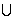 {x1},转步骤3。
{x1},转步骤3。
步骤6 输出最小约简RED(A)。
由该算法可以得到信息系统的最小约简,但不适用于包含决策属性的决策系统,且是非完备的。本文基于知识粒的相关原理,改进该算法,得出新的算法。
1.2 基于知识粒的属性约简算法
从全局考虑,把决策表存储在数据库中。算法中频繁使用的各属性名可通过SQL语句动态获取。算法中动态生成SQL语句,得到已排序的数据集,降低了算法实现的复杂度。下面具体介绍各算法。
1.2.1 获取等价类算法
根据等价类的性质,文献[6]把等价类的算法效率从O(|A||U|2)提高到O(|A||U|log|U|)。本文作者进一步改进得到以下算法。
算法1 计算IND(P)的等价类GPi。
输入:S=(U, A, V, f),U={u1, u2,…, u|U|},P?A。
输出:P对应的分类U/P。
步骤1 接收关于P的属性字符串,形成SQL语句,数据库返回排序后的结果集合U′。
步骤2 index=1, GPindex={u1}。
步骤3 for i=2 to |U| 对U′ do
if (ui与ui-1 每个属性的值均相同)
则GPindex=GPindex{ui}
else index++, GPindex={ui}。
对照现有算法,算法1中的步骤1免除了排序工作,通过动态构造SQL语句访问数据库可直接得到排序的数据集。该算法仅对对象集U扫描1次,进行了|U|-1次比较,每次对比|P|个属性值。由于|P|≤|A|,算法1的时间复杂度为O(|A||U|)。
已知P对应的等价类,求某个对象集X?U的P-下近似或者P-上近似,需要考虑U/P每个信息颗粒GPi与X的关系,需要判断GPi中的记录是否包含在X中,在已知等价类的情况下,算法复杂度为O(|U|)。
由算法1可推出,在信息系统S中,P?A,且X?A,X-的P-下近似和P-上近似、P的核、P的所有约简的时间复杂度分别降到O(|A||U|),O(|A||U|),O(|A|2|U|),O(2|A||A||U|),优于文献[6]各对应算法的O(|A||U||log|U||),O(|A||U||log|U||),O(|A|2|U||log|U||),O(2|A||A||U||log|U||),更优于文献[17-18]各算法对应的效率:O(|A||U|2),O(|A||U|2),O(|A|2|U|2),O(2|A||A||U|2)。
1.2.2 获取正区域的算法
正区域的计算对约简算法是必须的,能否有效计算正区域对整个算法效率的高低有很大影响。通过差别矩阵计算的时间复杂度为O(|C||U|2),其他相关算法的时间复杂度为O(|U|2)[17-18],而这用于海量数据时,这些算法的速度很慢,文献[6]中算法把效率提高到O(|A||U|log|U|)。改进的计算正区域的算法如下。
定理1 对于S=(U, CD, V, f),P?C。GPi?G(P),当且仅当|G(D)(GPi)|=1时,则必有$GDj?G(D),使得GPi?GDj。其中,G(D)(GPi)表示论域GPi的D划分。
证明:反证法,设GPi?G(P),$GDj?G(D),使得GPi?GDj,$um, un?GPi,使um(D) ?un(D)。
由已知$GDi?G(D),即um, un?GDj,而已知|G(D)(GPi)|=1,根据知识粒的定义,任意i, j?{1, 2, …, n},ui, uj?GDj,ui(D)=uj(D),这与假设矛盾,所以,定理成立,定理得证。
定理2 POSC(D)= GCi。其中,POSCi ?G(C)。
GCi。其中,POSCi ?G(C)。
证明:POSC(D)=C_(GDk),其中,GDk?G(D)。由于C_(GDk)={GCj?G(C) GCj?GDk},由定理1必有"GCj?C_(GDk),有|G(D)(GCj)|=1,则C_(GDk)=
GCj?GDk},由定理1必有"GCj?C_(GDk),有|G(D)(GCj)|=1,则C_(GDk)=  GCj,其中j?{1, 2, …, n1},k?{1, 2, …, n2}。故C_(GDk)=
GCj,其中j?{1, 2, …, n1},k?{1, 2, …, n2}。故C_(GDk)= 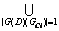 GCi。定理得证。
GCi。定理得证。
算法2 根据定理1和定理2,得到计算正区域的算法。
输入:S=,且P, Q ?A。
输出:POSP(Q)。
步骤1 构造嵌入P和Q的字符串,根据算法1得到U/P={GP1,GP2, …, GPn}, 0<n≤|U|。
步骤2 POSP(Q)=?。
步骤3 for i=1 to |U/P| 对GPi do
If |GPi|=1,则POSP(Q)= POSP(Q)GPi
else {
比较GPi中的第一条记录u0和 最后一条记录uk在Q上的取值
If u0(Q)==uk(Q)
POSP(Q)=POSP(Q)GPi }。
分析算法2的效率,步骤1和算法1中步骤1的复杂度相同,为O(|A||U|)。步骤3的循环时间复杂度为O(|Q||U/P|),其中,|Q|≤|A|,所以,算法2把正域计算的时间复杂度降低到O(|A||U/P|),在最差的情况下,|U/P|=|U|。而实际应用中|U/P|通常远远小于|U|,显然,比文献[6, 17-18]中算法的时间复杂度小。基于此算法,相对约简的复杂度可以分别降低到O(|A|2|U|),O(2|A||A||U|)。
1.2.3 属性约简算法
属性约简是一个NP完全问题,一般采用启发信息找出约简。但很多现有算法不完备,不能保证一定能得到约简[6]。文献[6]中的图1决策表的约简是{b, c},而很多算法得到的约简为{a, b, c},实际上a是可约简的属性。相关算法的效率较低,文献[6]中的完备约简算法的时间复杂度为O(|A|3|U|2),文献[6]中完备算法的时间复杂度为O(|C|2|U|log|U|)。
a. 正粒域的渐增式计算。启发式属性约简算法中,一般采用属性的重要度作为启发信息。在信息系统S=(U, D, V, f)中,属性a?C-R(R?C)对于决策属性集D的重要度SGF(a, R, D)定义为[19]:
SGF(a, R, D)=g(C, D-g(C-{a}), D), g(C, D)=|POSC(D)|/|U|。
可见,计算SGF需要计算正区域,根据算法2,可知计算g(C, D)的时间复杂度为O(|D||U|)。
为实现渐增式算法,很多研究者认为需要额外增加算法。本文解决正区域的渐增不需要增加新算法,仍然使用算法2即可完成。把所需要增加的属性构造成新的字符串,通过参数方式传递到算法2即可完成。此时,计算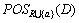 的时间复杂度为O(|D||U/R{a}|),类似前面分析,此时算法复杂度为O(|D||U|),基于此求SGF(a,R,D)的时间复杂度为O(|D||U|),均低于文献[6]的O((|D|+1)U|log|U||)和O((|D|+1)U|log|U||),低于文献[20]中算法的时间复杂度O(|C||U||lg|U||)。可见,本文算法在实现的复杂度及时间复杂度上均比上述文献中的算法低。
的时间复杂度为O(|D||U/R{a}|),类似前面分析,此时算法复杂度为O(|D||U|),基于此求SGF(a,R,D)的时间复杂度为O(|D||U|),均低于文献[6]的O((|D|+1)U|log|U||)和O((|D|+1)U|log|U||),低于文献[20]中算法的时间复杂度O(|C||U||lg|U||)。可见,本文算法在实现的复杂度及时间复杂度上均比上述文献中的算法低。
b. 高效完备的属性约简算法。综合上述算法,给出一种基于知识粒的高效完备算法,并对算法中所使用的启发策略进行详细说明。
算法3 求决策表的某个约简。
输入:信息系统IS=(U, CD, V, f)
输出:约简RED(A)
步骤1 计算核CORE(A): 对"p?A,计算SGF(ai, C, D),所有SGF(ai, C, D)值大于0的属性构成核CORE(A) (CORE(A)可能是空集)。
步骤2 RED(A):=CORE(A)。
步骤3 判断|POSRED(A)(D)|=|POSC(D)|是否成立,若成立,则转步骤6,否则,转步骤4。
步骤4 计算所有x?A-RED(A)的值SGF(x, RED, D),取x1满足:
|POSRED(A)(x1)|=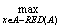 {|POSRED(A)+{x}(x)|}。
{|POSRED(A)+{x}(x)|}。
步骤5 RED(A):=RED(A){x1},转步骤3。
步骤6 在RED(A)的非CORE集合中,从头部开始,从前往后进行检验,直到倒数第2个属性为止。
若|POSC(D)|=|POSRED-{a}(D)|,则从RED中删除a。
步骤7 输出最小约简RED(A)。
c. 约简算法效率分析。文献[6]中的属性约简算法可以确保一定能找到C的某个子集RED,满足|POSC(D)|=|POSRED(D)|,通过最后步骤的后向检验,删除可省的属性,从而确保经过检验处理后的RED中每个属性都是不可省的。基于文献[6]设计出本文的属性约简算法,并对其进行改进,设计出多种启发式策略,提高算法的准确度和效率。
根据多次实验,目前算法3采用策略1、策略2中的2、策略3及策略5。分析算法3,步骤1计算CORE(A),需要计算|POSC(D)| 1次,|POSA-{ai}(D)| |C|次,时间复杂度为O((|C|+1)(|C|+|D|)|U|);步骤4首先需要计算|POSRED(A) |,时间复杂度为O(|C|+|D|)|U|,然后,需要循环计算|C-RED|次SGF(a, RED, D),在最坏的情况下需要执行|C|次,需要计算|C|+|C-1|+…+ 1=|C|(|C|+1)/2次SGF。由于SGF的时间复杂度为O(|D||U|),所以,该循环的实际复杂度为O(|C|2|D||U|)。步骤6在最坏的情况下需要检验|C|个属性,所以,时间复杂度为O(|C|(|C|+|D|)|U|)。在实际应用中,决策属性一般只有1个,即|D|=1,此时,算法3的时间复杂度为O(|C|2|U|)。分析算法的空间复杂度,算法中需要记录多个SGF和正区域值,论域在计算相关数值后即可释放,所以,空间复杂度为O(|U|),大大低于文献[21]中改进差别矩阵的算法的空间复杂度O(|U|2),及文献[6]中的O(|C||U|)。
1.2.4 约简算法中的启发策略分析
现有算法在计算CORE集之后,仅采用属性重要度作为选择下一新属性的启发信息。但当CORE为空集,"ai?C而|POS{ai}(D)|=0时,第1个进入RED集合的属性完全取决于排位,而未必是不可省属性,这将导致最终约简结果错误或者后续工作量增加。
对比算法3和文献[2]中的算法,最主要区别在于步骤6。该步骤实质上是检查RED(A)是否存在可省属性。存在可省属性的情况是由于渐增式选择新属性的启发策略不够完善。这也是很多算法不完备的重要原因。可见,步骤4中属性选择的启发式策略是算法的关键。
策略1 舍弃对|POSRED(A)(D)|没有增益的属性。
当新加入一属性ai,而|POSRED(A)(D)|?|POSC(D)|时,有2种情况:
a. ai?RED(A),属性为|POSRED(A)(D)|带来增益,需要继续增加新属性;
b. ai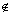 RED(A),该属性并未增加|POSRED(A)(D)|。
RED(A),该属性并未增加|POSRED(A)(D)|。
对情况a,则执行RED(A)=RED(A){ai},转步骤4;对情况b,则直接转步骤4。
为区分上述2种情况,需要记录上一个|POSRED(A)(D)|的值,与|POSRED(A)?{ai} (D)|比较,若两者相等,则按照情况b执行。策略1的优点是:避免无用属性进入RED(A),免除步骤6的多重计算和删除的工作,伪代码如下:
LastPos=|POSC(D)|;
While (|POSRED(A)(D)| ?|POSC(D)|)
{ 在A-RED中按照启发规则选出1个ai,更新|POSRED(A)(D)|;
If(LastPos<| POSRED(D)|)
RED=RED{ai};
LastPos=|POSRED(A)(D)|; }
代码没有增加算法的复杂度,在算法3的步骤4加入即可。
策略2 当CORE(A)=?,且对于"i,|POS{ai}(D)|=0时,采用新启发信息以选择新属性。
当CORE(A)=?,且对于"i,|POS{ai}(D)|=0时,策略1将导致算法失败,影响算法的完备性,此时,所有属性均无法进入RED(A),RED(A)=?。本文提出下面2种策略:
a. 按照文献[2]中粒度的定义计算ai的重要度,必然$ai,使|POS{ai}(D)|?0,此时,策略1可正常运作。
算法4 计算|ai|=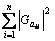 。
。
输入:信息系统IS=(U, A, V, f),属性ai;
输出:|ai|。
步骤1 使用算法1计算U/ai={Gai1, Gai2, …, Gain}。
步骤2 | ai |=0。
步骤3 for i=1 to |U/ai| 对每个Gaii do
|ai|=|ai|+| Gaii|*| Gaii|。
经分析得算法的时间复杂度为O(|U|),根据定义,计算Con(ai?D)需要调用2次算法4,得到|{ai, D}|和|ai|。
b. 在计算|POS{ai}(D)|时,若|G(D)(GPi)|?1,则对|POS{ai}(D)|的计数加1。
当对于GPi,若|G(D)(GPi)|=1,则计数器count=count+|GPi|;若|G(D)(GPi)|?1,则一般算法不进行任何操作,此时,新属性的选择取决于属性的排位,这可能导致后续工作量的增加,或导致结果不准确。在本策略中,若|G(D)(GPi)|?1,则count=count+1,在任何情况下,count?0。当出现CORE(A)=?,且对"i,|POS{ai}(D)|=0时,count记录的是|U/P|。策略不影响SGF的准确性。根据U/P,计算|POSP(Q)|的伪代码如下:
for i=1 to |U/P| 对每个GPi do
if |G(D)(GPi)|=1,则|POSP(D)|= |POSP(D)|+ |GPi|
else |POSP(D)|= |POSP(D)|+1 (与其他算法区别之处)
对比策略2中的2种策略,策略a比策略b要精确,例如,U/D={{1, 2, 3}, {4, 6}, {5, 7}}, U/P1={{1, 4}, {2, 5}, {3, 6, 7}},U/P2={{1, 6}, {2, 3, 5}, {4, 7}},此时|POSP1(D)|=0,|POSP2(D)|=0,按照策略b计算所得的Sig(P1)=7/17,sig(P2)=9/17,显然,P2应该入选。而按照策略b计算时,|U/P1|=|U/P2|,此时,新属性的选择取决于P1和P2的排位。考虑算法的实现,策略a比b复杂度高,策略b只需要在相关算法加入else |POSP(D)|=|POSP(D)|+1即可,没有增加算法的复杂度。从实验数据看,策略a带来的效率提高没有预期的高,这是因为每个属性要增加2次|U|的搜索量,且与决策表的信息有关,需要通过进一步实验来定量分析。而策略b的部分缺陷也可在步骤6中解决,需要增加1次|PosRED(A)-{P1}(D)|的计算量。
策略3 使用前向检验策略。
与文献[6]中的策略相反,前向检验策略更优。算法3中加入步骤6的原因在于非CORE属性的选择策略,由于策略1和2的使用,已避免了大部分无用属性进入RED(A)中,但依然存在启发信息值相同的情况,故第1个非CORE属性的选择决定了最后的约简序列。基于前面分析,据前向的检验方向能够更快地找到可省属性。而此时RED(A)序列中的最后1个属性不需要检验,因为假如该属性可省,则不可能进入RED(A)序列。
策略4 缩减搜索空间。
定理3 $GPi ?G(P),若|G(D)(GPi)|=1,则对于任意"ai?A-P,POSP(D)(GPi)=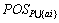 (D)(GPi)。
(D)(GPi)。
证明:由定理1可知,POSP(D)(GPi)=GPi。取任意Ai?A-P,则设G(P{ai})(GPi)={GPi1, GPi2, …, GPn},显然"GPii,|G(D(GPii))|=1,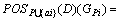 GPi1GPi2…GPn = GPi= POSP(D)(GPi)。定理得证。
GPi1GPi2…GPn = GPi= POSP(D)(GPi)。定理得证。
由定理3可知,对于符合条件的 GPi,GPi?GD(P),若|G(D)(GPi)|=1,增加的属性并未在GPi上对正域产生新的增益。所以,可通过删减ui? GPi来缩减搜索空间。此策略可在RED(A) ??时采用。算法如下。
算法5 求精简后的RED(A)等价类。
输入:信息系统IS=(U, A, V, f),RED(A);
输出:缩小后的搜索空间。
步骤1 当前RED(A) ??,根据算法1获得U/RED(A)。
步骤2 for i=1 to |U/RED(A)| 对GREDi do
if |G(D)(GPi)|=1,删除当前GREDi。
类似算法3的分析,分析使用算法5后求约简的时间复杂度。假设每次增加的属性最终把论域划分成|RED|个,每次论域的大小为U1, U2, …, U|RED|,此时时间复杂度为(|C|+|D|)|U|+(|C|+|D|)|U1|+(|C|+|D|)|U2|+…+(|C|+|D|)|U|RED||=(|C|+|D|)|U|+(|C|+|D|)(|U1|+|U2|+…+ |U||RED|)。其中,|RED|≤|C|。所以,(|C|+|D|)|U|+(|C|+|D|) (|U1|+|U2|+…+|U||RED|)≤(|C|+|D|)|U|+(|C|+|D|)|C||U|= (|C|+1|)(|C|+|D|)|U|。从理论上讲,该策略可使效率提高,但通过实际实验发现,该算法实现复杂度较高,且效率提高幅度没有要求的高,需要进一步通过实验进行量化分析。
策略5 减少不必要的|POSRED(A+{x})(D)|计算。
当求出CORE(A)以后,需要对剩余属性逐一计算|POSRED(A+{x})(x)|。而实际上,当|剩余属性|≤2时,对剩余的任一属性的正域计算都是对|POSA-{ai}(D)|的重复。所以,在算法3中只需要加入1个判断,即可减少不必要的计算量。
3 实验结果
选用文献[6]中的决策表和UCI机器学习数据库中的6个决策表在1.83GHZ Duo CPU,1.49G内存,WINXP 的Notebook上进行实验,数据库采用SQL SERVER2005,与分别采用算法a[8]和算法b[6]的约简算法进行对比,实验结果如表1和表2所示。
表1 约简算法比较
Table 1 Comparison of reduction algorithm

表2 算法约简中间效果比较
Table 2 Comparison of intermediate result

从表1可见:对文献[6]中决策表进行约简,当核不存在时,算法a不完备,算法b和算法3仍具完备性。当数据量较小时,算法3的效率与算法b无明显区别,2个算法的效率明显比算法a的效率高。当数据量较大时,算法a效率急剧降低,算法b和算法3更适用于大型数据分析,而算法3又优于算法b,并在大多数情况下能得到最小约简。从表2可见:检验RED(A)前,算法b的中间结果含有较多无用属性,仍需较多后续工作才能得到目标约简结果,而由于多项启发策略的使用,算法3的中间结果明显优算法b,从而后续步骤处理更为高效、简便,免除了大量重复工作,进一步验证了上述多项启发策略的有效性及正确性。
4 结 论
a. 综合粗糙集和粒计算理论,给出计算等价类、正区域的基础算法。充分利用数据库软件,使用动态SQL语句直接获取已排序的对象集,省略了类似算法必需的排序算法,设计及实现的复杂度较低。
b. 设计出一种增量式的属性约简算法,将多种基于知识颗粒理论的启发策略应用于算法,包括拒绝无用属性入选、采用协调度等启发信息选择属性、使用前向策略舍弃可省属性、缩减搜索空间及减少不必要计算,获得的中间结果比采用一般算法所得结果更简单,简化了后继工作,保证高效性,当不存在核时,该算法仍保持完备性,在大多数情况下能获得最小属性约简。
c. 这些启发策略正确有效,对算法的高效完备性具有重大意义。算法1、算法2和算法3的时间复杂度分别为O(|A||U|),O(|A||U|)和O(|C|2|U|),本文提出的算法在理论上的时间复杂度和实际运行上的速度均比现有算法的低,尤其适用于大型的数据集。
参考文献:
[1] Zadeh L A. Some reflections on soft computing, granular computing and their roles in the conception, design and utilization of information/intelligent systems[J]. Soft Computing, 1998, 2(1): 23-25.
[2] 苗夺谦, 王国胤, 刘 清, 等. 粒计算: 过去、现在与展望[M]. 北京: 科学出版社, 2007: 142-156.
MIAO Duo-qian, WANG Guo-yin, LIU Qian, et al. Past, future and prospect of granular computing[M]. Beijing: Science Press, 2007: 142-156.
[3] 苗夺谦, 范世栋. 知识的粒度计算及其应用[J]. 系统工程与实践, 2002(1): 48-56.
MIAO Duo-qian, FAN Shi-dong. The calculation of knowledge granulation and its application[J]. Systems Engineering: Theory & Practice, 2002(1): 48-56.
[4] Yao Y Y. Granular computing[C]//Special Transaction in the 4th Chinese National Conference on Rough Sets and Soft Computing (CRSSC’2004). Zhoushan, 2004: 1-4.
[5] Wong S K M, Ziarko W. On optimal decision rules in decision table[J]. Bulletin of Polish Academy of Science, 1985, 33(11/12): 693-696.
[6] 刘少辉, 盛秋戬, 吴 斌, 等. Rough集高效算法的研究[J]. 计算机学报, 2003, 26(5): 524-529.
LIU Shao-hui, SHENG Qiu-jian, WU Bin, et al. Research on efficient algorithms for rough set methods[J]. Chinese Journal of Computer, 2003, 26(5): 524-529.
[7] 杜金莲, 迟忠先, 翟 巍. 基于属性重要性的逐步约简算法[J]. 小型微型计算机系统, 2003, 24(6): 976-978.
DU Jin-lian, CHI Zhong-xian, ZHAI Wei. An improved algorithm for reduction of knowledge based on significance of attributes[J]. Journal of Chinese Computer Systems, 2003, 24(6): 976-978.
[8] 王 珏, 王 任, 苗夺谦, 等. 基于Rough set理论的“数据浓缩”[J]. 计算机学报, 1998, 21(5): 393-399.
WANG Jue, WANG Ren, MIAO Duo-qian, et al. Data enriching based on rough set theory[J]. Chinese Journal of Computer, 1998, 21(5): 393-399.
[9] Guan J W, Bell D A. Rough computational methods for information system[J]. Artificial Intelligence, 1998, 105(1/2): 77-103.
[10] Beynon M, Curiy B, Morgan P. Classification and rule induction using rough set theory[J]. Export System, 2000, 17(3): 136-148.
[11] Bazan J G, Skowron A, Syna P. Dynamic reducts as a tool for extracting laws from decisions tables: Methodologies for intelligent systems[M]. Berlin: Springer-Verlag, 1994: 346-355.
[12] 常犁云, 王 国, 吴 渝. 一种基于Rough集理沦的属性约简及规则提取方法[J]. 软件学报, 1999, 11(10): 1206-1211.
CHANG Li-yun, WANG Guo, WU Yu. An approach for attribute reduction and rule generation based on rough sets theory[J]. Journal of Software, 1999,11(10): 1206-1211.
[13] Bakar A A, Sulaiman M N, Othman M, et al. Propositional satisfiability algorithm to find minimal reducts for data m1n1ng[J]. International Journal of Computer Math, 2002, 79(4): 379-389.
[14] QU Bin-bin, LU Yan-sheng. Arough sets and genetic based approach for rule induction[C]//The Fifth World Congress on Intelligent Control and Automation. Hangzhou, 2004: 4300-4303.
[15] 苗夺谦, 胡桂荣. 知识约简的一种启发式算法[J]. 计算机研究与发展, 1999, 36(6): 489-504.
MIAO Duo-qian, HU Gui-rong. A heuristic algorithm for reduction of knowledge[J]. Journal of Computer Research and Development, 1999, 36(6): 681-684
[16] 王文辉, 周东华. 基于遗传算法的一种粗糙集知识约简算法[J]. 系统仿真学报, 2001, 13(Suppl): 93-96.
WANG Wen-hui, ZHOU Dong-hua. An algorithm for knowledge reduction in rough sets based on genetic algorithm[J]. Journal of System Simulation, 2001, 13(Suppl): 93-96.
[17] 张文修, 吴伟志, 梁吉业, 等. Rough集理论与方法[M]. 北京: 科学出版社, 2001: 58-89.
ZHANG Wen-xiu, WU Wei-zhi, LIANG Ji-ye, et al. Theory and method of rough set[M]. Beijing: Science Press, 2001: 58-89.
[18] Guan J W, Bell D A. Rough computational methods for information systems[J]. Artificial Intelligences, 1998, 105(1/2): 77-103.
[19] 陈文伟. 数据仓库与数据挖掘教程[M]. 北京: 清华大学出版社, 2006: 163-174.
CHEN Wen-wei. Tutorial of data warehouse and data mining[M]. Beijing: Tsinghua University Press, 2006: 163-174.
[20] 傅 明, 陈 曦, 刘翌南. 基于信息颗粒的粗糙集约简研究[J]. 长沙理工大学学报: 自然科学版, 2004, 1(1): 80-85.
FU Ming, CHEN Xi, LIU Yi-nan. Reduction based on information granule[J]. Journal of Changsha University of Science and Technology: Natural Science, 2004, 1(1): 80-85.
[21] 丁 军, 李 凡, 冯嘉礼. 一种快速属性约简算法[J]. 华中科技大学学报: 自然科学版, 2006, 34(8): 40-42.
DING Jun, LI Fan, FENG Jia-li. Speeded attribute reduce algorithm[J]. Journal of Huazhong University of Science and Technology: Nature Science, 2006, 34(8): 40-42.
收稿日期:2008-12-01;修回日期:2009-04-05
基金项目:国家自然科学基金委员会与中国民用航空总局联合资助项目(60776816);广东省自然科学基金重点资助项目(8251064101000005);广东省科技计划项目(2007B060401007);广东工业大学青年基金资助项目(072058)
通信作者:赵 洁(1979-),女,广东肇庆人,博士研究生,讲师,从事智能计算,电子商务研究;电话:13503030919;E-mail: kitten-zj@163.com

