Т»ЦЦБӘәПУЕ»ҜЛг·Ёј°ЖдФЪ»мгзКұјдРтБРФӨІвЦРөДУҰУГ
ПтІэКў1Ј¬ЦЬЧУУў2
(1. әюДПЕ©ТөҙуС§ ¶«·ҪҝЖјјС§ФәЈ¬әюДП іӨЙіЈ¬410128Ј»
2. әюДПЕ©ТөҙуС§ ЧКФҙ»·ҫіС§ФәЈ¬әюДП іӨЙіЈ¬410128)
ХӘТӘЈәОӘБЛМбёЯ»мгзКұјдРтБРФӨІвҫ«¶ИЈ¬АыУГПаҝХјдЦШ№№әНФӨІвДЈРНІОКэјдөДПа»ҘБӘПөЈ¬МбіцТ»ЦЦ»щУЪТЕҙ«Лг·ЁөД»мгзКұјдРтБРІОКэБӘәПУЕ»Ҝ·Ҫ·ЁЎЈёГ·Ҫ·ЁКЧПИҪ«ПаҝХјдЦШ№№әНФӨІвДЈРНІОКэЧчОӘТЕҙ«Лг·ЁөДёцМеЈ¬»мгзКұјдРтБРФӨІвҫ«¶ИЧчОӘККУҰ¶ИәҜКэЈ¬НЁ№эСЎФсЎўҪ»ІжәНұдТмөИТЕҙ«ІЩЧч»сөГЧоУЕІОКэЈ¬ЧоәуАыУГ»мгзКұјдРтБРКөАэ¶ФБӘәПУЕ»Ҝ·Ҫ·ЁҪшРРСйЦӨРФІвКФЎЈКөСйҪб№ыұнГчЈәПа¶ФУЪҙ«НіІОКэУЕ»Ҝ·Ҫ·ЁЈ¬БӘәПУЕ»Ҝ·Ҫ·Ёҙу·щ¶ИМбёЯ»мгзКұјдРтБРөДФӨІвҫ«¶ИЈ¬ОӘ»мгзКұјдРтБРФӨІвМṩһЦЦРВөДЛјВ·ЎЈ
№ШјьҙКЈә»мгзКұјдРтБРЈ»ПаҝХјдЦШ№№Ј»Ц§іЦПтБҝ»ъЈ»ТЕҙ«Лг·Ё
ЦРНј·ЦАаәЕЈәTP393 ОДПЧұкЦҫВлЈәA ОДХВұаәЕЈә1672-7207(2012)02-0581-07
A joint optimization algorithm and its application in chaotic time series prediction
XIANG Chang-sheng1, ZHOU Zi-ying2
(1. College of Orient Science and Technology, Hunan Agricultural University, Changsha 410128, China;
2. College of Resources and Environment, Hunan Agricultural University, Changsha 410128, China)
Abstract: To improve the prediction precision of the chaotic time series, a joint optimization algorithm for chaotic time series parameters was proposed based on the genetic algorithm, using the relationship between the phase space reconstruction and prediction model parameters. Firstly, the phase space reconstruction and prediction model parameters were taken as genetic algorithm individuals while the prediction accuracy of the chaotic time series was taken as the evaluation function of genetic algorithm. Secondly, the optimization parameters were obtained by selection, crossover and mutation of genetic algorithm. Finally, the joint optimization algorithm was tested by chaotic time series. The results show that the joint optimization algorithm improves the prediction precision compared with the traditional parameters optimization algorithm, and provides a new way for the chaotic time series prediction.
Key words: chaotic time series; phase space reconstruction; support vector machine; genetic algorithm
»мгзКұјдРтБРФӨІв№г·әУҰУГУЪРЕәЕҙҰАнЎўЧФ¶ҜҝШЦЖЎўҪрИЪәНёәәЙФӨІвөИБмУтЈ¬ЖдЦчТӘ°ьАЁПаҝХјдЦШ№№ЎўФӨІвДЈРНСЎФсТФј°ФӨІвДЈРНІОКэУЕ»ҜөИОКМв[1]ЎЈНЁ№эПаҝХјдЦШ№№И·¶ЁЧојССУіЩКұјд(ҰУ)әНЗ¶ИлО¬(m)Ј¬НЪҫт»мгзКұјдРтБРКэҫЭјдөДРЕПўБҝЈ¬»Цёҙ»мгзКұјдРтБРФӯ¶ҜБҰПөНіЎЈФӨІвДЈРНёщҫЭЦШ№№әуөДКэҫЭҪшРРС§П°УлҪЁДЈЈ¬¶ФОҙАҙКұҝМөДЦөҪшРРФӨІв[2]ЎЈПаҝХјдЦШ№№ЦКБҝЦұҪУУ°ПмФӨІвДЈРНөДҪЁБўУлФӨІвҪб№ыЈ¬ЦчТӘУРЧФПа№ШБӘәҜКэ·Ё[3]ЎўC-C·Ё(Coupled cluster method)[4]әНКұјдҙ°ҝЪ ·Ё[5]өИЈ¬ХвР©·Ҫ·ЁРФДЬөДУЕБУТтКэҫЭІ»Н¬¶шёчТмЈ¬ЗТЕР¶ПұкЧјҫЯУРТ»¶ЁЦч№ЫЛжТвРФЈ¬ҝЙјыЈ¬ДҝЗ°Иұ·ҰТ»ЦЦНЁУГРФҪПЗҝөДЧојСҰУәНmөДСЎФс·Ҫ·Ё[6]ЎЈҪПіЈУГөД»мгзКұјдРтБРФӨІвЛг·ЁУРИ«Ут·ЁЎўҫЦУт·ЁЎўЙсҫӯНшВзәНЦ§іЦПтБҝ»ъөИ[7-9]ЎЈЧоРЎ¶юіЛЦ§іЦПтБҝ»ъ(least square support vector machinesЈ¬LSSVM)КЗТ»ЦЦ»щУЪҪб№№·зПХЧоРЎ»ҜФӯФтөД»ъЖчС§П°Лг·ЁЈ¬ҪПәГөШҪвҫцБЛ·ЗПЯРФЎўёЯО¬КэәНҫЦІҝј«РЎөИДСМвЈ¬·ә»ҜДЬБҰҪПЗҝЈ¬ҝЛ·юБЛЙсҫӯНшВзөД№эДвәПИұПЭЈ¬ФЪ»мгзКұјдРтБРФӨІвСРҫҝЦРИЎөГәЬәГөДУҰУГР§№ы[10]ЎЈОӘҙЛЈ¬ұҫСРҫҝСЎФсLSSVMЧчОӘ»мгзКұјдРтБРөДФӨІвДЈРНЎЈLSSVMДЈРНІОКэҫц¶ЁБЛLSSVMөДС§П°әН·ә»ҜДЬБҰЈ¬ө«ёчІОКэСЎФсИұ·ҰНіТ»ұкЧјәНАнВЫЦёөјЈ¬ёчЦЦІОКэУЕ»ҜЛг·ЁРФДЬІоТмәЬҙуЈ¬ДҝЗ°ЙРОҙУРТ»ЦЦНЁУГІОКэУЕ»Ҝ·ЁФтҝЙ№©ІОҝјЈ¬LSSVMІОКэөДСЎФсКЗТ»ёцЙРҙэҪвҫцөДДСМв[11]ЎЈҰУЈ¬mУлLSSVMДЈРНІОКэПа»ҘЦЖФјЈ¬Н¬Кұҫц¶ЁБЛ»мгзКұјдРтБРөДФӨІвҫ«¶ИЈ¬УҰБӘәПУЕ»ҜЈ¬ө«ПЦУР»мгзКұјдРтБРФӨІв·Ҫ·ЁөДёчІОКэУЕ»Ҝ¶јКЗ¶АБў·ЦҝӘҪшРРЈ¬әцВФІОКэјдПа»Ҙ№ШБӘЎЈХл¶ФёГИұПЭЈ¬ұҫОДЧчХЯМбіцТ»ЦЦ»щУЪТЕҙ«Лг·Ё(genetic algorithmЈ¬GA)өДІОКэБӘәПУЕ»Ҝ·Ҫ·Ё(GA-LSSVM)Ј¬ІўНЁ№э»мгзКұјдРтБРКөАэ¶ФЖдРФДЬҪшРРСйЦӨЎЈ
1 ПаҝХјдЦШ№№әНЧоРЎ¶юіЛЦ§іЦПтБҝ»ъАнВЫ
1.1 »мгзКұјдРтБРөДПаҝХјдЦШ№№
ПаҝХјдЦШ№№°СҫЯУР»мгзМШРФөДКұјдРтБРЦШ№№іЙОӘТ»ЦЦөНҪЧ·ЗПЯРФ¶ҜБҰС§ПөНіЈ¬ҙУ¶шҪьЛЖ»ЦёҙПөНіөД»мгзОьТэЧУ[12]ЎЈ
Йи№ЫІвөҪөД»мгзКұјдРтБРОӘЈә{x(t)}(ЖдЦРЈәt=1Ј¬2Ј¬ЎӯЈ¬nЈ»nОӘСщұҫКэ)ЎЈёщҫЭTakens¶ЁАнЈ¬ҝЙТФНЁ№эСЎ¶ЁәПККөДҰУәНmҪ«»мгзКұјдРтБРКұјдЦШ№№ОӘЈә
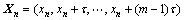 (1)
(1)
ҙУКҪ(1)ҝЙЦӘЈәПаҝХјдЦШ№№Ҫб№ыөДУЕБУУЙҰУәНmҫц¶ЁЎЈёщҫЭTakens¶ЁАнЈ¬¶ФУЪОЮПЮіӨәНОЮФлЙщөД»мгзКұјдРтБРЈ¬ҰУҝЙТФИОТвСЎФсЈ¬јҙУлmГ»УР№ШБӘЎЈө«КөјКЙПКұјдРтБРІ»ҝЙұЬГвөШҙшУРФлТфЗТІ»ДЬұЈЦӨРтБРіӨ¶ИЧг№»іӨЈ¬ТтҙЛЈ¬ФЪКөјКУҰУГЦРҰУөДСЎИЎ¶ФПаҝХјдЦШ№№өДЦКБҝУРЧЕЦШТӘөДУ°ПмЈ¬ҰУәНmПа»Ҙ№ШБӘЈ¬ТтҙЛЈ¬УҰёГН¬КұСЎФсЎЈ
1.2 ЧоРЎ¶юіЛЦ§іЦПтБҝ»ъ
УЙУЪЦ§іЦПтБҝ»ъөДёҙФУ¶ИУлКдИлҝХјдөДО¬КэОЮ№ШЈ¬¶шТААөУЪСщұҫКэҫЭөДёцКэЈ¬ТтҙЛЈ¬СщұҫКэДҝФҪҙуЈ¬ЗуҪвПаУҰөД¶юҙО№ж»®ОКМвФҪёҙФУЈ¬јЖЛгЛЩ¶ИФҪВэЈ¬Ҫш¶шПЮЦЖЦ§іЦПтБҝ»ъөДУҰУГ·¶О§[13]ЎЈSuykensөИФЪұкЧјЦ§іЦПтБҝ»ъөД»щҙЎЙПМбіцБЛЧоРЎ¶юіЛЦ§іЦПтБҝ»ъ(LSSVM)Ј¬Ҫ«ұкЧјЦ§іЦПтБҝ»ъРНЦРөДЛрК§әҜКэЙи¶ЁіЙОуІоЖҪ·ҪәНЈ¬°СІ»өИКҪФјКшёДіЙөИКҪФјКшЈ¬јхЙЩҙэ¶ЁІОКэЈ¬УЦҪ«ЗуҪв¶юҙО№ж»®өДОКМвЧӘ»ҜіЙПЯРФKKT (karush kuhn kucker)·ҪіМЧйөДЗуҪвЈ¬ҪөөНБЛЗуҪвөДёҙФУРФЈ¬НШҝнБЛЦ§іЦПтБҝ»ъөДУҰУГҝХјд[14]ЎЈ
¶ФУЪСөБ·СщұҫјҜ{(xiЈ¬yi)}Ј¬(i=1Ј¬2Ј¬ЎӯЈ¬n)Ј¬xiәНyi·ЦұрұнКҫСщұҫКдИләНКдіцЈ¬ Ј¬НЁ№э·ЗПЯРФУіЙдәҜКэҰХ(ЎӨ)Ҫ«СщұҫУіЙдөҪёЯО¬МШХчҝХјдЈ¬ҙУ¶ш»сөГЧоУЕПЯРФ»Ш№йәҜКэЈә
Ј¬НЁ№э·ЗПЯРФУіЙдәҜКэҰХ(ЎӨ)Ҫ«СщұҫУіЙдөҪёЯО¬МШХчҝХјдЈ¬ҙУ¶ш»сөГЧоУЕПЯРФ»Ш№йәҜКэЈә
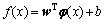 (2)
(2)
КҪЦРЈәwОӘМШХчҝХјдөДИЁЦөПтБҝЈ»bОӘЖ«ЦГБҝЎЈ
ёщҫЭҪб№№·зПХЧоРЎ»ҜФӯФтЈ¬КҪ(2)ОКМвЗуҪвөДLSSVM»Ш№йДЈРНОӘЈә
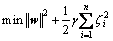 (3)
(3)

КҪЦРЈәҰГОӘіН·ЈІОКэЈ¬УГУЪЖҪәвСөБ·ОуІоәНДЈРНёҙФУ¶ИЈ»eiОӘКөјКЦөУл»Ш№йәҜКэјдөДОуІоЎЈ
НЁ№эТэИлАӯёсАКИХіЛЧУ(Lagrange multiplier)Ҫ«ЙПКцФјКшУЕ»ҜОКМвЧӘұдОӘОЮФјКш¶ФЕјҝХјдУЕ»ҜОКМвЈ¬јҙЈә
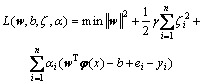 (4)
(4)
КҪЦРЈәҰБiОӘАӯёсАКИХіЛЧУЎЈ
ёщҫЭMercerМхјюЈ¬әЛәҜКэ¶ЁТеИзПВЈә
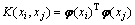 (5)
(5)
ұҫСРҫҝСЎФсҫ¶Пт»щәЛәҜКэЧчОӘLSSVMәЛәҜКэЈ¬ҫ¶Пт»щәЛәҜКэОӘЈә
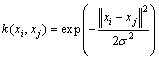 (6)
(6)
ЧоәуLSSVM»Ш№йДЈРНОӘЈә
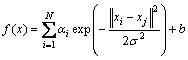 (7)
(7)
ЖдЦРЈәҰТұнКҫҫ¶Пт»щәЛКэҝн¶ИЎЈ
УЙЙПКцLSSVM»Ш№йҪЁДЈ№эіМҝЙЦӘЈ¬»щУЪҫ¶Пт»щәЛәҜКэөДLSSVMС§П°РФДЬЦчТӘИЎҫцУЪҰГәНҰТЎЈ
2 У°Пм»мгзКұјдРтБРФӨІвҪб№ыөДІОКэ·ЦОц
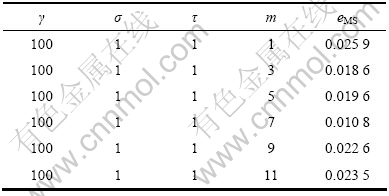
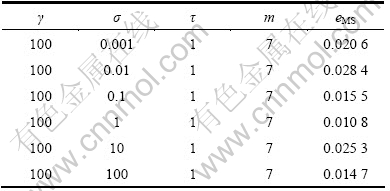
»щУЪLSSVMөД»мгзКұјдРтБРФӨІвДЈРНРиТӘУЕ»ҜөДІОКэОӘҰУЈ¬mЈ¬ҰГәНҰТЎЈұн1~4ЛщКҫ·ЦұрұнКҫН¬Т»»мгзКұјдРтБР(Mackey-Glass)ФЪІ»Н¬ІОКэПВөДФӨІвҫ«¶ИұИҪПҪб№ыЎЈ
НЁ№э¶Фұн1~4Ҫб№ыҪшРРұИҪПҝЙЦӘЈәПаҝХјдЦШ№№(ҰУәНm)әНLSSVMІОКэ(ҰГәНҰТ)¶ФФӨІвҪб№ыөДУ°ПмҫщәЬҙуЈ¬ЗТ¶юХЯ»ҘПа№ШБӘЈ¬И»¶шҙ«НіЛг·ЁҪ«БҪХЯ·ЦҝӘөҘ¶АҪшРРУЕ»ҜЈ¬ёоБСБЛБҪХЯјдөДБӘПөЈ¬ХвСщҫНҙжФЪОЮ·ЁИ·¶ЁПИУЕ»ҜҰУәНm»№КЗҰГәНҰТөДИұПЭЈ¬ЗТУЕ»ҜЖдЦРТ»ёцКұРиЛж»ъөШИ·¶ЁБнТ»ёцЈ¬ХвСщјҙК№ВЦБчҪшРРУЕ»ҜТІІ»ДЬұЈЦӨБҪХЯН¬КұҙпөҪЧоУЕЈ¬өјЦВУРКұФӨІвР§№ыІ»Ан Пл[15]ЎЈОӘБЛ»сөГЧоУЕөД»мгзКұјдРтБРФӨІвҪб№ыЈ¬ҫНРиТӘК№ҰУЈ¬mЈ¬ҰГәНҰТН¬КұҙпөҪЧоУЕЈ¬ТтҙЛЈ¬ЛьГЗУҰёГҪшРРБӘәПУЕ»ҜЎЈ
ұн1 m¶ФФӨІвҫ«¶ИөДУ°Пм
Table 1 Influence of m on prediction precision
ұн2 ҰУ¶ФФӨІвҫ«¶ИөДУ°Пм
Table 2 Influence of ҰУ on prediction precision
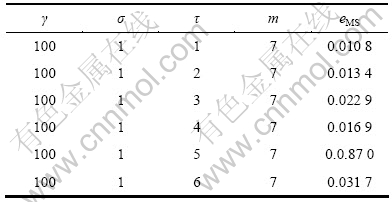
ұн3 ҰГ¶ФФӨІвҫ«¶ИөДУ°Пм
Table 3 Influence of ҰГ on prediction precision
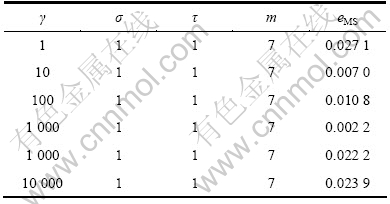
ұн4 ҰТ¶ФФӨІвҫ«¶ИөДУ°Пм
Table 4 Influence of ҰТ on prediction precision
3 ІОКэБӘәПУЕ»ҜЙијЖ
ҰУЈ¬mЈ¬ҰГәНҰТөДБӘәПУЕ»ҜПФИ»КЗТ»ёц¶аІОКэЧйәПУЕ»ҜОКМвЈ¬Из№ыІЙИЎЗоҫЩ·ЁҪшРРЗуҪвЈ¬јЖЛгБҝҪ«К®·ЦҫЮҙуТФЦБУЪУРКұОЮ·ЁКөПЦЈ¬ОӘБЛјхЙЩІОКэУЕ»ҜёҙФУ¶ИЈ¬ҙ«НіЙПКЗТАҙОХТөҪГҝёцІОКэөДЧојСЛ®ЖҪЈ¬Ҫ«¶аІОКэУЕ»ҜОКМвЧӘ»ҜОӘөҘІОКэУЕ»ҜОКМвЈ¬әцВФБЛІОКэЦ®јдөДҪ»»ҘЧчУГЈ¬ТтҙЛЈ¬Ҫ«ГҝёцІОКэөДЧојСЛ®ЖҪЧйәПФЪТ»ЖрОҙұШКЗИ«ҫЦЧоУЕІОКэЧйәПЎЈGAАыУГЙъОпТЕҙ«С§өД№ЫөгЈ¬НЁ№эЧФИ»СЎФсЎўҪ»»»әНұдТмөИ»ъЦЖКөПЦЦЦИәөДҪш»ҜЈ¬ҫЯУРТюә¬өДІўРРРФәНЗҝҙуөДИ«ҫЦЛСЛчДЬБҰЈ¬ҝЙТФФЪҪП¶МКұјдДЪЛСЛчөҪИ«ҫЦЧоУЕҪв[16]ЎЈТтҙЛЈ¬ұҫСРҫҝІЙУГGA¶ФҰУЈ¬mЈ¬ҰГәНҰТҪшРРБӘәПУЕ»ҜЎЈ
3.1 ёцМеұаВлУлЙијЖ
ёцМеІЙУГ¶юҪшЦЖұаВл·ҪКҪЈ¬УЙУЪСЎФсҫ¶Пт»щәЛәҜКэЧчОӘLSSVMәЛәҜКэЈ¬ТтҙЛЈ¬GAёцМеУЙҰУЈ¬mЈ¬ҰГәНҰТ 4Іҝ·ЦЧйіЙЎЈёцМеөДЗ°aО»ҙъұнҰУЈ¬ЦРјдbО»ҙъұнmЈ¬ЦРјдcО»ҙъұнҰГЈ¬ЧоәуdО»ҙъұнҰТЈ¬ИзНј1ЛщКҫЎЈ

Нј1 ёцМеЙијЖ
Fig.1 Design of individuals
ёцМеЦРөДёчО»¶юҪшЦЖҙ®НЁ№эКҪ(8)ЧӘ»»ОӘК®ҪшЦЖұнКҫөДДЈРНКөјКІОКэЎЈ
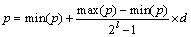 (8)
(8)
КҪЦРЈәpОӘІОКэөДК®ҪшЦЖЦөЈ»min(p)ОӘІОКэөДЧоРЎЦөЈ¬max(p)ОӘІОКэөДЧоҙуЦөЈ»lОӘІОКэөД¶юҪшЦЖО»ҙ®іӨ¶ИЈ»dОӘІОКэөД¶юҪшЦЖО»ҙ®өДК®ҪшЦЖЦөЎЈ
3.2 ЦЦИәіхКј»Ҝ
»щұҫТЕҙ«Лг·ЁөДіхКјЦЦИәКЗЛж»ъІъЙъөДЈ¬іхКјЦЦИә·ЦІјҝХјдҫЯУРәЬҙуөДІ»И·¶ЁРФәНІ»ҫщФИРФЈ¬І»ДЬәЬәГөШ°ьә¬И«ҫЦЧоУЕҪвөДРЕПўЈ¬ТЧ·ўЙъ№эФзКХБІПЦПуЈ¬іцПЦҫЦІҝЧоУЕОКМвЎЈОӘБЛ·АЦ№ёГОКМв·ўЙъЈ¬ұҫСРҫҝІЙУГҫщФИЙијЖАҙІъЙъіхКјЦЦИәЈ¬И·ұЈіхКјЦЦИәөД¶аСщРФУлёцМе·ЦІјөДҫщФИРФЎЈ
3.3 ККУҰ¶ИәҜКэ
ТЕҙ«Лг·ЁөДЛСЛчДҝұкКЗХТөҪЧоККәПөДҰУЈ¬mЈ¬ҰГәНҰТЈ¬ҙУ¶шМбёЯ»мгзКұјдРтБРөДФӨІвҫ«¶ИЈ¬ҪөөНФӨІвОуІоЈ¬ТтҙЛККУҰ¶ИәҜКэУҰУлДЈРНФӨІвДЬБҰУР№ШЈ¬ЙиөЪjЧйІОКэөДФӨІвҫщ·ҪОуІо(Mean squared errorЈ¬eMS)ОӘ
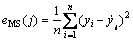 (9)
(9)
КҪЦРЈәnОӘ»мгзКұјдРтБРјмСйјҜКэДҝЈ»yiәН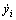 ·ЦұрОӘ»мгзКұјдРтБРөДКөјКЦөәНФӨІвЦөЎЈөЪjёцёцМеөДККУҰәҜКэ¶ЁТеОӘЈә
·ЦұрОӘ»мгзКұјдРтБРөДКөјКЦөәНФӨІвЦөЎЈөЪjёцёцМеөДККУҰәҜКэ¶ЁТеОӘЈә
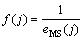 (10)
(10)
3.4 ТЕҙ«ЛгЧУЙијЖ
3.4.1 СЎФсЛгЧУ
јЖЛгёцМеККУҰ¶ИЦөЈ¬°ҙХХККУҰ¶ИЦөҙуРЎҪшРРЕЕРтЈ¬ІЙУГёцМеұЈіЦІЯВФСЎФсRёцЧоУЕёцМеҪшИлПВТ»ҙъЈ¬ЖдУаn-RёцёцМеІЙУГҪ»ІжЎўұдТмІЩЧчІъЙъРВөДёцМеҪшИлПВТ»ҙъЎЈ
3.4.2 Ҫ»ІжЛгЧУ
ФЪёцМеөД4Іҝ·ЦЙП·ЦұрСЎФс4ёцҪ»ІжөгЈ¬И»әуУлБнНвТ»ёцёцМеПа¶ФУҰІҝ·ЦҪшРРҪ»ІжІЩЧчЎЈҪ»ІжНкұПә󣬶ФЙъіЙөДЧУёцМеҪшРРјмСйЈ¬СйЦӨЖдКЗ·сФЪІОКэИЎЦө·¶О§ДЪЈ¬ИфІ»ФЪІОКэИЎЦө·¶О§ДЪЈ¬ФтЦШРВҪшРРҪ»ІжІЩЧчЎЈ
3.4.3 ұдТмЛгЧУ
¶ФёцМеөД4Іҝ·Ц·ЦұрІЙУГҙ«Ні·ӯЧӘұдТм·Ҫ·ЁҪшРРұдТмІЩЧчЈ¬Лж»ъСЎИЎёцМеЙПөД1О»Ј¬°ҙХХ0ұдіЙ1Ј¬1ұдіЙ0өД№жФтҪшРРұдТмІЩЧчЈ¬И»әуЈ¬јмСйұдТмәуёцМеКЗ·сФЪІОКэИЎЦө·¶О§ДЪЈ¬ИфІ»ФЪІОКэИЎЦө·¶О§ДЪЈ¬ФтЦШРВҪшРРұдТмІЩЧчЎЈ
3.5 ІОКэБӘәПУЕ»ҜҫЯМеІҪЦи
КЧПИЈ¬Ҫ«GAІъЙъіхКјЦЦИәЧчОӘФӨІвДЈРНөДІОКэЈ¬°ьАЁҰУЈ¬mЈ¬ҰГәНҰТЈ¬АыУГХвР©ІОКэ·ЦұрҪшРРПаҝХјдЦШ№№әНLSSVMДЈРНСөБ·әНФӨІвЈ¬·ө»ШТ»ПөБРІвКФОуІоeMSЈ¬И»әујЖЛгГҝёцёцМеККУҰ¶ИЈ¬НЁ№эСЎФсЎўҪ»ІжәНұдТмөИТЕҙ«ІЩЧчІъЙъПВТ»ҙъІОКэЦЦИәЈ¬ФЩАыУГёГЧУҙъЦЦИәҪшРРЙПКцІЩЧчЈ¬ЦұөҪВъЧгGAҪбКшМхјюОӘЦ№Ј¬ЧоәуАыУГөГөҪөДЧоУЕІОКэҪшРРҪЁДЈәНФӨІвЎЈІОКэБӘәПУЕ»ҜҫЯМеІҪЦиОӘЈә
(1) И·¶ЁИ«ІҝІОКэЧйіЙөДФӯКјМШХчҝХјдЈ¬ЗТҪш»ҜҙъКэt=0ЎЈ
(2) ¶ФІОКэҰУЈ¬mЈ¬ҰГәНҰТҪшРРұаВлЎЈ
(3) ІЙУГҫщФИЙијЖІъЙъә¬УРmёцМеөДіхКјЦЦИәЎЈ
(4) Ҫ«ёцМе·ҙұаВліЙОӘКөјКІОКэЈ¬ёщҫЭҰУәНm¶Ф»мгзКұјдРтБРКэҫЭҪшРРЦШ№№Ј¬И»әуЈ¬LSSVMёщҫЭІОКэҰГәНҰТҪшРРСөБ·әНФӨІвЈ¬јЗВјГҝЧйІОКэөДФӨІвҫ«¶ИЈ¬ІўјЖЛгГҝёцёцМеөДККУҰ¶ИЦөЎЈ
(5) ҙУИәМеЦРСЎФсФӨІвРФДЬЧоәГөДRёцёцМеУиТФұЈБфІўҪшИлПВТ»ҙъЈ¬ЖдУаөДёцМеҪшРРСЎФсЎўҪ»ІжәНұдТмІЩЧчЈ¬ҙУ¶шІъЙъРВөДЦЦИәЈ¬t=t+1ЎЈ
(6) ЕР¶ПКЗ·сВъЧгҪбКшМхјюЈ¬ИфВъЧгЈ¬ФтҪшИлІҪЦи(7)Ј»·сФтЈ¬·ө»ШІҪЦи(3)Ј¬јМРшЦШёҙЙПКцІЩЧчЎЈ
(7) КдіцЧојСёцМеЦРөДҰУЈ¬mЈ¬ҰГәНҰТЎЈ
(8) ІЙУГЧоУЕҰУәНmЦШ№№»мгзКұјдРтБРКэҫЭЈ¬ІЙУГЧоУЕҰГәНҰТЧчОӘLSSVMөДІОКэ¶ФЦШ№№өДКұјдРтБРҪшРРСөБ·ҪЁДЈІўФӨІвЈ¬ЧоәуөГөҪЧојСФӨІвҪб№ыЎЈ
4 ·ВХжКөСй
4.1 ДЈДв»мгзКұјдРтБРөДФӨІв
4.1.1 Mackey-GlassКұјдРтБРФӨІв
ІЙУГMackey-Glass»мгзКұјдРтБР¶ФGA-LSSVMУРР§РФҪшРРСйЦӨЈ¬Mackey-Glass»мгзКұјдРтБР¶ЁТе ИзПВЈә
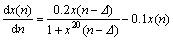 (11)
(11)
КҪЦРЈәҰӨОӘКұЦНІОКэЈ¬өұҰӨЎЭ17КұіКПЦ»мгзРФЈ¬ЗТҰӨФҪёЯЈ¬»мгзіМ¶ИФҪёЯ[17]ЎЈ
ұҫСРҫҝИЎҰӨ=30Ј¬УҰУГ4ҪЧБъёсҝвЛю·ЁІъЙъMackey-Glass»мгзКұјдРтБРЈ¬ИҘөфЗ°2 000ёцФЭМ¬өгЈ¬И»әуИЎ10 000ёцКэҫЭөгЧчОӘКөСйСщұҫЈ¬З°8 000ёцКэҫЭЧчОӘСөБ·јҜЈ¬УГУЪҪЁДЈЈ»ЦРјд1 500ёцКэҫЭЧчОӘСйЦӨјҜЈ¬УГУЪјмСйДЈРНЧоУЕІОКэУРР§РФЈ»Чоәу500ёцКэҫЭЧчОӘІвКФјҜЈ¬јмІвДЈРНөД·ә»ҜДЬБҰЈ¬КөСйКэҫЭИзНј2ЛщКҫЎЈ
НЁ№эІОКэБӘәПУЕ»Ҝ·Ҫ·ЁЈ¬»сөГЧоУЕІОКэОӘЈәҰУ=1Ј¬m=5Ј¬ҰГ=100әНҰТ=0.625Ј¬АыУГЧоУЕІОКэ¶ФІвКФјҜҪшРРФӨІвЈ¬ФӨІвЦөУлКөјККдіцұИҪПИзНј3ЛщКҫЎЈУЙНј3ҝЙјыЈәЧоУЕІОКэөДФӨІвЦөУлКөјКЦөҪПОЗәПЈ¬ұнГчұҫСРҫҝМбіцөДGA-LSSVMІОКэБӘәПУЕ»Ҝ·Ҫ·ЁКЗУРР§өДЈ¬ЗТФӨІвҫ«¶ИПаөұёЯЎЈ
4.1.2 јУФлөДMackey-GlassКұјдРтБРФӨІв
ОӘБЛёьҪшТ»ІҪСйЦӨұҫСРҫҝМбіцЛг·ЁөДВі°фРФәНҝЙҝҝРФЈ¬ІЙУГGA-LSSVM¶ФјУёЯЛ№°ЧФлЙщөДMackey-Glass»мгзКұјдРтБРФӨІвҪшРР·ВХжКөСйЈ¬ЖдФӨІвҪб№ыИзНј4ЛщКҫЎЈУЙНј4ҝЙјыЈәGA-LSSVM¶ФјУФлөДMackey-Glass»мгзКұјдРтБРөДФӨІвҫ«¶ИТІҪПёЯЎЈКөСйҪб№ыұнГчЈәGA-LSSVMөД·ә»ҜНЖ№гДЬБҰЗҝЈ¬ҫЯУРәЬЗҝөДВі°фРФЎЈ
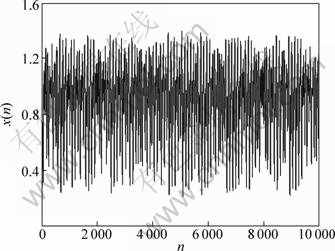
Нј2 Mackey-Glass»мгзКұјдРтБР
Fig.2 Mackey-Glass chaotic time series
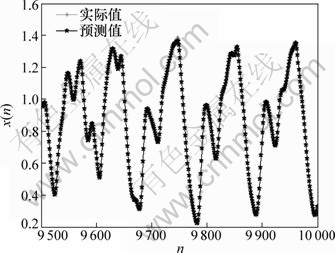
Нј3 GA_LSSVM¶ФMackey-GlassөДФӨІвҪб№ы
Fig.3 Prediction results of Mackey-Glass time series by GA_LSSVM
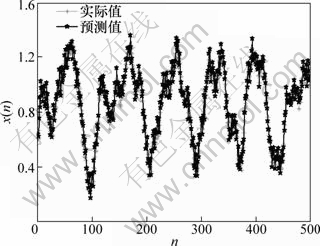
Нј4 GA-LSSVM¶ФјУФлMackey-GlassөДФӨІвҪб№ы
Fig.4 Prediction results of Mackey-Glass time series with noises by GA-LSSVM
4.2 КөјК»мгзКұјдРтБРөДФӨІв
ОӘБЛҪшТ»ІҪјмІвІОКэБӘәПУЕ»Ҝ·Ҫ·ЁФЪКөјКУҰУГЦРөД»мгзКұјдРтБРФӨІвР§№ыЈ¬ІЙУГМ«СфәЪЧУФВЖҪҫщКэәННшВзБчБҝ¶ФЖдҪшРРІвКФКөСйЎЈ
4.2.1 М«СфәЪЧУФВЖҪҫщКэФӨІв
М«СфәЪЧУКэҫЭАҙЧФSIDC(Solar influences data analysis center)Ј¬ҫЯМеКөСйКэҫЭОӘ1749ЎӘ2008ДкМ«СфәЪЧУөДФВЖҪҫщКэЈ¬КэҫЭ·ЦіЙ3Іҝ·ЦЈә1749ЎӘ1950ДкКэҫЭЧчОӘСөБ·јҜЈ»1951ЎӘ2000ДкКэҫЭЧчСйЦӨјҜЈ»2001ЎӘ2008ДкКэҫЭЧчОӘІвКФјҜЎЈОӘБЛК№ІОКэБӘәПУЕ»Ҝ·Ҫ·ЁөДФӨІвҪб№ыёьҫЯЛө·юБҰЈ¬СЎФсC-C-LSSVMДЈРНЧчОӘ¶ФұИДЈРНЈ¬ЖдКЧПИІЙУГC-C·Ҫ·ЁИ·¶ЁҰУәНmЈ¬И»әуІЙУГLSSVMҪшРРФӨІвЈ¬LSSVMІОКэІЙУГGAУЕ»ҜЎЈ
2ЦЦДЈРН¶ФМ«СфәЪЧУФВЖҪҫщКэІвКФјҜөДФӨІвҪб№ыИзНј6ЛщКҫЎЈҙУНј6ЛщКҫөД¶ФұИҪб№ыҝЙЦӘЈәGA-LSSVMФӨІвҪб№ыГчПФУЕУЪCC-LSSVMЎЈКөСйҪб№ыҪшТ»ІҪұнГчЈ¬ұҫСРҫҝМбіцөДПаҝХјдЦШ№№УлФӨІвДЈРНІОКэБӘәПУЕ»ҜЛјВ·КЗУРР§өДәНХэИ·өДЈ¬ЖдФӨІвҫ«¶ИұИөҘ¶А·ЦҝӘУЕ»Ҝ·Ҫ·ЁөДёЯЈ¬әЬәГөШҪвҫцөұЗ°»мгзКұјдРтБРФӨІв№эіМЦРҙжФЪөДІОКэУЕ»ҜОКМвЎЈ
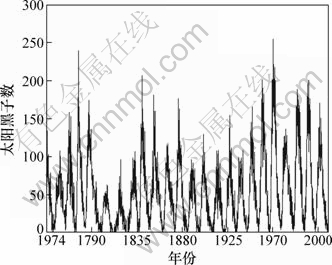
Нј5 М«СфәЪЧУФВЖҪҫщКэ
Fig.5 Monthly average sunspot numbers
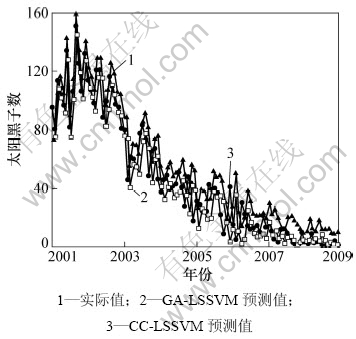
Нј6 БҪЦЦДЈРНөДМ«СфәЪЧУФВЖҪҫщКэФӨІвҪб№ы¶ФұИ
Fig.6 Comparison of monthly average sunspot numbers prediction results
4.2.2 НшВзБчБҝөДФӨІв
НшВзБчБҝұд»ҜҫЯУРКұұдРФЎў·ЗПЯРФәНёЯ¶ИЧФПаЛЖРФЈ¬КЗТ»ЦЦёЯ¶И»мгзөДПөНіЈ¬НшВзБчБҝКэҫЭАҙЧФHttp://newsfeed.ntcu.net/~news/2008/Ј¬№ІКХјҜөҪ1 000ёцНшВзБчБҝКэҫЭөгЈ¬ИзНј7ЛщКҫЎЈҪ«КэҫЭ·ЦіЙ3Іҝ·ЦЈәЗ°800ёцКэҫЭЧчОӘСөБ·јҜЈ¬ЦРјд150ёцКэҫЭЧчОӘСйЦӨјҜЈ¬Чоәу50ёцКэҫЭЧчОӘІвКФјҜЎЈ
ІЙУГCC-LSSVMәНBPЙсҫӯНшВз(BPNN)ЧчОӘ¶ФұИДЈРНЈ¬ЖдЦРBPNNІЙУГC-CҪшРРПаҝХјдЦШ№№Ј¬ЖдІОКэІЙУГGAҪшРРУЕ»ҜЈ¬3ЦЦДЈРН¶ФІвКФјҜөДФӨІвҪб№ыИзНј8ЛщКҫЎЈҙУНј8ЛщКҫөД¶ФұИКөСйҪб№ыҝЙЦӘЈәұҫСРҫҝМбіцөД»мгзКұјдФӨІвДЈРНөДНшВзБчБҝФӨІвЦөУлКөјКёьјУОЗәПЈ¬ФӨІвҫ«¶ИұИ¶ФұИ·Ҫ·ЁөДёЯЈ¬КЗТ»ЦЦёЯҫ«
¶ИөД»мгзКұјдРтБРФӨІв·Ҫ·ЁЎЈ
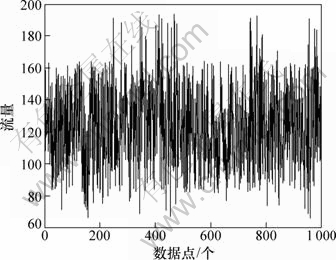
Нј7 НшВзБчБҝКэҫЭ
Fig.7 Network traffic data
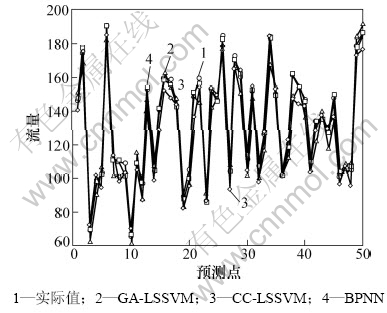
Нј8 ёчДЈРННшВзБчБҝөДФӨІвҪб№ыұИҪП
Fig.8 Comparison of network traffic prediction results by different models
5 ҪбВЫ
(1) ¶ФУ°Пм»мгзКұјдРтБРДЈРНФӨІвРФДЬөДІОКэҪшРРЙоИл·ЦОцЈ¬АыУГІОКэјдөДПа»ҘБӘПөЈ¬МбіцТ»ЦЦ»щУЪТЕҙ«Лг·ЁөДІОКэБӘәПУЕ»Ҝ·Ҫ·ЁЈ¬ІўНЁ№э»мгзКұјдРтБРКөАэ¶ФЖдУРР§РФәНУЕФҪРФҪшРРБЛСйЦӨЎЈ
(2) ІОКэБӘәПУЕ»ҜөДДЈРНРФДЬГчПФУЕУЪІОКэөҘ¶АУЕ»ҜөДДЈРНЈ¬ІОКэБӘәПУЕ»Ҝ·Ҫ·Ёҙу·щ¶ИМбёЯ»мгзКұјдРтБРөДФӨІвҫ«¶ИЈ¬ОӘ»мгзКұјдРтБРІОКэС°УЕОКМвМṩБЛТ»ЦЦРВөДҪвҫцЛјВ·ЎЈ
ІОҝјОДПЧЈә
[1] Masoud M, Caro L, Masoud S, et al. Real-time identification and forecasting of chaotic time series using hybrid systems of computational intelligence[J]. Neural Computing & Applications, 2009, 18(8): 991-1004.
[2] Albano A M, Muench J, Schwartz C, et al. Correlation-dimension and autocorrelation fluctuations in epileptic seizure dynamics[J]. Phys Rev, 2002, 65(3): 1921-1926.
[3] Silva C G. Time series forecasting with a nonlinear model and the scatter search meta-heuristic[J]. Information Sciences, 2008, 178(16): 3288-3299.
[4] Kim H S, Eykholt R, Salas J D. Nonlinear dynamics, delay times and embedding windows[J]. Physica D, 1999, 127(10): 48-60.
[5] ХЕКзЗе, јЦҪЎ, ёЯГф, өИ. »мгзКұјдРтБРЦШ№№ПаҝХјдІОКэСЎИЎСРҫҝ[J]. ОпАнС§ұЁ, 2010, 59(3): 1576-1582.
ZHANG Shu-qing, JIA Jian, GAO Min, et al. Study on the spatial parameters selection of chaotic time series reconstruction[J]. Acta Physica Sinica, 2010, 59(3): 1576-1582.
[6] РЮҙәІЁ, БхПт¶«, ХЕУоәУ. ПаҝХјдЦШ№№СУіЩКұјдУлЗ¶ИлО¬КэөДСЎФс[J]. ұұҫ©Ан№ӨҙуѧѧұЁ, 2003, 23(2): 219-224.
XIU Chun-bo, LIU Xiang-dong, ZHANG Yu-he. Selection of embedding dimension and delay time in the phase space reconstruction[J]. Journal of Beijing Institute of Technology: Natural Science Edition, 2003, 23(2): 219-224.
[7] WANG Wen-sheng, JIN Ju-liang, LI Yue-qing. Prediction of inflow at three gorges dam in yangtze river with wavelet network model[J]. Water Resources Management, 2009, 23(13): 2791-2803.
[8] MA Jun-hai, CHEN Yu-shu, XIN Bao-gui. Study on prediction methods for dynamic systems of nonlinear chaotic time series[J]. Applied Mathematics and Mechanics, 2004, 25(6): 605-612.
[9] ZHANG Jun-feng, HU Shou-song. Chaotic time series prediction based on multi-kernel learning support vector regression[J]. Acta Physica Sinica, 2008, 57(5): 2708-273.
[10] WU Qiong, LIU Wen-ying, YANG Yi-han. Time series online prediction algorithm based on least squares support vector machine[J]. Journal of Central South University of Technology, 2007, 14(3): 442-446.
[11] Ayat N E, Cheriet M, Suen C Y. Automatic model selection for the optimization of the SVM kernels[J]. Pattern Recognition, 2005, 38: 1733-1745.
[12] БәОфГч, СЦёЩ, АоЙҪҙә, өИ. »щУЪЧоРЎ¶юіЛЦ§іЦПтБҝ»ъәН»мгзУЕ»ҜөД·ЗПЯРФФӨІвҝШЦЖ[J]. РЕПўУлҝШЦЖ, 2010, 39(2): 129-135.
LIANG Xi-ming, YAN Gang, LI Shan-chun, et al. Nonlinear predictive control based on least squares support vector machines and chaos optimization[J]. Information and Control, 2010, 39(2): 129-135.
[13] ZHONG Wei-min, PI Dao-ying, SUN You-xian. Support vector machine based nonlinear model multi-step-ahead optimizing predictive control[J]. Journal of Central South University of Technology, 2005, 12(5): 591-595.
[14] PAN Jin-Shui, HONG Mei-Zhu, ZhOU Qi-Feng, et al. Integrated application of uniform design and least-squares support vector machines to transfection optimization[J]. BMC Biotechnology, 2009, 9(1): 52-57.
[15] СоУЭОў, ЧуәйёЈ, іВ№ы. Ц§іЦПтБҝ»ъКұјдРтБРФӨІвДЈРНөДІОКэУ°Пм·ЦОцУлЧФККУҰУЕ»Ҝ[J]. әҪҝХ¶ҜБҰС§ұЁ, 2004, 21(4): 767-773.
YANG Yu-wei, ZUO Hong-fu, CHEN Guo. Influence analysis and self adaptive optimization of support vector machine time series forecasting model parameter[J]. Journal of Aerospace Power, 2004, 21(4): 767-773.
[16] QI Hong-li, ZHAO Hui, LIU Wei-wen, et al. Parameters optimization and nonlinearity analysis of grating eddy current displacement sensor using neural network and genetic algorithm[J]. Journal of Zhejiang University Science A, 2009, 10(8): 1205-1212.
(ұајӯ әОФЛұу)
КХёеИХЖЪЈә2011-02-16Ј»РЮ»ШИХЖЪЈә2011-04-22
»щҪрПоДҝЈәәюДПКЎҪМУэМьҝЖС§СРҫҝПоДҝ(10C0803)
НЁРЕЧчХЯЈәЦЬЧУУў(1974-)Ј¬Е®Ј¬әюДПіҪПӘИЛЈ¬І©КҝСРҫҝЙъЈ¬ҪІКҰЈ¬ҙУКВИЛ№ӨЦЗДЬСРҫҝЈ»өз»°Јә0731-84617617Ј»E-mailЈәmfkm978@shou.com

