Exploiting global and local features for image retrieval
��Դ�ڿ������ϴ�ѧѧ��(Ӣ�İ�)2018���2��
�������ߣ����� Li Li(����) � ��ľ�� ��ʤ��
����ҳ�룺259 - 276
Key words��local binary patterns; hue, saturation, value (HSV) color space; graph fusion; image retrieval
Abstract: Two lines of image representation based on multiple features fusion demonstrate excellent performance in image retrieval. However, there are some problems in both of them: 1) the methods defining directly texture in color space put more emphasis on color than texture feature; 2) the methods extract several features respectively and combine them into a vector, in which bad features may lead to worse performance after combining directly good and bad features. To address the problems above, a novel hybrid framework for color image retrieval through combination of local and global features achieves higher retrieval precision. The bag-of-visual words (BoW) models and color intensity-based local difference patterns (CILDP) are exploited to capture local and global features of an image. The proposed fusion framework combines the ranking results of BoW and CILDP through graph-based density method. The performance of our proposed framework in terms of average precision on Corel-1K database is 86.26%, and it improves the average precision by approximately 6.68% and 12.53% over CILDP and BoW, respectively. Extensive experiments on different databases demonstrate the effectiveness of the proposed framework for image retrieval.
Cite this article as: LI Li, FENG Lin, WU Jun, SUN Mu-xin, LIU Sheng-lan. Exploiting global and local features for image retrieval [J]. Journal of Central South University, 2018, 25(2): 259�C276. DOI: https://doi.org/10.1007/s11771- 018-3735-6.

J. Cent. South Univ. (2018) 25: 259-276
DOI: https://doi.org/10.1007/s11771-018-3735-6
LI Li(����)1, FENG Lin(����)1, 2, WU Jun(�)2, SUN Mu-xin(��ľ��)2, LIU Sheng-lan(��ʤ��)3
1. School of Computer Science and Technology, Faculty of Electronic Information and Electrical Engineering, Dalian University of Technology, Dalian 116024, China;
2. School of Innovation and Entrepreneurship, Dalian University of Technology, Dalian 116024, China;
3. School of Control Science and Engineering, Faculty of Electronic Information and Electrical Engineering, Dalian University of Technology, Dalian 116024, China
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2018
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2018
Abstract: Two lines of image representation based on multiple features fusion demonstrate excellent performance in image retrieval. However, there are some problems in both of them: 1) the methods defining directly texture in color space put more emphasis on color than texture feature; 2) the methods extract several features respectively and combine them into a vector, in which bad features may lead to worse performance after combining directly good and bad features. To address the problems above, a novel hybrid framework for color image retrieval through combination of local and global features achieves higher retrieval precision. The bag-of-visual words (BoW) models and color intensity-based local difference patterns (CILDP) are exploited to capture local and global features of an image. The proposed fusion framework combines the ranking results of BoW and CILDP through graph-based density method. The performance of our proposed framework in terms of average precision on Corel-1K database is 86.26%, and it improves the average precision by approximately 6.68% and 12.53% over CILDP and BoW, respectively. Extensive experiments on different databases demonstrate the effectiveness of the proposed framework for image retrieval.
Key words: local binary patterns; hue, saturation, value (HSV) color space; graph fusion; image retrieval
Cite this article as: LI Li, FENG Lin, WU Jun, SUN Mu-xin, LIU Sheng-lan. Exploiting global and local features for image retrieval [J]. Journal of Central South University, 2018, 25(2): 259�C276. DOI: https://doi.org/10.1007/s11771- 018-3735-6.
1 Introduction
With the expansion of digital images in the field of education, entertainment and medical, etc., it is an extremely difficult task to retrieve useful images from a huge image database. Generally speaking, there are three categories of image retrieval methods: text based, content based and semantic based [1]. Image retrieval methods based on text are used widely which retrieve image using keywords. However, the image retrieval methods based on text have two drawbacks. Firstly, images are annotated by human labor, but it is time-consuming for a large volume of image database. Secondly, because different annotators may perceive the same image differently and this often obtains a lot of unwanted images in the result. Besides, because of the limitations in cognitive science about mechanisms of the primary visual cortex and artificial intelligence, semantic based image retrieval methods are just beginning and they still have a long way to go for real applications. Therefore, content-based image retrieval (CBIR) [2, 3] is attracting more and more attentions in both the academia and the industry. In CBIR system,low-level features such as color, texture and shape of the query image are first extracted. Then feature matching between the query image and images in the database has been done by similarity measure. Finally, the top-N similar images are returned to the user. Therefore, feature extraction and image ranking are two key steps in CBIR.
Image features can be widely classified into two categories: global features and local features. Global features (such as color, shape and texture) delineate overall feature distributions of images. Color histogram is one of global features and it is invariant to scale and orientation [4]. However, color histogram lacks spatial information. Therefore, color moments [5], color correlograms [6] and color coherence vector [7] have been proposed to exploit the spatial information. STRICKER et al [5] proposed color moments which considered the spatial position information. Color correlograms were proposed which characterize the spatial correlation between pair of colors. Color coherence vector was introduced for image retrieval which incorporated spatial information of images. In addition, local binary pattern (LBP) [8] has been proved to have excellence by comparing all neighboring pixels with a given center pixel. Some variants of LBP have been proposed in many fields, such as face recognition, texture classification [9], and palmprint recognition. HEIKKIL et al [10] proposed center symmetric local binary pattern (CS-LBP) which compared center-symmetric pairs of pixels. Local configuration pattern (LCP) has been proposed and is combined with LBP to extract texture features for texture classification [11]. TAN et al [12] proposed local ternary patterns (LTP) which extends LBP to 3-valued codes and LTP codes are resistant to noise. GUO et al [13] proposed completed local binary pattern (CLBP), in which CLBP_Center (CLBP_C), CLBP_Sign (CLBP_S) and CLBP_Magnitude (CLBP_M) are proposed. Joint or hybrid histogram of the three operators above has been applied for texture classification. MURALA et al [14] proposed local mesh patterns (LMP) for biomedical image indexing and retrieval which encoded the relationship among the surrounding neighbors for a given center pixel in an image. In Ref. [15], ZHANG et al proposed a histogram descriptor for global feature extraction, where they defined three elementary primitives and computed three equivalence classes of primitives to compute the feature image. The histogram was used for the transformed image to describe the image features.
et al [10] proposed center symmetric local binary pattern (CS-LBP) which compared center-symmetric pairs of pixels. Local configuration pattern (LCP) has been proposed and is combined with LBP to extract texture features for texture classification [11]. TAN et al [12] proposed local ternary patterns (LTP) which extends LBP to 3-valued codes and LTP codes are resistant to noise. GUO et al [13] proposed completed local binary pattern (CLBP), in which CLBP_Center (CLBP_C), CLBP_Sign (CLBP_S) and CLBP_Magnitude (CLBP_M) are proposed. Joint or hybrid histogram of the three operators above has been applied for texture classification. MURALA et al [14] proposed local mesh patterns (LMP) for biomedical image indexing and retrieval which encoded the relationship among the surrounding neighbors for a given center pixel in an image. In Ref. [15], ZHANG et al proposed a histogram descriptor for global feature extraction, where they defined three elementary primitives and computed three equivalence classes of primitives to compute the feature image. The histogram was used for the transformed image to describe the image features.
Different from global features, local features focus on the features of image regions (such as salient patches or key points). Various algorithms have been proposed to extract local features. Scale invariant feature transform (SIFT) [16] is the most popular local feature representation method. Speeded up robust features (SURF) [17] and Oriented Fast and Rotated Brief (ORB) [18] are proposed to reduce the computational complexity. In BoW model [19], local features are extracted through SIFT, and then integrate all local features to present image information. Unfortunately, visual words are obtained by clustering implementation of local features, which lead to heavy computational burdens and may result in the loss of information.
Most of the techniques in CBIR have used a single feature during the last decade. However, a single feature usually has some limitations. It is hard to represent various characteristics of images. Therefore, image representation methods based on multiple features fusion are proposed to gain satisfactory retrieval results. These methods can be mainly classified into two categories. One is based on joint multi-features which extract multiple features respectively and then combine them into a vector to represent more information than single feature. SHEN et al [20] proposed a method which combined color, texture and spatial structure features of images. Images are segmented into regions to extract local color, texture and census transform histogram (CENTRIST) features respectively. ELALAMI [21] used 3D color histogram and Gabor filter to extract the color and texture features. SUBRAHMANYAM et al [22] proposed a modified color motif co-occurrence matrix (MCMCM) for image retrieval. This method integrates the MCMCM and the difference between the pixels of a scan pattern (DBPSP) features with equal weights. The other is based on the underlying colors which extract texture, shape and color layout information in color space. LIU et al [23] proposed texton co-occurrence matrix in RGB color space. LIU et al [24] proposed multi-texton histogram (MTH) that integrates the advantages of co-occurrence matrix and histogram to characterize color and texture features. Color difference histograms (CDH) [25] consider the perceptually uniform color difference between two points under different backgrounds in Lab color space.
However, the methods define directly texture and other features underlying color space. Therefore, these methods put more emphasis on color information than other features and impair the performance of image descriptors. Also, the methods extract several features respectively and combine them into a vector, in which bad features may lead to worse performance after combining good and bad features directly and it is difficult to determine which feature is a major feature. Graph-based fusion method [26] can well cope with these problem which provides an effective solution for the fusion of complementary features. Therefore, a hybrid framework is proposed for the fusion of BoW and color intensity-based local difference patterns (CILDP) retrieval results by graph-based fusion method which achieves higher retrieval precision than the combinations of other traditional image descriptors.
In summary, the main contributions of this work are summarized as follows:
1) A novel feature descriptor called intensity- based local difference patterns (ILDP) has been proposed, which considers the spatial structure information among the surrounding neighbors in a local region. The center pixel intensity local difference patterns (C-ILDP) and neighbors pixels intensity local difference patterns (N-ILDP) are proposed to form the final ILDP histogram. This approach is different from the standard LBP. The LBP only considers the relationship between a given referenced pixel and its neighborhoods and does not reveal the spatial structure information of image pixel pairs. Besides, the traditional local patterns methods have treated color and texture as individual features. In this work, texture feature has been extracted by using HSV color space component.
2) Global color information has been extracted from Hue (H) and Saturation (S) components of HSV color space, and ILDP is calculated for V component.
3) Construct the feature vector by jointing the H, S and V histograms obtained, and feature matching has been done for image retrieval.
4) A fusion framework has been proposed for image retrieval. The retrieval ranks of BoW model and ILDP are integrated through graph-based fusion approach. The performance of the proposed framework is compared with the recent state-of- the-art methods on different databases.
2 Color and texture descriptor
This section gives a brief review of color quantization in HSV color space, the local binary pattern (LBP) operator and the intensity-based descriptor of neighbors (neighbors intensity local binary pattern, NI-LBP).
2.1 HSV color space and color quantization
Color is a very important visual feature, and there are already a lot of good color space models [27], such as RGB, HSV and Lab. HSV color space [28] is very close to the human visual perception system and it is widely used to extract color information. In HSV color space, Hue (H) component describes the color type. It ranges from 0�� to 360�� and different angles present different colors. Saturation (S) component is numbered from 0 to 1, as saturation goes from low to high, the color saturation increases. Value (V) component refers to the brightness of the color and it also ranges from 0 to 1. It has been proven that HSV color space is more appropriate than RGB color space [28]. In this work, HSV color space is used for color and texture representation. In order to reduce the computational complexity, it is necessary to make appropriate color space quantization. H and S components are quantized into 72 and 20 bins in HSV color space.
2.2 Local binary pattern
OJALA et al [8] proposed local binary pattern (LBP) for texture classification. For a given center pixel in an image, the LBP code is computed by comparing the center pixel with its neighbors. LBP takes P points around the center pixel as neighbors. LBP is defined as follows:
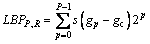 (1)
(1)
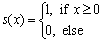 (2)
(2)
where P denotes the number of neighbors, R is the radius of the neighborhood and gc is the gray-value of the center pixel. The gray values of its neighbors are as follows: g0, g1, ��, gP�C1. Using this method, 2P distinct values can be obtained for the LBP code.
2.3 Intensity-based descriptor of neighbors
Instead of comparing each neighbor pixel with the center pixel, LIU et al [29] compared each neighbor pixel with the mean of neighbors intensity-based descriptor of neighbors (NI-LBP), it is defined as follows:
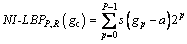 (3)
(3)
where gp is the gray value of the surrounding neighbors and 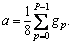
3 Intensity-based local difference patterns
3.1 N-ILDP and C-ILDP operators
In an image, the brightness level at a point is highly dependent on the brightness levels of its neighbors unless the image is simply random noise [30]. Inspired by this idea, LIU et al [29] proposed the intensity-based features which considered the intensity of neighbors (NI-LBP). However, NI-LBP does not consider the spatial structure information among pixels in the image.
LBP and NI-LBP have motivated us to propose the center pixel intensity local difference patterns (C-ILDP) and neighbors pixels intensity local difference patterns (N-ILDP) for image retrieval. Then N-ILDP and C-ILDP codes are combined to form the ILDP feature of images. N-ILDP describes the spatial structure among pixels using the relationships between neighbors with the average value of neighbors for a given center pixel.
For a given center pixel in an image, N-ILDP is obtained by computing local difference between the surrounding neighborhoods and the average value of neighborhoods as shown below:
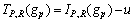 (p=0, 1, ��, 7) (4)
(p=0, 1, ��, 7) (4)
where IP,R(gp) is the gray values of the surrounding neighbors and 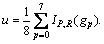
After calculating the intensity distributions of the surrounding neighbors, local differences of the surrounding neighbors are coded based on the indicator s(x) as follows:
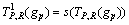 (p=0, 1, ��, 7) (5)
(p=0, 1, ��, 7) (5)
The signs of the local differences about the surrounding neighbors are interpreted as a 8-bit binary number. N-ILDP is defined (t=(0), (1), (2), (3), (4), (5), (6), (7), (8)) as follows:
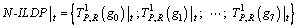 (6)
(6)
The detailed representation of N-ILDP can be seen in Figure 1. Finally, N-ILDP is computed with subscripts (0) to (8) as center pixels by using this method. The histograms are constructed for N-ILDP with subscripts (0) to (8). All histograms are concatenated as the final feature vector and 9��28 distinct values can be obtained for the N-ILDP code. In order to reduce the computational cost, the uniform patterns are used [31] in this work. Therefore, the feature vector length of N-ILDP is 9��59=531.
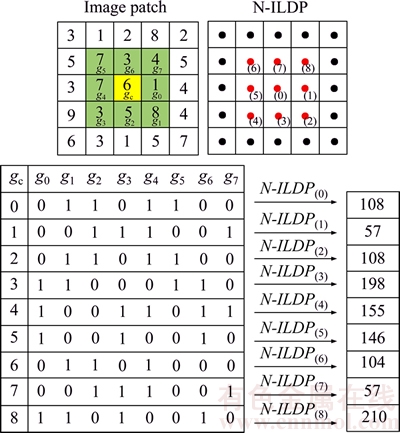
Figure 1 Example of obtaining N-ILDP for 5��5 pattern
After calculation of N-ILDP, the whole image is represented by building a histogram as follows:
 (7)
(7)
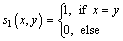 (8)
(8)
where the size of input image is M��N,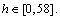
The center pixel also has discriminative information which represents the image local gray level. To make the center pixel consistent with N-ILDP, the 1-D intensity distribution of the center pixel is coded using two bins as follows:
 (9)
(9)
 (10)
(10)
where gt is the gray-value of the center pixel, t=(0), (1), (2), (3), (4), (5), (6), (7), (8) and  is the average gray level of the whole local image.
is the average gray level of the whole local image.
The N-ILDP computation for a given center pixel marked with yellow color has been illustrated in Figure 1. The local difference between the surrounding neighbors and the average gray value of its eight neighbors are used to represent the spatial structure information. The selected 3��3 pattern for N-ILDP calculation is represented with subscripts (0) to (8) as center pixels, and the surrounding neighbors are represented with subscripts 0 to 7.
An example of the N-ILDP computation for a center pixel marked with yellow color has been illustrated in Figure 2. For a center pixel '6', the N-ILDP is applied with subscript (0) as center pixel and then it is seen that the gray value of the surrounding neighbors is 4.75. Hence this pattern with subscript (0) as center pixel is coded to 01101100 by comparing the surrounding neighbors with the average gray value of its eight neighbors. In the same fashion, N-ILDP with subscripts (1) to (8) (1, 8, 5, 3, 7, 7, 3 and 4) as center pixels are also computed.
3.2 Analysis
The proposed N-ILDP is different from the conventional LBP. The N-ILDP encodes the spatial structure relations of the surrounding neighbors in a local region, while LBP only considers the relationships between the center pixel and its neighborhoods. Therefore, N-ILDP captures more spatial structure information than LBP. It has been already proved that the brightness levels of neighbors for the brightness level at a point are very important for texture analysis [30].
Figure 3 shows the comparison between N-ILDP and LBP on a 5��5 sample image patch. From Figure 3, we can see that LBP does not output the visual patterns. In contrast, the proposed N-ILDP preserves weak edge patterns information and spatial structure information.
For a given center pixel, N-ILDP code is computed by comparing its neighbors with the average gray level of its neighbors. C-ILDP code is computed by comparing the center pixel with the average gray level of the whole local image. Then the final feature vector of ILDP is constructed by concatenating the histograms of N-ILDP and C-ILDP. Experimental results in Section 5 also demonstrate that ILDP shows a better performance as compared with other local pattern methods, and indicates that ILDP is effective and more discriminative than other local pattern methods for image retrieval.
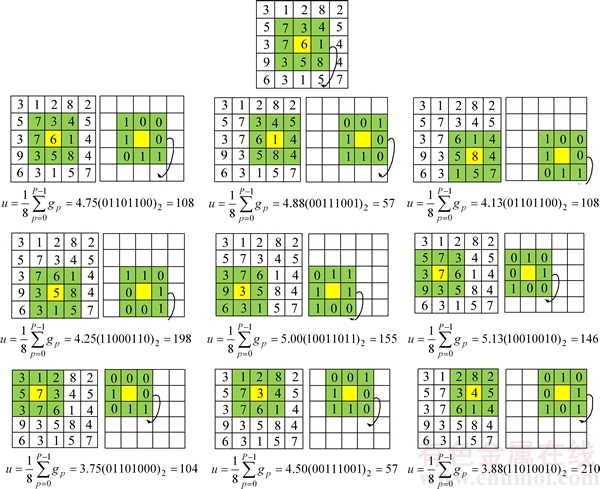
Figure 2 Example to obtain N-ILDP (u denotes average gray value of surrounding neighbors)

Figure 3 Comparison of N-ILDP and LBP on a sample image patch
3.3 Color intensity-based local difference patterns
In order to extract more information from images, a novel feature extraction algorithm called color intensity-based local difference patterns (CILDP) has been proposed using color and texture features of images for image retrieval. H component is quantized into 18, 36 and 72 bins to extract reasonable information. Similarly, S component is quantized into 10 and 20 bins. All different quantization levels are used so that reasonable color feature can be obtained. Different combinations of H and S components have been used on different image databases, and the experimental results are given in Section 5.4.2.
In the HSV color space, V component is very close to the gray level image conversion of the RGB image. Therefore, V component is used to extract texture information. H and S component histograms are used to extract the global color information of images. N-ILDP captures more spatial structure information and preserves weak edge patterns information, while conventional local patterns only extract relationships between the center pixel and its neighbors. Therefore, N-ILDP is more effective and discriminative than conventional local patterns, owing to the better thresholding (u). C-ILDP can also extract discriminative information. The combination of N-ILDP and C-ILDP can get a more discriminative texture feature than conventional local patterns.
Figure 4 shows two categories images (four images) and their feature vectors obtained by ILDP. Four images are two landscape images and two sphinx images. As shown in Figure 4, the histograms are similar for two similar images and the histograms of two categories images are quite different. This indicates that ILDP is discriminative for image retrieval.
4 Proposed system framework
A hybrid framework is proposed for the fusion of CILDP and bag-of-words(BoW) retrieval results by using graph fusion method [26]. The proposed method leads to improvement in retrieval precision over both the individual methods. Figure 5 illustrates the flowchart of the proposed fusion framework. CILDP and BoW can implement both the techniques in parallel for a query image. All images in the database are ranked according to improved Canberra distance with the query image for CILDP and BoW features. For rank-level fusion, the retrieval results of CILDP and BoW are combined via graph density method and return the top N ranked images. The proposed fusion framework can be described as following steps.
4.1 Steps for CILDP
The algorithm of CILDP is given as follows.
Algorithm: CILDP.
Input: Query image.
Output: Retrieval results.
Step 1: Load the RGB image.
Step 2: Convert it from RGB to HSV color space.
Step 3: Quantize the H and S components into 18, 36, 72 and 10, 20 bins respectively, and construct the global color histograms for both.
Step 4: Apply ILDP on the V component in the HSV color space, and construct the histogram of ILDP.
Step 5: Concatenate the histograms of Step 3 and Step 4, and construct the final histogram as the feature vector of CILDP.
Step 6: Compare the feature vector of query image with the feature vectors of images in the database using similarity measure.
Step 7: Sort the images using the distance measure and output the best matches as final results.
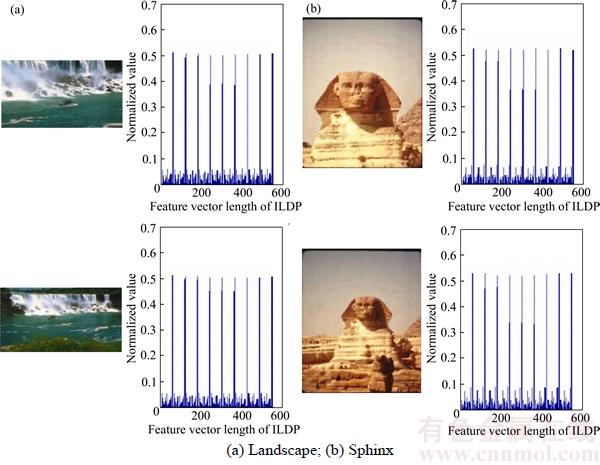
Figure 4 Two categories images and their ILDP feature vectors:
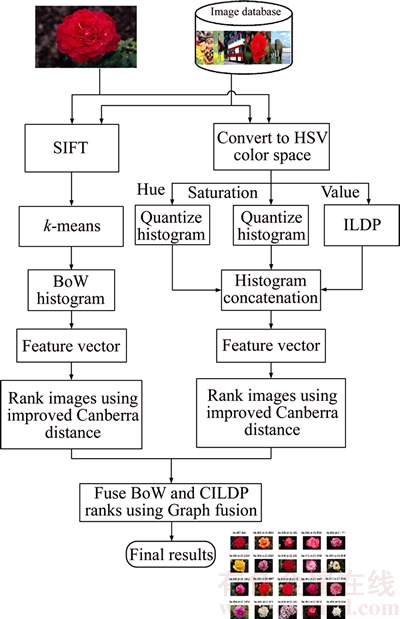
Figure 5 Flowchart of proposed retrieval system framework
4.2 Steps for BoW
The BoW model is based on the SIFT densely extracted in the image, which are coded into local features and is finally characterized by a histogram of local features. The steps of BoW can be described as follows.
Step 1: Extract local features from an image using SIFT detector.
Step 2: Quantize the local features using visual vocabulary, which is learned using the k-means algorithm, and cluster the visual words from the training set into a codebook.
Step 3: Compute a histogram of occurrences of visual words for each image in the database, and generate a BoW vector.
Step 4: Normalize all resulting vectors to represent all images.
4.3 Graph fusion ranking
Graph fusion method has been proven effective in image retrieval and it provides an effective solution for the fusion of heterogeneous features [32]. The ranking steps of graph fusion can be described as follows:
1) Graph construction
Given a set of retrieval results by a retrieval method, such as the CILDP or BoW, a weighted undirected graph G=(V, E, w) is constructed by the consensus degree (e.g., k-nearest neighbors) for each list of retrieval results, where V denotes the note set, E denotes the edge set and w denotes the attached edge weight. Denote i either the query or a database image, and i�� a reciprocal neighbor image. Assuming that the query image represents the graph centroid, and edges connect the reciprocal neighbors. The Jaccard similarity coefficient J(i, i��) denotes the weight of the attached edge w. The attached edge weight w between images i and i�� is defined as follows:
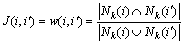 (11)
(11)
where |��| is the cardinality, Nk(i) and Nk(i��) are the top-k retrieval candidates using i and i�� as the query. The edge weight  with J(i, i��)=1 implies that i and i�� share the same neighbors.
with J(i, i��)=1 implies that i and i�� share the same neighbors.
2) Graph fusion
Multiple graphs Gm=(V m, E m, w m) are obtained from the retrieval results of different features. Then, multiple graphs are fused to one graph G=(V, E, w)
with 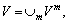
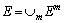 (
(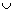 represents union), and
represents union), and 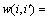
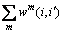 (with
(with 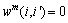 for
for 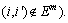
3) Ranking images by maximizing weighted density
A graph G is constructed from a single feature or more features via graph fusion. Then, it is necessary to rank the retrieval candidates and search for the subgraph 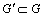 containing query image. This can be achieved by a weighted maximum density, and it is defined as follows:
containing query image. This can be achieved by a weighted maximum density, and it is defined as follows:
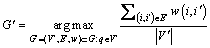 (12)
(12)
where q represents the query image. A greedy algorithm is used to select the higher visual similar image, starting from 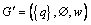 . Node degree
. Node degree 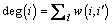 is computed for each node i linked with q. Then a node is selected which can introduce the largest weight to G��, until all expected number of images is retrieved.
is computed for each node i linked with q. Then a node is selected which can introduce the largest weight to G��, until all expected number of images is retrieved.
More details of graph fusion ranking are introduced in Refs. [26, 32].
4.4 Advantages of proposed scheme
1) The proposed ILDP considers the spatial structure information among the surrounding neighbors in a local region. However, conventional methods only simply consider the relationship of the pattern alone between the center pixel and its neighborhoods. They do not consider any information regarding the spatial relation of patterns in the image.
2) As explained in Section 2.1, HSV color space is better than RGB color space. H and S components are used to extract global color information and the proposed ILDP is applied to extract texture feature on V component.
3) The proposed hybrid framework for color image retrieval can significantly improve the performance of each individual feature and it also achieves higher retrieval precision than other methods through combination of CILDP and BoW features.
5 Experimental results and discussions
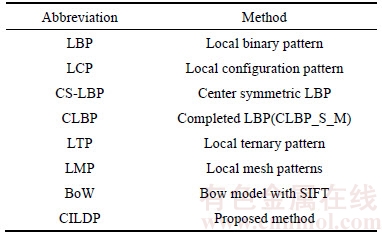
In order to evaluate the performance of proposed method for image retrieval, several experiments are conducted on benchmark databases. The abbreviations of different methods have been listed in Table 1.
5.1 Databases
Experiments are performed on Corel database and Coil-100 database to test the performance of the proposed framework. All images of Corel databases come from the Corel Gallery Magic 200000 (8CDs) database which includes diverse contents images. Two subsets of Corel database are used in our experiments. Corel-1K [33] database is the first database which consists of 1000 natural images in 10 different categories. It includes elephants, flowers, horses, Africans, beaches, mountains, buildings, buses, dinosaurs and food. Each category contains 100 images of size 384��256 in JPG format. Some sample images from Corel-1K database are shown in Figure 6(a). The Coil-100 is the second database which contains 7200 images in 100 different categories. Each category contains 72 images of size 128��128 in PNG format. Some sample images from the Coil-100 database are shown in Figure 6(b). Corel-10K database [34] is the third database which consists 10000 images in 100 different categories. It includes fishes, ships, doors, beaches, fruits, bears, etc. Some sample images from Corel-10K database are shown in Figure 6(c).
Table 1 Abbreviations of different methods
5.2 Similarity measure
Feature extraction and similarity measure are two crucial factors in CBIR. Let Y=[y1, y2, ��, yn] be the feature vector of a query image and X=[x1, x2, ��, xn] be the feature vector of each image in the database. Several common similarity measures have been used for the similarity match, including L1 distance, weighted L1 distance, L2 distance, chi-square distance and improved Canberra distance as mentioned in Refs. [35, 25, 36]. Their similarity measures can be represented as follows:
L1 distance:
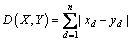 (13)
(13)
weighted L1 distance:
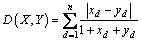 (14)
(14)

Figure 6 Some sample images:
L2 distance:
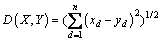 (15)
(15)
chi-square distance:
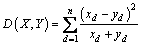 (16)
(16)
improved Canberra distance:
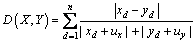 (17)
(17)
where 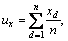
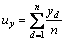 and n is the length of feature vector.
and n is the length of feature vector.
5.3 Performance evaluation metrics
A set of experiments are conducted on three databases to test the performance of proposed method and all images in the database are selected as the query image. The precision and recall are used to evaluate the performance of the proposed method for image retrieval [37]. The precision Pr and recall Rr can be defined as follows:
 (18)
(18)
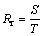 (19)
(19)
where S denotes the number of relevant images retrieved, N denotes the total number of images retrieved and T denotes the total number of relevant images in the database.
5.4 Retrieval performance of color intensity- based local difference patterns
First, the experimental results demonstrate that the improved Canberra distance is more suitable for the proposed method. Second, different quantization levels in HSV color space are applied to evaluate the performance of the proposed method and the final quantization levels of H and V components are confirmed. Third, the retrieval performances of proposed method are compared with other existing methods on Corel-1K, Coil-100 and Corel-10K databases.
5.4.1 Proposed method with different similarity measures
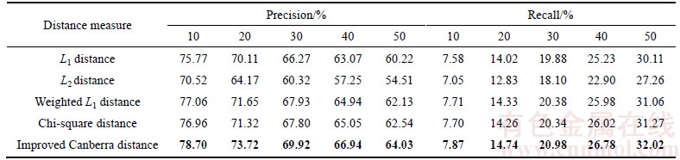
L1 distance, weighted L1 distance, L2 distance, chi-square distance and improved Canberra distance have been used for measuring the similarity between query image and images in the database. The average retrieval precision and recall of the proposed method with different similarity measures are listed in Table 2. The number of retrieved images is set from 10 to 50. It can be seen that the improved Canberra distance gives better results than other similarity measures. L2 distance is not always the best distance metric, because it puts more emphasis on features that are greatly dissimilar. L1 distance, weighted L1 distance and chi-square distance are also common similarity measures. However, they are not suitable for the proposed algorithm although they are good similarity measures. As shown in Eq. (17), the weight parameter is taken into account and ux and uy are used as smoothing factors [25, 38]. From Table 2, the performance of proposed algorithm is improved. Therefore, the improved Canberra distance is adopted as similarity measure between images for proposed retrieval system.
5.4.2 Different quantization levels of proposed method
In this experiment, the HSV color space is used. Different quantization levels of H, S and V components in HSV color space are used to evaluate the retrieval performance. The average retrieval precisions and recalls of proposed method with different quantization levels of H and V components for all the databases are listed in Table 3.
Table 2 Average retrieval precision and recall of proposed method with different distance measures for Corel-1K database
H component is quantized to 18, 36 and 72 bins respectively and S component is quantized to 10 and 20 bins. According to the experimental results, H 72 and S 20 provide best result for all databases. However, the performance of proposed method may be affected and the complexity of proposed method is high if the quantization number of color is too large. Therefore, H 72 and S 20 in HSV color space are employed to represent color feature.
5.4.3 Performance on Corel-1K database
Figure 7 displays the performance comparison of color intensity-based local difference patterns (CILDP) with the other existing methods in terms of precision and recall on Corel-1K database. The retrieval results show that CILDP achieves a much better performance than other methods. The precision of CILDP can reach 78.70% on Corel-1K database, while LBP, LCP, CS-LBP CLBP, LTP and LMP are only 66.75%, 56.59%, 51.52%, 69.43%, 69.87% and 56.51%. In order to illustrate the robust performance of CILDP for image category, CILDP are compared with other methods for each category on Corel-1K database and the number of retrieved images is set as 20. Table 4 shows the retrieval results of CILDP for each category on Corel-1K image database. As shown in Table 4, the precision and recall of CILDP are significantly higher than other methods in most categories. The precision and recall of CILDP are lower than other methods on flower category. This may be the interference of the salient object edge feature of flower images, and the performance of CILDP is reduced after combining color and texture features.
5.4.4 Performance on Coil-100 database
The precision-recall curves for Coil-100 image database are plotted in Fig. 8(a). It can be seen that the precision of CILDP can reach 93.83%, and its precision is 6.28%, 20.39%, 16.53%, 7.04%, 2.60% and 12.00% higher than those of LBP, LCP, CS-LBP, CLBP, LTP and LMP, respectively. Figures 8(b) and (c) display the precision and recall of CILDP and other methods for every category on Coil-100 database. It can be seen from the results that CILDP outperforms other methods in most categories on Coil-100 database.
5.4.5 Performance on Corel-10K database
Figure 9(a) displays the precision and recall curves on Corel-10K database. It can be seen that CILDP has a better performance than other methods. The precision of CILDP is 50.75%, and its precision is 12.90%, 28.33%, 25.84%, 8.41%, 9.04% and 19.36% higher than those of LBP, LCP, CS-LBP, CLBP, LTP and LMP, respectively. Figures 9(b) and (c) display the precision and recall of CILDP and other methods for every category on Corel-10K database. It can be seen from the results that CILDP outperforms other methods in most categories on Corel-10K database.
Two examples of the image retrieval on Corel-10K database by CILDP are displayed in Figure 10. As can be seen from Figure 10(a), the top-left image (No. 5806) is the query image and the top 20 retrieved images of CILDP show good match of color and texture to the query image. From Figure 10(b), the top-left image (No. 2712) is the query image and all the top 20 retrieved images of CILDP have very similar scene contents. These two examples validate that CILDP has discriminative power regarding texture and color features of natural images.
Table 3 Average precision (number of retrieved images is 10) and average recall (number of retrieved images is 50) of proposed method with different quantization schemes for different databases based on HSV color space. (Bold values indicate best results)
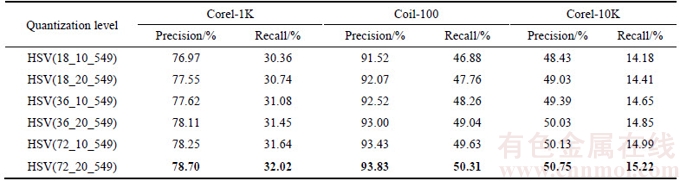
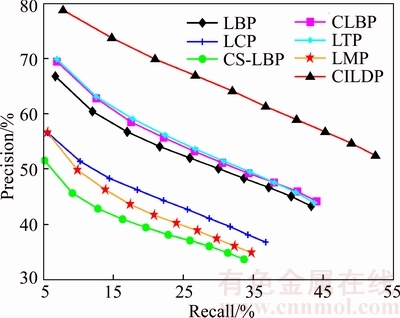
Figure 7 Performance comparison of proposed method with other existing methods in terms of precision and recall on Corel-1K database
5.5 Retrieval performance of proposed framework
In the experiments, all images in the database are selected as the query image to evaluate the performance of the proposed framework. The precision and number of top database candidates for Corel-1K, Coil-100 and Corel-10K are shown in Figure 11. The number of the retrieved images is set from 10 to 50 in these experiments. It can be observed from Figure 11 that the proposed fusion method achieves better retrieval results than BoW and CILDP.
The precision of proposed fusion method can reach 82.36%, and its precision is 14.40% and 7.87% higher than those of BoW and CILDP respectively for Corel-1K database with the top 20 retrieved image. The precision of the proposed fusion method can reach 94.15%, and its precision is 11.90%, 5.50% higher than those of BoW and CILDP respectively for Coil-100 database with the top 20 retrieved image. The precision of the proposed fusion method can reach 50.80%, and its precision is 15.79% and 8.83% higher than those of BoW and CILDP respectively for Corel-10K database with the top 20 retrieved image.
Table 4 Individual category retrieval results of proposed method and other methods on Corel-1K database.(Bold values indicate best results)
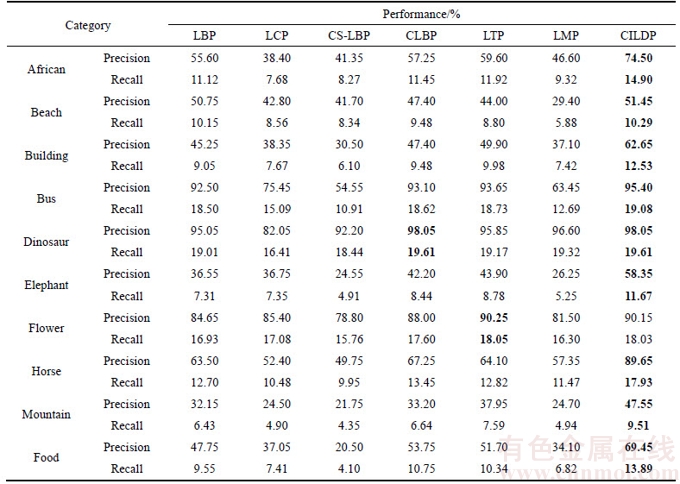
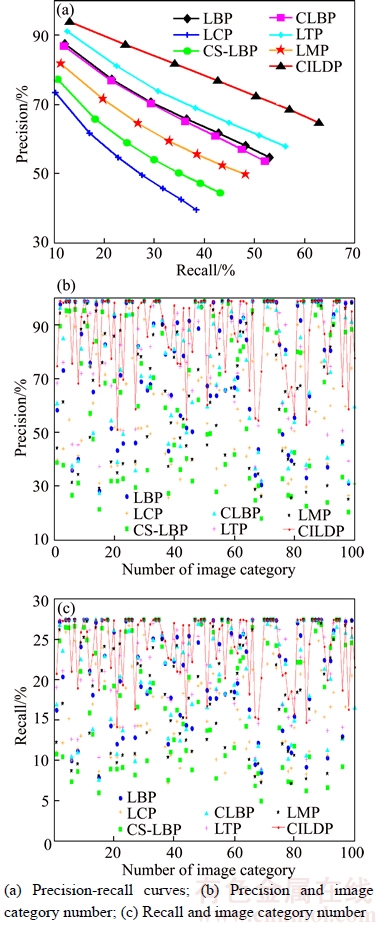
Figure 8 Retrieval performance on Coil-100 database:
Illustrative retrieval results of the proposed fusion method on three databases are shown in Figure 12. The top-left image is the query image. Top-9 candidates are shown for the fusion results (in the third row) of a query, using CILDP (in the first row) and BoW (in the second row). It can be seen that fusing BoW and CILDP features via graph density can significantly improve the performance of each individual feature.
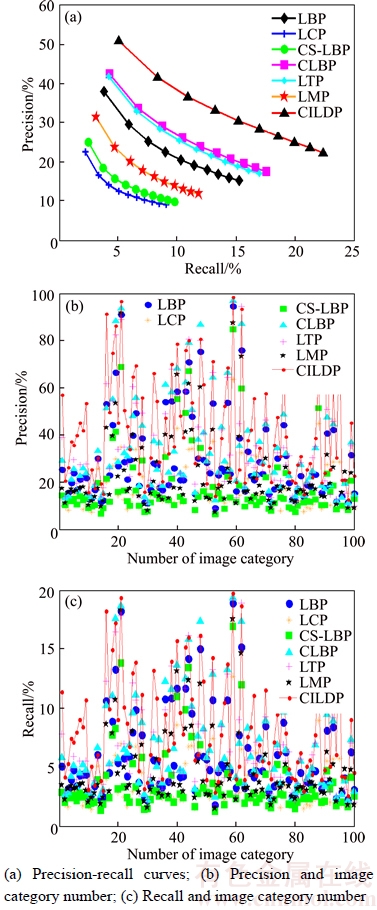
Figure 9 Retrieval performance on Corel-10K database:
5.6 Comparison with state-of-the-art methods
5.6.1 Performance comparison on Corel-1K database
In order to further evaluate the performance of the proposed framework, all images in the database are selected as query images and the number of retrieved image is 20. The average precisions for each category of the proposed framework and state-of-the-art methods are listed in Table 5. It is shown that the proposed framework achieves better retrieval results than other existing methods.
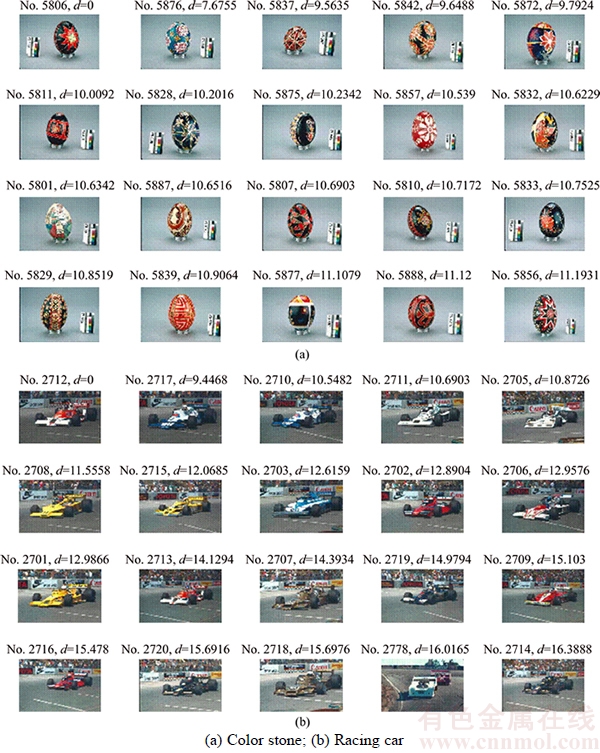
Figure 10 Image retrieval results of proposed method on Corel-10K database:(Top-left image is query image)
As shown in Table 5, the average precision of the proposed method outperforms all the methods presented in Refs. [20�C22, 39�C45]. It can be seen from the results that the average precision of our proposed method is significantly higher than the methods proposed in Refs. [21, 22, 41, 42, 44], which are 9.56%, 6.26%, 24.16%, 5.06% and 1.79% more accurate than methods of Refs. [20, 39, 40, 43, 45].
5.6.2 Performance comparison on Corel-10K database
In this experiment, the number of the retrieved images is 12. The retrieval performance of the proposed framework obtains 56.43% in terms of average precision on Corel-10K database which is better than 45.24% obtained through the color difference histogram (CDH) [25] based on the combination of color, edge orientation and perceptually uniform color difference features. It is also better than 47.25% obtained through the method described in Ref. [45], which incorporates the spatiogram representation with the quantized Gaussian mixture color model.
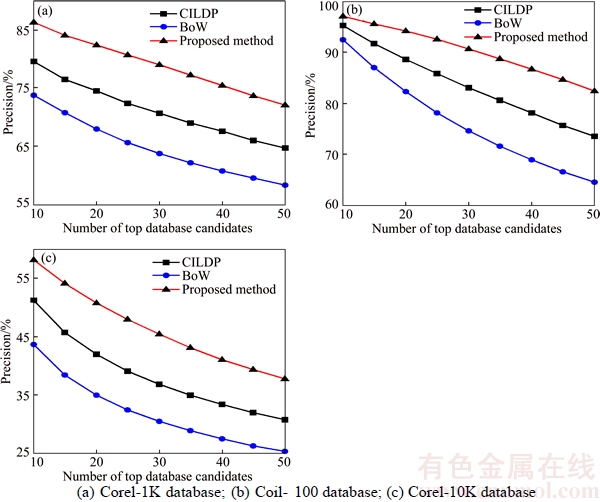
Figure 11 Precision and number of database candidates:

Figure 12 Three sets of retrieval results:
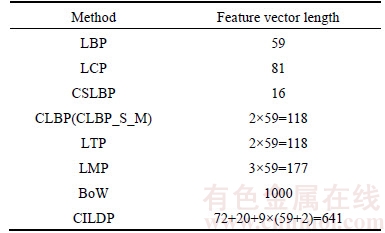
5.7 Feature vector length
Table 6 shows the feature vector length of query image using various methods. The feature vector length of proposed method is high but its performance is far better than other existing methods on different databases. Fortunately, a feature size of 641 is not a big problem for implementation.
6 Conclusions
1) A novel image feature descriptor called intensity-based local difference patterns (ILDP) is proposed to extract texture feature by using the HSV color space. This method considers the spatial relation of patterns in the image. H and S components are used to extract global color information. Then, the feature vector of CILDP is constructed by jointing the H, S component and ILDP histograms. CILDP is used on color and texture features.
Table 5 Comparison of different fusion techniques on Corel-1K database (Bold values indicate best results)
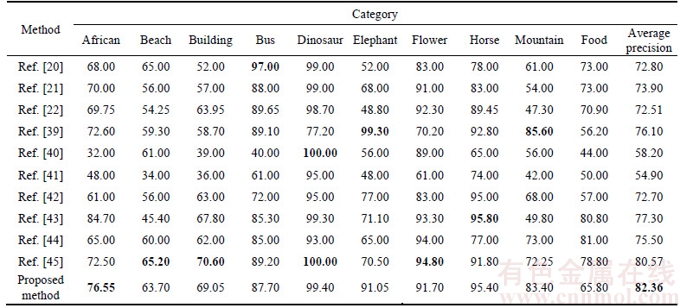
Table 6 Feature vector length of different methods
2) ILDP preserves weak edge patterns information and spatial structure information. And CILDP is more effective and discriminative as compared with traditional local pattern methods.
3) A novel and effective fusion framework is proposed for color image retrieval. It utilizes CILDP to extract global feature. The local features are extracted through the BoW model. Graph density method is employed to fuse CILDP and BoW features.
4) The proposed fusion framework significantly improves the performance of CILDP and BoW methods respectively by combining these two complementary features. An extensive set of experiments is carried out on different databases. The comparative analysis of our results with existing methods verifies the effectiveness of the proposed method for image retrieval.
References
[1] LIU Ying, ZHANG Deng-sheng, LU Guo-jun, MA Wei-ying. A survey of content-based image retrieval with high-level semantics [J]. Pattern Recognition, 2007, 40(1): 262�C282.
[2] PENATTI O A B, SILVA F B, VALLE E, GOUET-BRUNET V, TORRES R D S. Visual word spatial arrangement for image retrieval and classification [J]. Pattern Recognition, 2014, 47(2): 705�C720.
[3] DATTA R, JOSHI D, LI Jia, WANG J Z. Image retrieval: Ideas, influences, and trends of the new age [J]. ACM Computing Surveys (CSUR), 2008, 40(2): 5.
[4] SWAIN M J, BALLARD D H. Color indexing [J]. International Journal of Computer Vision, 1991, 7(1): 11�C32.
[5] STRICKER M A, ORENGO M. Similarity of color images [C]// Proceedings of IS&T/SPIE's Symposium on Electronic Imaging: Science & Technology. Bellingham: SPIE, 1995: 381�C392.
[6] HUANG Jing, KUMAR S R, MITRA M, ZHU Wei-jing, ZABIH R. Image Indexing Using Color Correlograms [C]// Proceedings of 1997 IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos, CA: IEEE Computer Society, 1997: 762�C768.
[7] PASS G, ZABIH R, MILLER J. Comparing images using color coherence vectors [C]// Proceedings of the Fourth ACM International Conference on Multimedia. New York: ACM, 1997: 65�C73.
[8] OJALA T, PIETIKAINEN M, MAENPAA T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7): 971�C987.
[9] HUANG Di, SHAN Cai-feng, ARDABILIAN M, WANG Yun-hong, CHEN Li-ming. Local binary patterns and its application to facial image analysis: A survey [J]. IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews, 2011, 41(6): 765�C781.
[10] HEIKKIL M, PIETIK INEN M, SCHMID C. Description of interest regions with local binary patterns [J]. Pattern Recognition, 2009, 42(3): 425�C436.
[11] GUO Yi-mo, ZHAO Guo-ying, PIETIK INEN M. Texture Classification using a Linear Configuration Model based Descriptor [C]// Proceedings of the British Machine Vision Conference (BMVC). Dundee, United Kingdom: Citeseer, 2011: 1�C10.
[12] TAN Xiao-yang, TRIGGS B. Enhanced local texture feature sets for face recognition under difficult lighting conditions [J]. IEEE Transactions on Image Processing, 2010, 19(6): 1635�C1650.
[13] GUO Zhen-hua, ZHANG Lei, ZHANG D. A completed modeling of local binary pattern operator for texture classification [J]. IEEE Transactions on Image Processing, 2010, 19(6): 1657�C1663.
[14] MURALA S, WU Q M. Local mesh patterns versus local binary patterns: Biomedical image indexing and retrieval [J]. IEEE Journal of Biomedical and Health Informatics, 2014, 18(3): 929�C938.
[15] ZHANG Gang, MA Zong-min, DENG Li-guo, XU Chang-ming. Novel histogram descriptor for global feature extraction and description [J]. Journal of Central South University of Technology, 2010, 17: 580�C586.
[16] LOWE D G. Distinctive image features from scale-invariant keypoints [J]. International Journal of Computer Vision, 2004, 60(2): 91�C110.
[17] BAY H, ESS A, TUYTELAARS T, VAN GOOL L. Speeded-up robust features (SURF) [J]. Computer Vision and Image Understanding, 2008, 110(3): 346�C359.
[18] RUBLEE E, RABAUD V, KONOLIGE K, BRADSKI G. ORB: An efficient alternative to SIFT or SURF [C]// Proceedings of 2011 IEEE International Conference on Computer Vision (ICCV). Piscataway, NJ: IEEE, 2011: 2564�C2571.
[19] SIVIC J, ZISSERMAN A. Video Google: A text retrieval approach to object matching in videos [C]// Proceedings of Ninth IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2003: 1470�C1477.
[20] SHEN Guan-lin, WU Xiao-jun. Content based image retrieval by combining color, texture and Centrist [C]// 2013 Constantinides International Workshop on Signal Processing (CIWSP 2013). Stevenage, GBR: IET, 2013: 1�C4.
[21] ELALAMI M E. A novel image retrieval model based on the most relevant features [J]. Knowledge-Based Systems, 2011, 24(1): 23�C32.
[22] SUBRAHMANYAM M, WU Q M J, MAHESHWARI R P, BALASUBRAMANIAN R. Modified color motif co-occurrence matrix for image indexing and retrieval [J]. Computers & Electrical Engineering, 2013, 39(3): 762�C774.
[23] LIU Guang-hai, YANG Jing-yu. Image retrieval based on the texton co-occurrence matrix [J]. Pattern Recognition, 2008, 41(12): 3521�C3527.
[24] LIU Guang-hai, ZHANG Lei, HOU Ying-kun, LI Zuo-yong, YANG Jing-yu. Image retrieval based on multi-texton histogram [J]. Pattern Recognition, 2010, 43(7): 2380�C2389.
[25] LIU Guang-hai, YANG Jing-yu. Content-based image retrieval using color difference histogram [J]. Pattern Recognition, 2013, 46(1): 188�C198.
[26] ZHANG Shao-ting, YANG Ming, COUR T, YU Kai, METAXAS D N. Query specific rank fusion for image retrieval [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(4): 803�C815.
[27] SINGHA M, HEMACHANDRAN K. Performance analysis of color spaces in image retrieval [J]. Assam University Journal of Science and Technology, 2011, 7(2): 94�C104.
[28] VADIVEL A, SURAL S, MAJUMDAR A K. An integrated color and intensity co-occurrence matrix [J]. Pattern Recognition Letters, 2007, 28(8): 974�C983.
[29] LIU Li, ZHAO Ling-jun, LONG Yun-li, KUANG Gang-yao, FIEGUTH P. Extended local binary patterns for texture classification [J]. Image and Vision Computing, 2012, 30(2): 86�C99.
[30] CROSS G R, JAIN A K. Markov random field texture models [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1983(1): 25�C39.
[31] GUO Zhen-hua, ZHANG Lei, ZHANG D. Rotation invariant texture classification using LBP variance (LBPV) with global matching [J]. Pattern Recognition, 2010, 43(3): 706�C719.
[32] ZHANG Xiao-fan, DOU Hang, JU Tao, ZHANG Shao-ting. Fusing heterogeneous features for the image-guided diagnosis of intraductal breast lesions [C]// Proceedings of 2015 IEEE 12th International Symposium on Biomedical Imaging (ISBI). Piscataway, NJ: IEEE, 2015: 1288�C1291.
[33] WANG J Z, LI Jia, WIEDERHOLD G. SIMPLIcity: Semantics-sensitive integrated matching for picture libraries [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(9): 947�C963.
[34] LI Jia, WANG J Z. Automatic linguistic indexing of pictures by a statistical modeling approach [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(9): 1075�C1088.
[35] ANTANI S, KASTURI R, JAIN R. A survey on the use of pattern recognition methods for abstraction, indexing and retrieval of images and video [J]. Pattern Recognition, 2002, 35(4): 945�C965.
[36] LIU Guang-hai, LI Zuo-yong, ZHANG Lei, XU Yong. Image retrieval based on micro-structure descriptor [J]. Pattern Recognition, 2011, 44(9): 2123�C2133.
[37] BESIRIS D, ZIGOURIS E. Dictionary-based color image retrieval using multiset theory [J]. Journal of Visual Communication and Image Representation, 2013, 24(7): 1155�C1167.
[38] LANCE G N, WILLIAMS W T. Mixed-data classificatory programs I-agglomerative systems [J]. Australian Computer Journal, 1967, 1(1): 15�C20.
[39] ELALAMI M E. A new matching strategy for content based image retrieval system [J]. Applied Soft Computing, 2014, 14(1): 407�C418.
[40] JALAB H. Image retrieval system based on color layout descriptor and Gabor filters [C]// Proceedings of 2011 IEEE Conference on Open Systems (ICOS). Piscataway, NJ: IEEE, 2011: 32�C36.
[41] HIREMATH P S, PUJARI J. Content based image retrieval using color, texture and shape features [C]// Proceedings of 2007 International Conference on Advanced Computing and Communications (ADCOM 2007). Piscataway, NJ: IEEE, 2007: 780�C784.
[42] BANERJEE M, KUNDU M K, MAJI P. Content-based image retrieval using visually significant point features [J]. Fuzzy Sets and Systems, 2009, 160(23): 3323�C3341.
[43] GUO Jing-ming, PRASETYO H, SU Huai-sheng. Image indexing using the color and bit pattern feature fusion [J]. Journal of Visual Communication and Image Representation, 2013, 24(8): 1360�C1379.
[44] IRTAZA A, JAFFAR M A, ALEISA E, CHOI T S. Embedding neural networks for semantic association in content based image retrieval [J]. Multimedia Tools and Applications, 2014, 72(2): 1911�C1931.
[45] ZENG Shan, HUANG Rui, WANG Hai-bing, KANG Zhen. Image retrieval using spatiograms of colors quantized by Gaussian Mixture Models [J]. Neurocomputing, 2016, 171(1): 673�C684.
(Edited by FANG Jing-hua)
���ĵ���
ȫ�ֺ;ֲ�������ͼ�����
ժҪ�����ֻ��ڶ������ںϵ�ͼ������������зdz��õ����ܡ����ǣ��������ںϷ��������������⣺1) ����ɫ�ռ���ֱ�Ӷ��������ṹ�ķ������������ɫ������������2) ��ȡ���������������ں�Ϊһ�������ķ��������ַ�������Ч����������Ч������ֱ�ӽ�Ϻ���Ч�������ή�ͼ������ܡ�����������⣬���һ���µĻ�Ͽ�����ڲ�ɫͼ��������ÿ��ʹ�ôʴ�ģ��(bag-of-visual words, BoW)����ɫǿ�Ⱦֲ����ģʽ(color intensity-based local difference patterns, CILDP)�ֱ���ȡͼ��IJ�ͬ������Ϣ��ͬʱ��������ںϿ������graph density�ķ�����BoW��CILDP��������������Ч�ںϣ����øÿ���ܹ����ͼ������ľ��ȡ���Corel-1K���ݿ��ϣ�����10��ͼ��ʱ������Ŀ�ܵ�ƽ������Ϊ86.26%���ֱ��CILDP��BoW����˴�Լ6.68%��12.53%���ڲ�ͬ���ݿ��ϵĴ���ʵ��Ҳ��֤�˸ÿ����ͼ������ϵ���Ч�ԡ�
�ؼ��ʣ��ֲ���ֵģʽ��ɫ�������Ͷȡ����ȣ�HSV����ɫ�ռ䣻ͼ�ںϣ�ͼ�����
Foundation item: Projects(61370200, 61672130, 61602082) supported by the National Natural Science Foundation of China; Project(1721203049-1) supported by the Science and Technology Research and Development Plan Project of Handan, Hebei Province, China
Received date: 2016-05-17; Accepted date: 2016-11-03
Corresponding author: FENG Lin, Professor, PhD; Tel: +86�C411�C84707111; E-mail: fenglin@dlut.edu.cn; ORCID: 0000-0001- 7045-4727

