一种结构化Web文档的联合聚类算法
邓冬梅1,龙际珍2,尹湘舟3
(1. 湖南师范大学 计算机教学部,湖南 长沙,410081;
2. 长沙理工大学 计算机与通信工程学院,湖南 长沙,410114;
3. 中国科学院 计算技术研究所,北京,100190)
摘 要:为了对网上多媒体信息进行有效检索和过滤,提出一种基于文本和图片相似性融合的联合聚类算法。首先通过相似性计算得到文本相似性和图片相似性,然后,将所得文本相似性矩阵和图片相似性矩阵进行水平拼接融合,经奇异值分解后,进行k-means联合聚类,使得聚类后的结果融合文本信息和图片信息。研究结果表明:与单一图像联合聚类方法相比,采用联合聚类算法所得每一簇的F-Measure值都有明显提高,与单一文本联合聚类在第1,2,3和7簇的F-Measure值也有所提高。
关键词:联合聚类;相似性融合;结构化文档
中图分类号:TP391 文献标志码:A 文章编号:1672-7207(2010)05-1871-06
A co-clustering algorithm based on structured Web document
DENG Dong-mei1, LONG Ji-zhen2, YIN Xiang-zhou3
(1. Education Department of Computer, Hunan Normal University, Changsha 410081, China;
2. College of Computer and Communication, Changsha University of Science and Technology, Changsha 410114, China;
3. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China)
Abstract: A similarity fusion algorithm about the text and image co-clustering of multimedia structured documents was given in order to perform multimedia retrieval and filter efficiently. This method fuses text similarity matrix and image similarity matrix to make a fusion similarity matrix and then it is co-clustered with k-means algorithm after eigenvector decomposition. This algorithm was tested on the task of multimedia structured documents which had two information sources, i.e., text and image. The results show that the F-Measure value in all clusters obtained by the co-clustering algorithm based on structured Web document are larger than those obtained by a flat image co-clustering and the F-Measure value increases in the first, second, third, seventh cluster compared to those obtained by flat text co-clustering.
Key words: co-clustering; similarity fusion; structured document
聚类是网上多媒体检索和过滤常用的一种方 法[1-2],依据事物的某些属性将其聚集成类,使同类间相似性尽量小,类与类之间相似性尽量大,是一种无监督的模式识别问题。很多聚类方法都是基于单一文本聚类[3-4]和单一图片聚类[5]。然而,有时不仅需要对单一的文本信息或图片信息进行聚类,还需要对一些属性信息同时进行聚类,以便挖掘更多有用的信息[6],这就需用到联合聚类的思想。Dhillon[7]在2001年提出了基于二部图划分思想来解决联合聚类的问题,这是目前联合聚类方法最常用的一种方法。Giannakidou等[8]介绍了一种标签和社会资源的联合聚类方法,它是一种基于文本的图像联合聚类方法。现在网络上的多媒体信息通常不是单一的文本信息或图片信息,它所呈现的是一种结构化文档的特性,融合了文本信息和图片信息。许多研究者开始研究包含这2种信息在内的Web文档检索。Chen等[9]采用线性组合方式实现文本信息和图像低层视觉信息的融合来检索图像。Blei等[10]使用LDA(Latent dirichlet alfocation)模型捕获图像视觉特征和文本特征之间的联合概率分布以及条件概率分布。Denoyer等[11]介绍了一种结构化文档的分类方法,该方法结合结构化文档的文本信息和图片信息对结构化文档进行有效分类。利用这种结构化文档分类的思想,本文作者在考虑文本自身相似性的基础上,引入图片自身内容信息之间的相似性,再通过文本和图片相似性融合实现结构化Web文档的联合聚类,从而实现Web文档的快速检索与过滤。
1 问题描述
一个结构化文档称为一个资源,它不仅包含图片信息,还包含用来描述图片的标签(描述图片资源的特征词),分别用R,T,AS,P分别表示资源、标签、属性、图片集合[8],并从图片信息中选择最具有特征的m个图片作为图片关键词,用PF表示。这样,问题就可以描述为资源―属性―图片关键词联合聚类的问题:给定资源集R、图片集P、属性集AS、图片关键词集合PF、整数k和相似函数,由联合聚类得到一个集合C且Cx(1≤x≤k)包含有资源、属性或图片关键词,使 最大(i=1, …, n; j=1, …, d; t=1, …, m)。其中:similarity(ri, aj)表示资源与属性之间的相似性;similarity(pi, ft)表示图片与图片关键词之间的相似性。
最大(i=1, …, n; j=1, …, d; t=1, …, m)。其中:similarity(ri, aj)表示资源与属性之间的相似性;similarity(pi, ft)表示图片与图片关键词之间的相似性。
2 融合文本和图片信息的联合聚类算法
2.1 文本相似性融合
每个资源都可以用标签来表示,而属性集由d个出现频率最高的标签组成,这样,资源与属性之间的相似性就转化为标签之间的相似性。为了更好地表示2个标签之间的相似性,可以同时考虑它们的社会相似性和语义相似性。
语义相似性是利用Ohillon[7]所提出的方法,来计算词的语义相似程度。tx和ty是标签T1和T2的本体映射概念,则语义相似性定义为:
 (1)
(1)
depth(tx)表示从tx到tx和ty共同父节点的路径长度;depth(P)表示从tx和ty的共同父节点到最终的祖节点的路径长度。
社会相似性是通过关键词同时出现在不同文档中的概率来计算,则2个标签tx和ty之间的社会相似性表示为:
 ,1≤x, y≤1, ri∈R (2)
,1≤x, y≤1, ri∈R (2)
为了考察每种相似性对聚类结果的影响,2个标签之间的相似性可用这2种相似性的权重之和来表示。利用文献[10]中的方法,2个标签之间总的相似性可表示为:
 (3)
(3)
其中:w为语义相似性和社会相似性之间的权值。若w=1,则表示单独的语义相似性;若w=0,则仅仅表示社会相似性。当w取任何其他值时,2种相似性都起作用,但是,其作用要看w取值。这样,资源的标签信息与属性之间的相似函数就可以表示为:
 ,
, (4)
(4)
则n个资源和d个属性之间的相似性就构成了1个 n×d的矩阵RA:
RA(i, j)=sim(ri, aj); i=1,…, n; j=1,…, d (5)
2.2 文本和图片相似性融合
目前,计算图片之间相似性的方法很多,如绝对值距离计算法、欧氏距离法、余弦距离和直方图的相关系数法、卡方法、相交法和Bhattacharyya 距离法等等,还有基于SIFT特征提取的计算方法。
对于整个图片资源集合,首先人工按图片内容信息将图片资源分类,然后,从每个类中挑选一些能代表这些类的图片,称为图片关键词。图片之间的相似性simp(pi, fj)定义为图片和关键词之间的相似性:
 ;
;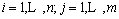 (6)
(6)
其中:N表示pi与fj匹配的关键点个数; 代表pi中关键点个数。
代表pi中关键点个数。
本文在进行图片相似性计算时,利用了基于SIFT特征提取的计算方法、直方图的相关系数法、卡方法、相交法和Bhattacharyya 距离法,然后,对几种方法进行比较。对于n个图片资源和m个图片关键词的数据集合,计算它们之间的相似性,这些相似性构成了 n×m阶矩阵PF,
 ; i=1,…, n; j=1,…, m (7)
; i=1,…, n; j=1,…, m (7)
文本相似性矩阵和图片相似性矩阵的行都是用标签信息表示的资源信息,因此,可以进行矩阵的水平拼接融合。由式(5)和(7),定义文本和图片相似性融合矩阵:
 ; i=1,…,n; j=1,…,(d+m) (8)
; i=1,…,n; j=1,…,(d+m) (8)
式(8)中: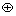 表示矩阵RA和PF水平拼接融合。文本和图片相似性矩阵融合以后,融合矩阵中既包含了文本的相似性,也包含了图片的相似性。
表示矩阵RA和PF水平拼接融合。文本和图片相似性矩阵融合以后,融合矩阵中既包含了文本的相似性,也包含了图片的相似性。
2.3 联合聚类算法
文本和图片融合后的相似性矩阵为 。
。 矩阵的行向量代表的依然是图片资源,前d列向量是属性列,后m列向量是图片关键词列。为了便于有效聚类,同时减少特征向量的维度,在联合聚类前对
矩阵的行向量代表的依然是图片资源,前d列向量是属性列,后m列向量是图片关键词列。为了便于有效聚类,同时减少特征向量的维度,在联合聚类前对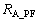 进行奇异值分解:
进行奇异值分解:
 (9)
(9)
 和
和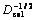 分别为对角矩阵。用Lrow和Rcol分别表示矩阵的左奇异向量和右奇异向量,为了同时对资源、属性和图片关键词进行聚类,定义矩阵
分别为对角矩阵。用Lrow和Rcol分别表示矩阵的左奇异向量和右奇异向量,为了同时对资源、属性和图片关键词进行聚类,定义矩阵
 ,则可以对矩阵SV进行k-means方法的联合聚类。文本和图片融合联合聚类算法如下。
,则可以对矩阵SV进行k-means方法的联合聚类。文本和图片融合联合聚类算法如下。
输入:n个资源集R,n个图片资源集p,l个Tags集合T,整数k和w∈[0, 1]
输出:1个有k个簇的集合C,且每个簇中都包含资源、图片关键词和属性,并且使得簇内部的相关性最大,而簇之间的相关性最小。
第1步:Tunitags=UnitaryTags(T); /*标签拼写归一化*/;
第2步:PureTag=EliminateNoiseTags(Tunitags); /*过滤标签*/;
第3步:Attribs=ExtractAttrib(PureTag); /*抽取频率最高的标签形成属性集*/;
第4步:PurePict=E liminateNoisePict(p); /*过滤噪音图片*/;
第5步:PictFeat=ExtractPictKey(PurePict); /*抽取图片特征*/;
第6步:PKEY=ExtractPictKey(PurePict); /*形成图片关键词*/;
第7步:SOS=CalculateSocialSimilarity(R, Attribs); /*计算文本相似性RA*/;
第8步:SES=CalculateSemanticSimilarity(R, Attribs);
第9步:RresAttribSS=w*SES+(1-w)*SOS;
第10步:RA=RresAttribSimilarityScore(RresAttrib SS);
第11步:PictPictKeySS=CalculateSimilarity(Pure Pict, PKEY, PictFeat); /*计算图片相似性PF*/;
第12步:PF=SimilarityScore(PictPictKeySS);
第13步:RA_PF=MatrixFusion(RA, PF); /*将RA和PF水平拼接形成RA_PF*/;
第14步:Drow=CalculatePictDiagMatrix(RA_PF); /*形成矩阵NAR_PF*/;
第15步:Dcol=CalculatePictKeyDiagMatrix(RA_PF);
第16步:(Drow-1/2, Dcol-1/2)=CalculateMitrix(Drow, Dcol);
第17步:NAR_PF=CalculateNormalizedMatrix(Drow, Dcol); /*计算得到NAR_PF的左奇异向量Lrow和右奇异向量Rcol*/
第18步:(Lrow, Rcol)=GETLeftRightSingularVector (NRA_PF);
第19步:SV=CreatUltimatelyMatrix(Drow-1/2, Dcol-1/2, Lrow, Rcol); /*构成矩阵SV */
第20步:C=K-Means(SV, k); /*对SV进行k-means聚类*/
为了获得更高效的聚类效果,首先对实验数据进行预处理,标签拼写归一化(第1步)和过滤掉缺少严格意义并且不能映射具体概念的标签(第2步),抽取频率最高的标签形成属性集(第3步)。对图片的预处理首先是过滤噪音图片(第4步),抽取图片特征(第5步),最后形成图片关键词(第6步)。预处理完成后进入相似性计算阶段,通过计算文本相似性RA (第7~10步)和图片相似性PF(第11~12步),然后将RA和PF水平拼接形成RA_PF(第13步)。当得到融合后的矩阵RA_PF,就可以进入联合聚类的处理过程,通过计算对角矩阵Drow和Dcol,形成矩阵NAR_PF(第14~17步),然后计算得到NAR_PF的左奇异向量Lrow和右奇异向量Rcol (第18步),这样,Drow-1/2, Dcol-1/2, Lrow和Rcol就构成了矩阵SV (第19步)。最后,对SV进行k-means聚类(第20步),可得到k类包含资源、属性和图片信息的簇。
3 实验结果与讨论
3.1 实验数据集和实验方法
本文实验都是基于一个文本特征和图像特征相融合的Web图片检索系统。该系统建立在一个扩展性良好的统一框架上,系统核心采用C/C++编码,实现了文本和图片的特征提取、融合、文档的高效聚类以及统一的数据集和数据I/O模块。实验所使用的数据集是利用Flickr网站提供的API,从该网站下载,包括由cityscape,seaside,mountain,roadside,landscape,sport和locations组成的7个场景近7 000幅(每个场景大约有1 000幅)结构化文档的图像。每个场景表示联合聚类中的1个类,即1个簇。这些图像分别包含图片信息以及图片所对应的文本信息。每个场景的图片信息用1个文件夹保存,文件夹的命名就是这个场景的名字。每个场景中所有图片的文本信息用1个大的txt文件保存,每张图片的文本信息叫做1条记录。记录中有图片的名字、URL、描述信息、tags信息。Flickr网站的一个特点就是tags信息是人为地标注上去的,比其他任何信息都能很好地表述图片内容的语义信息,所以,文本的特征提取是从图片的tags信息中得到。由文本和图片特征提取模块提取大量文本特征向量和图片关键点,创建特征参数。然后,将文本特征和图片特征融合在一起,进行联合聚类,最后分析聚类结果。
3.2 实验结果分析
在实验过程中,采用精确率和召回率来评价聚类结果。精确率高和召回率低(把一些本应该在一个簇的聚类予以分开)表明聚类的结果就好,RCj和ACj分别表示属于簇Cj的资源集合和属性集合。簇Cj的精确率和召回率定义如下:
 (10)
(10)
 (11)
(11)
在很多聚类的评估方法中,通常也用F-Measure值同时反映精确率和召回率。根据精确率和召回率的定义,1个簇Cj的F-Measure值可定义为:
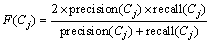 (12)
(12)
F-Measure的值F(Cj)在区间[0, 1]之间波动,其值越高,表示聚类越好。
3.2.1 文本联合聚类分析
首先从实验数据集中初步提取所有图片的文本信息,经过文本相似性计算后进行k-means方法联合聚类。试验时实验数据取自7个场景,所以,簇数k取为7,w (社会相似性和语义相似性的权重)设置为0.2,0.5和0.8。由式(10)和(11)算出每个聚类所获得的精确率和召回率,然后,按式(12)推导出每一簇的F-Measure值,如图1所示。可以看出:当w=0.5时,与w=0.2和w=0.8相比,它在编号为2,4,5和6的4个簇中取得的值较高,在另外3个其值稍低。总体来说,它能产生较好的聚类效果。
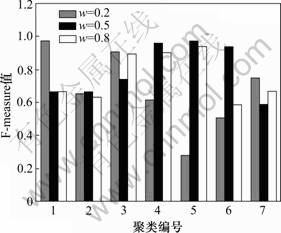
图1 文本聚类F-measure值
Fig.1 F-measure value of text co-clustering
3.2.2 图片联合聚类分析
对实验数据集中所有图片单一进行k-means聚类时,用到的图片相似性矩阵包括:
(1) 根据SIFT特征提取法计算所得的相似性 矩阵;
(2) 利用相关系数(CORREL)法计算图片所得的相似性矩阵;
(3) 利用卡方(CHISQR)法计算图片所得的相似性矩阵;
(4)利用交集法计算图片所得的相似性矩阵;
(5) 利用Bhattacharyya距离计算图片所得的相似性矩阵。
此时k取为7,算出每个簇的精确率和召回率以及F-Measure值。图2所示为图片联合聚类的F-Measure值。从图2可以看出:单纯地依靠图片特征信息进行聚类的效果不是十分理想,其中,BHATTACHARYYA方法所得到的F-Measure值较高,但是,也没有超过50%。其原因是现在所有的直接从图片的特征信息计算图片相似性的方法还不能很好地表达它们之间的相似性,计算机对图片的理解程度还

图2 图片联合聚类F-measure值
Fig.2 F-measure value of image co-clustering
不能达到人对图片的理解程度。
3.2.3 文本和图片融合联合聚类分析
对文本和图片融合后的数据进行k-means联合聚类时,取聚类数k为7,w为0.5,文本聚类效果最好。用SIFT特征提取法、直方图的相关系数法(CORREL)、直方图卡方法(CHISQR)、直方图交集法 (INTERSECT)和Bhattacharyya距离法这5种方法计算图片相似性矩阵,然后,分别与文本相似性矩阵融合进行实验,所得每簇的精确率和召回率如表1和表2所示。从表1和表2可看到:采用BHATTACHARYYA方法得到的相似性矩阵和文本相似性矩阵融合的结果最好。
为了比较融合以后与单一文本、图片的聚类效果,在图3中文本的聚类效果w取0.5,图片的聚类方法取BHATTACHARYYA,融合的聚类方法取BHATTACHARYYA,与文本融合。从图3可以看出:融合后效果比单纯的图片联合聚类的效果要好很多,F-Measure值基本上是单纯的图片联系聚类的2倍以上。与文本聚类进行比较,在第1,2,3和7簇都比文本的高,在第4~6簇时聚类稍差。由此可以推断:融合后的联合聚类结果比单独进行文本和图片聚类的效果好。
表1 文本和图片融合联合聚类精确率
Table 1 Precision rate of text and image integration co-clustering

表2 文本和图片融合联合聚类召回率
Table 2 Recall rate of text and image integration co-clustering
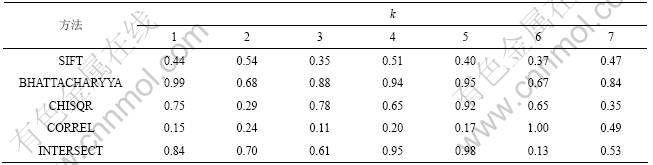

图3 文本、图片和文本图片融合聚类F-measure值对比
Fig.3 F-measure value’s comparison of three approaches
4 结论
(1) 在进行文本联合聚类时,社会相似性与语义相似性的权重w对聚类结果有影响:当w为0.2时,社会相似性居主要地位;当w取0.8时,语义相似性居主要地位;而当w取0.5时,二者的权重相等,而此时的聚类效果最好。
(2) 在进行图片聚类时,聚类效果很不理想。原因是现在一些计算图片相似性的方法还不能很好地表达2张图片之间的相似性。
(3) 文本和图片融合联合聚类效果最好。对于网络所呈现的多媒体结构化信息,单靠基于文本或图片的聚类方法不能满足聚类的精确性和高效性。融合文本相似性和图片相似性的联合聚类方法能有效针对结构化Web文档的特征,使得聚类效果更精确,从而为进一步有效进行多媒体检索和过滤研究提供一种新的研究方法。
参考文献:
[1] ZHANG Yan-chun, XU Guan-dong. Using Web clustering Web communities mining and analysis[C]//Web Intelligence and Intelligent Agent Technology. Sydney, 2008: 78-85.
[2] Fakouri R, Zamani B, Fathy M. Region-based image clustering and retrieval using fuzzy similarity and relevance feedback[C]//2008 International Conference on Electrical Engineering. Lahore, 2008: 343-347.
[3] 刘远超, 王晓龙, 刘秉全, 等. 信息检索中的聚类技术[J]. 电子与信息学报, 2006, 28(4): 606-609.
LIU Yuan-chao, WANG Xiao-long, LIU Bing-quan, et al. The clustering analysis technology for information retrieval[J]. Journal of Electronics & Information Technology, 2006, 28(4): 606-609.
[4] Dhillon I S, Modha D S. Concept decompositions for large sparse text data using clustering[J]. Machine Learning, 2001, 42(1): 143-175.
[5] 刘康苗, 仇光, 陈纯, 等. 基于视觉和语义融合特征的阶段式图像聚类[J]. 浙江大学学报: 工学版, 2008, 42(12): 2043-2048.
LIU Kang-miao, QIU Guang, CHEN Chun, et al. Structured image clustering based on fusion of visual and semantic features[J]. Journal of Zhejiang University: Engineering Science, 2008, 42(12): 2043-2048.
[6] Djouak A, Maaref H. Two levels similarity modelling: A co-clustering approach for image classification[C]//2009 6th International Multi-Conference on System, Signals and Devices. Djerba, 2009: 803-807.
[7] Dhillon I S. Co-clustering documents and words using bipartite spectral graph partitioning[C]//Proc of the 7th ACM SIGKDD Int Conf on Knowledge Discovery and Data mining. New York, 2001: 269-274.
[8] Giannakidou E, Koutsonikola V, Vakali A, et al. Co-clustering tags and social data sources[C]//The Ninth International Conference on Web-Age Information Management. Zhangjiajie, 2008: 317-324.
[9] Chen Z, Wenyin L, Zhang F, et al. Web mining for Web image retrieval[J]. Journal of the American Society for Information Science and Technology, 2001, 52: 831-839.
[10] Blei D M, Jordan M I. Modeling annotated data[C]//Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Toronto, 2003: 127-134.
[11] Denoyer, Jean-Noel Vittaut, Patrick Gallinari, et al. Structured multimedia document classification[C]//Proceedings of the 2003 ACM Symposium on Document Engineering. New York, 2003: 153-160.
[12] Wu Z, Palmer M. Verb semantics and lexical selection[C]//Proc of the 32nd annual meeting of the association for computational linguistics. Annual Meeting of the ACL. New Mexico: Association for Computational Linguistics, 1994: 133-138.
[13] Lowe D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110.
[14] Hartigan J A. Direct clustering of a data matrix[J]. Journal of the American Statistical Association, 1972, 67: 123-129.
[15] 白雪生, 徐光佑. 基于内容的图像检索及其相关技术的研究[J]. 机器人, 1997, 19(3): 231-240.
BAI Xue-sheng, XU Guang-you. Images searching based on content and research on related technology[J]. Robot, 1997, 19(3): 231-240.
[16] 袁承兴. 基于内容的图像检索技术研究[D]. 西安: 西安理工大学计算机科学与工程学院, 2008: 40-63.
YUAN Cheng-xing, Research of images searching technology based on content[D]. Xi’an: Xi’an Technological University. Institute of Computer Science and Engineering, 2008: 40-63.
[17] 黄鹏. 基于文本和视觉信息融合的Web图像检索[D]. 杭州: 浙江大学计算机科学与技术学院, 2008: 33-50.
HUANG Peng. Web images searching based on texts and images’ integration[D]. Hangzhou: Zhejiang University. Institute of Computer Science and Technology, 2008: 33-50.
(编辑 陈灿华)
收稿日期:2009-10-27;修回日期:2010-02-29
基金项目:湖南省教育厅项目(09c647)
通信作者:邓冬梅(1974-),女,湖南龙山人,硕士,讲师,从事计算机软件、人工智能研究;电话:15111220782;E-mail: teacherddm@sina.com

