文章编号:1004-0609(2007)07-1201-06
基于核偏最小二乘法的动态预测模型在
铜转炉吹炼中的应用
宋海鹰,桂卫华,阳春华,彭小奇
(中南大学 信息科学与工程学院,长沙 410083)
摘 要:为实现铜转炉吹炼过程中的关键操作参数的准确预测,构造一种基于核偏最小二乘法的动态预测模型,并提出一种适用于动态建模的在线式异常样本剔除方法。该动态预测模型使用滑动窗方法不断更新建模数据,再利用核偏最小二乘法对动态模型的参数进行辨识,最后根据反馈的前次计算误差对本次预测值进行修正。仿真研究结果表明:该动态预估模型具有较好的泛化能力和较强的鲁棒性,并具有较好预测精度(风量预测的相对均方根误差小于10%,氧量预测的相对均方根误差小于19%)。目前,该预测模型被用于某转炉的吹炼辅助决策系统中。
关键词:动态预测模型;在线式异常样本剔除;核偏最小二乘法;关键操作量预测;铜转炉吹炼
中图分类号:TP 18 文献标识码:A
Application of dynamical prediction model based on kernel partial least squares for copper converting
SONG Hai-ying, GUI Wei-hua, YANG Chun-hua, PENG Xiao-qi
(School of Information Science and Engineering, Central South University, Changsha 410083, China)
Abstract: In order to predict accurately the key operational parameters in copper converting process, a dynamical prediction model based on kernel partial least squares was constructed, and a method of online eliminating abnormal samples for dynamical model was presented. Firstly, moving widow method was utilized to update samples continuously in dynamical prediction model. Then, kernel partial least squares was used to identify parameters of dynamical model. Lastly, the prediction values were modified according to the last feedback computing errors. The simulation result shows that this dynamical prediction model has the performances like, better generalization, stronger robust, and preferable accuracy (the relative root mean square error of air is lower than 10%, and the relative root mean square error of oxygen is lower than 19%). Now, the prediction model is applied in the assistant decision-making system for a copper converter.
Key words: dynamical prediction model; online eliminating abnormal samples; kernel partial least squares method; copper converting
现代铜的火法生产中,闪速熔炼完成了铜与大部分铁的分离获得铜锍,然后在铜转炉中进行铜锍吹炼,从而进一步除去铜锍中的铁、硫和其它杂质,获得纯度为98%以上的粗铜。铜锍的吹炼过程绝大多数是在卧式侧吹(Peirce-Smith, PS)转炉内进行的。吹炼过程为间歇式的周期性作业,整个过程分为2个阶段:造渣期和造铜期。
目前,铜转炉的生产方式仍为人工操作方式,生产质量依赖于工人的技术水平。因此,对吹炼过程中操作参数的准确预报能使相关操作人员事先知道操作的结果,有利于实现流程工业过程的预测控制、保持工况稳定。由此可见,实现铜PS转炉吹炼过程中关键操作参数―风量和氧量的预测将日趋重要。
神经网络建模方法是目前最常用的一种稳态操作条件下基于生产数据的建模方法[1-5],例如为优化铜锍生产,彭小奇等[6]采用BP神经网络对PS转炉造铜期的氧量进行了预测,取得一定效果。但传统的神经网络建模方法都是立足于样本数目足够多的前提下,所提出的各种预测方法只有在样本数趋向于无穷大时其性能才有理论上的保证。而在多数实际情况中,样本数目通常是有限的,这使得神经网络方法难以取得理想的效果。因此,小样本预测一直是学者们研究的热点问题。
支持向量机作为一种常用的小样本统计建模方法,目前正得到越来越多的应用[7-9],但由于这一建模方法需要事先对折中系数(罚系数)和核参数进行优化选择,因此,将其作为实时动态模型应用颇为不便。而基于核偏最小二乘回归的统计建模法,则是另一种有效的小样本非线性建模方法[10-12]。
由于造渣期是整个吹炼过程的关键环节,造渣的好坏直接决定了吹炼最终产品―粗铜的质量,因此,铜转炉造渣期中关键操作量―氧量和风量的预测问题,是一个具有重要研究价值的实际生产问题。造渣期被分为造渣S1期和造渣S2期,其中造渣S2期是造渣期的最后一个阶段。因此,能否准确预测造渣S2期风量和氧量是优化整个吹炼过程的关键。
为满足工业生产中实现对造渣S2期风量和氧量的实时预估,本文作者首先建立了一种基于核偏最小二乘回归法的动态预测模型,并提出了一种配合此动态模型使用的异常数据在线剔除方法,最后利用该模型对铜转炉吹炼造渣S2期所需总风量和总氧量进行预测。
1 基于核偏最小二乘回归的动态预测模型
1.1 动态模型的结构
工业过程通常都很复杂,外界对过程的种种扰动难以把握,因此,仅依靠工业过程的机理很难建立准确的数学模型。但是,在生产设备运行稳定、工作条件相似时,扰动的变化范围有限。因此,可以通过历史数据样本,得出一个过程的预估模型。以铜转炉吹炼风、氧量操作参数的预报为例,可以认为当前的输出参数值由邻近时段内的输入参数值所决定。因此,在构造非线性动态预测模型时,k+1时刻的输出可以表示为前n个输入的函数(FIR模型),公式表示如下:
y(k+1)=f(x(k), …, x(k-n+1))+e (1)
式中 x(k)、y(k)分别为工业过程的第k次(或第k班、第k时刻)输入向量和输出向量,n为输入的影响延迟步数(阶数),f表示某种函数关系,而e是由于扰动引起的误差。
根据实际生产情况,模型的系数需要及时调整,以跟踪生产过程的趋势,因此,本文中作者进一步采用了滑动窗技术,根据及时更新的检测数据,建立了动态的转炉吹炼风量和氧量的预估模型。滑动窗口中的样本数据排列成一个二维矩阵,其中行的维数为窗口内各变量分别在k、k-1、k-2处所取样本值依次排列所成序列的尺度;而窗口中的各列,则是自变量在各时刻值所组成的数据序列。本文中将利用第k、k-1、 k-2时刻的自变量数据与第k+1时刻的因变量,建立的动态模型如下所示:

1.2 基于核偏最小二乘的参数辨识
由式(2)可见,动态模型的参数辨识问题是建模的关键。一般而言,最小二乘法是最常采用的参数辨识方法,但这种辨识方法在辨识列维数远大于行维数的参数矩阵时,特别是当X中的变量存在严重的多重相关性时,效果不好。
而由Wold等[13]提出的偏最小二乘回归法(Partial Least Square Regression,PLS)作为第二代最小二乘回归技术,可以较好地解决消除自变量间的线性相关关系,因此可以作为解决不稳定估计问题的有效方法。该方法通过最大化从自变量矩阵和因变量矩阵中提取自变量矩阵主成分t和因变量矩阵主成分u间的协方差,找到能最大包含数据矩阵X和Y的信息的主成分,继而将原数据空间中的回归问题转化对主成分t和u的双线性回归问题。Rosipal等[14-15]在其基础上进一步提出了核偏最小二乘回归法(Kernel PLS),从而使偏最小二乘回归法能用于解决非线性回归的 问题。
设样本空间X在特征空间中的映射为φ(X),令K0=φ(X)φ(X)T,并设M为预测设定的主元数,Kernel PLS的算法可表示如下[16]。
1) 对K0进行对中处理后得:
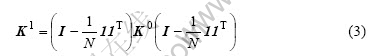
式中 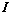 表示N×N维单位阵,而1为N维全1列向量。
表示N×N维单位阵,而1为N维全1列向量。

式中 Ktrain表示通过训练由算法步骤2建立的核矩阵,Ktest表示预测时式(5)中的核矩阵。
1.3 数据的预处理
建模过程中,为建立较稳定模型结构,需要剔除样本中的异常数据,增加模型抗干扰能力,而目前剔除异常样本的算法只适用于离线建模。常用的用于离线剔除异常样本的Chauvenet和Gubbs公式,可表示为:

为适应建立动态模型的需要,本文作者提出一种改进型在线剔除异常样本的方法,首先对式(7)中的样本平均值和样本方差分别采用下式进行确定[17]:
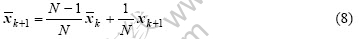
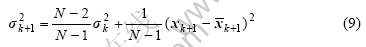
考虑到生产过程中操作情况的变化,调整参数也应该为变量,因此,论文中提出根据样本的波动对调整参数进行自适应调整,算法如下:
1) 据滑动窗内的每一变量的最大值和最小值,以及平均值和方差;并根据式(7)分别计算其对应的调整参数c1和c2。
2) 采用Chauvenet公式计算得到系数c01,同时采用Gubbs公式计算得到系数c02,通常c01>c02。
3) 取出c1和c2中的最小值,将其与c01和c02做比较,从三者中选出中间值作为调整参数c。
本论文中在采用在线式异常样本剔除方法后,对输入、输入矩阵进一步进行了自标准化处理,将原始数据转换成均值为0,标准偏差为1的新数据。
1.4 预测模型的反馈校正
模型的校正,从理论上可以分为模型结构校正和模型系数校正2种,基于滑动窗的模型修正方法属于后者。实际应用时,还需引入反馈修正项,补偿由于操作参数波动过大造成的计算偏差,其修正公式如下:

其中 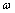 为0.7,
为0.7, 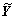 表示校正后的值,
表示校正后的值,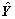 表示动态模型的计算值,
表示动态模型的计算值,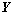 表示实际值。
表示实际值。
2 仿真研究
本论文中利用上述建模方法,针对某厂的5号(Peirce-Smith)铜转炉,利用其117炉连续生产数据进行仿真研究。
2.1 模型的输入/输出变量选择
对铜转炉造渣期的吹炼机理进行分析可知,影响造渣S2期风量和氧量的变量包括:造渣S1期和S2期的铜硫添加量(x1, x2)、造渣期熔剂添加量(x3)、造渣期多种冷料的添加量(x4, x5)、造渣S1期的渣量(x6)、造渣S1期的渣成分(x7)、造渣S1期所用的时间(x8)、造渣S1期所用的风量(x9)和造渣S1期所用的氧量(x10)。
综上分析,选择上述各变量在k、k-1、k-2炉次的值组成输入向量,对输出变量―造渣S2期所用的总风量和总氧量[y1(k),y2(k)]建立动态预估模型。
2.2 输入/输出变量间多重相关性的分析
由于模型的输入变量间,以及输入和输出变量间存在严重的多重相关性,为分析其间的相关程度,根据历史数据计算自变量和因变量间的相关系数平方值,计算结果如表1所示。
由表1可见,不仅各自变量向量与因变量向量间有较强相关性,而且各自变量向量间也有较强的相关性。例如,造渣S2期总风量与造渣S1期铜锍加入量、冷料添加量之间存在较高的相关系数,这表示加入的铜锍、冷料越多,S2期所需的总风量也越多。因此,对于这些具有较强相关性的向量,偏最小二乘法是最适合的参数辨识方法。
2.3 预测模型中主元的累计解释能力
论文选择t1、t2、t3作为偏最小二乘回归的主元。由Kernel PLS的算法可知,X的主元向量T决定了数据矩阵X和Y的回归精度,即向量T中的元素对自变量和因变量的解释性能,这可用累计解释能力表示。为研究这一关系,文中分析了第一个滑动窗内X的数据矩阵的主元t1、t2、t3、t4和数据矩阵X和Y间的关系。
首先利用偏最小二乘方法依次求出X数据矩阵的4个主成分t1、t2、t3、t4,再计算出这4个主成分t1、t2、t3、t4对自变量和因变量的累计解释能力Rd (即所有主元与各变量间相关系数平方的累积值),其结果如表2所示。由表2可见,t3对各自变量和因变量的累计解释能力均达到1.0以上,因此,对t1、t2、t3进行回归可满足计算精度。
2.4 预测结果分析
论文中针对某厂铜转炉数据进行仿真研究,利用历史报表数据,建立具有跟踪生产趋势能力的吹炼风/氧量动态预估模型,预测结果与实际值对比如图1和2所示。
由图1和2可见,经补偿修正后的预测结果与实际数据基本吻合,能准确预测关键操作量的变化趋势。但是,部分预测结果也出现较大波动,使得预测准确度下降。这是由于建模数据本身为人工操作条件下的经验数据,在使用波动较大的数据建模时,辨识得到的动态模型的回归系数的计算误差也随之增大,同时由于反馈补偿的效果,使得前次预测结果影响到本次预测结果。综上分析,当用于建模的数据出现较大波动时,预测值将出现较大波动。
表1 输入/输出变量间的相关系数
Table 1 Correlation coefficient between input variables and output variables
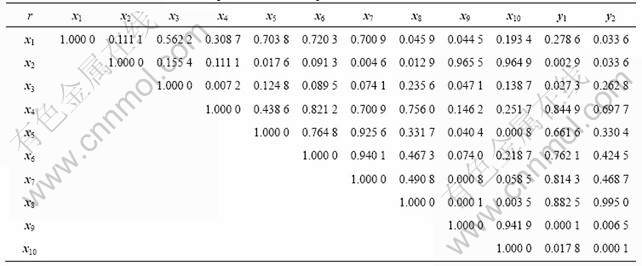
表2 累计解释能力
Table 2 Cumulative explanatory ability
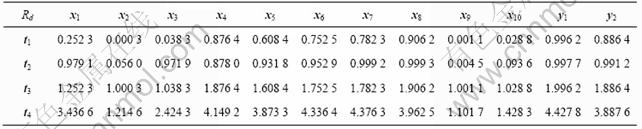
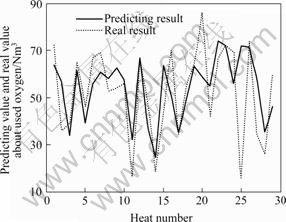
图1 修正后的氧量预测值与实际值的对比
Fig.1 Predicting results of used oxygen vs practical used oxygen
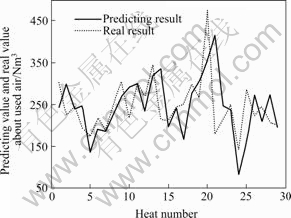
图2 修正后风量预测值与实际值的对比
Fig.2 Predicting results of used air vs practical used air
为评价预测模型的性能,本文中分别使用了最大相对误差、均方根误差(RMSE)和相对均方根误差(RRMSE)对模型的预测准确性和跟踪变化趋势的能力进行分析,其公式如下[15]:
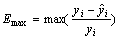 (13)
(13)
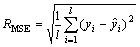 (14)
(14)
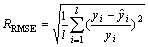 (15)
(15)
式中 yi为实际数据向量中的第i个数据,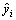 为预测所得数据向量中的第i个数据。表3中列出了采用误差反馈修正前后的相对误差的对比值。
为预测所得数据向量中的第i个数据。表3中列出了采用误差反馈修正前后的相对误差的对比值。
表3 预测结果的误差分析
Table 3 Error analysis of predicting results

由表3可见,预测结果的相对均方根误差分别为10.8%和19.1%,处于工厂操作量的允许误差范围内,因此,预测结果可作为现场生产的指导信息。
3 结论
1) 所建立的铜转炉吹炼风/氧量预估模型具有所需建模样本少、模型泛化能力强的特点,当变量之间存在高度相关性时,利用偏最小二乘回归法辨识动态模型参数具有良好的解释性,符合实际情况。
2) 提出的动态预测模型,能准确跟踪实际工况的波动特征,预测结果表明,这种建模方法具有学习能力强、泛化能力好及抗噪性强的优点,可以较好地跟踪具有较大波动幅度的过程变化趋势,在过程工业的优化和控制领域具有巨大的应用价值。
REFERENCES
[1] 唐朝晖, 桂卫华, 吴 敏, 陈晓方. 基于神经网络和灰色理论的密闭鼓风炉透气性预测模型[J]. 中国有色金属学报, 2003, 13(5): 1306-1310.
TANG Zhao-hui, GUI Wei-hua, WU Min, CHEN Xiao-fang. Predicative model based on neural network and gray theory for imperial blast furnace breathing capacity[J]. The Chinese Journal of Nonferrous Metals, 2003, 13(5): 1306-1310.
[2] HAO Xiao-jing, ZHENG Peng, XIE Zhi. A predictive modeling for blast furnace by integrating neural network with partial least squares regression[C]//IEEE International Conference on Industrial Technology. United States: Institute of Electrical and Electronics Engineers Inc, Piscataway, NJ 08855-1331, 2004: 1162-1167.
[3] 高宪文, 张傲岸, 魏庆来. 基于神经网络的钢包精炼终点预报[J]. 东北大学学报, 2005, 26(8): 726-728.
GAO Xian-wen, ZHANG Ao-an, WEI Qing-lai .Neural network based prediction of endpoint in ladle refining process[J]. Northeastern University(Natural Science), 2005, 26(8): 726-728.
[4] Roy N K, Potter W D, Landau D P. Polymer property prediction and optimization using neural networks[J]. IEEE Transactions on Neural Networks, 2006, 17(4): 1001-1014.
[5] 邓长辉, 王 姝, 王福利, 毛志忠, 王嘉铮. 真空感应炉终点碳含量预报[J]. 控制与决策, 2006, 21(2): 210-212.
DENG Chang-hui, WANG Shu, WANG Fu-li, MAO Zhi-zhong, WANG Jia-zheng. End-point carbon content prediction based on RBF neural network[J]. Control and Decision, 2006, 21(2): 210-212.
[6] 彭小奇, 胡志坤, 梅 炽, 胡 军, 姚峻峰. 炼铜转炉吹炼终点的神经网络和自适应残差补偿组合预报模型[J]. 控制理论与应用, 2002, 19(1): 149-151.
PENG Xiao-qi, HU Zhi-kun, MEI Chi, HU Jun, YAO Jun-feng. Converting furnace endpoint prediction model based on neural network and adaptive error compensation[J]. Control Theory and Applications, 2002, 19(1): 149-151.
[7] 杨金芳, 翟永杰, 王东风, 徐大平. 基于支持向量回归的时间序列预测[J]. 中国电机工程学报, 2005, 25(17): 110-114.
YANG Jin-fang, ZHAI Yong-jie, WANG Dong-feng, XU Da-ping. Time series prediction based on support vector regression[J]. Proceedings of the Chinese Society of Electrical Engineering, 2005, 25(17): 110-114.
[8] 桂卫华, 李永刚, 阳春华, 陈志盛. 基于改进聚类算法的分布式SVM及其应用[J]. 控制与决策, 2004, 19(8): 852-856.
GUI Wei-hua, LI Yong-gang, YANG Chun-hua, CHEN Zhi-sheng. Distributed SVM based on improved clustering algorithm and its application[J]. Control and Decision, 2004, 19(8): 852-856.
[9] LI Hai-sheng, ZHU Xue-feng. Application of support vector machine method in prediction of kappa number of kraft pulping process[C]//Proceedings of the World Congress on Intelligent Control and Automation (WCICA), v 4, WCICA 2004. Fifth World Congress on Intelligent Control and Automation, Conference Proceedings. United States: Institute of Electrical and Electronics Engineers Inc, Piscataway, 2004: 3325-3330.
[10] Duchesne C, MacGregor J F. Multivariate analysis and optimization of process variable trajectory for batch processes[J]. Chemometrics and Intelligent Laboratory Systems, 2000, 51(1): 125-137.
[11] Baffi G, Martin E B, Morris A J. Non-linear dynamic projection to latent structures modeling[J]. Chemometrics and Intelligent Laboratory System, 2000, 52(1): 5-22.
[12] Kim K, Lee J M, Lee I B. A novel multivariate regression approach based on kernel partial least squares with orthogonal signal correction[J]. Chemometrics and Intelligent Laboratory System, 2005, 79(1/2): 22-30.
[13] Wold S, Sjostrom M, Eriksson L. PLS-regression: A basic tool of chemometrics, Chemometrics and Intelligent Laboratory Systems, 2001, 58(2): 109-130.
[14] Rosipal R. Kernel partial least squares for nonlinear regression and discrimination[J]. Neural Network World, 2003, 13(3): 291-300.
[15] Rosipal R, Trejo L J. Kernel partial least squares regression in reproducing kernel Hilbert space[J].Machine Learning Research.2002, 2(2): 97-123.
[16] Bennett K P, Embrechts M J. An optimization perspective on kernel partial least squares[C]//Proceeding of the NATO Advanced Study Institute on Learning Theory and Practice. Amsterdam: IOS Press, 2003: 2-21.
[17] MU Sheng-jing, ZENG Ying-zhi, LIU Rui-lan. Online dual updating with recursive PLS model and its application in predicting crystal size of purified terephthalic acid(PTA) process[J]. Process Control, 2002, 16(6): 557-566.
(编辑 李向群)
基金项目:国家重点基础研究发展规划资助项目(2002cb312200);国家自然科学基金重点资助项目(60634020; 60574030; 50374079);博士点基金(20050533016)
收稿日期:2006-10-17;修订日期:2007-04-27
通讯作者:宋海鹰,博士研究生;电话:0731-8830394; E-mail: songhaiying1975@163.com

