基于Relief-F特征加权支持向量机的语义图像分类
刘杰,杜军平
(北京邮电大学 计算机学院 智能通信软件与多媒体北京市重点实验室,北京,100876)
摘要:提出一种基于Relief-F特征加权支持向量机的语义图像分类方法。首先,通过Relief-F算法计算训练数据集中图像的特征权重;然后,利用具有不同权重的特征向量来计算核函数并且训练支持向量机;最后,用经过训练的支持向量机对测试数据集中的图像进行自动分类。实验结果表明,基于Relief-F特征加权支持向量机的语义图像分类方法在分类准确率和训练时间耗费上均优于传统的支持向量机方法。
关键词:Relief-F算法;特征加权;支持向量机;语义图像分类
中图分类号:TP311 文献标志码:A 文章编号:1672-7207(2011)S1-0750-05
Semantic image classification of a Relief-F feature weighting based SVM method for performance
LIU Jie, DU Jun-ping
(Beijing Key Laboratory of Intelligent Telecommunication Software and Multimedia,
School of Computer Science, Beijing University of Posts and Telecommunications, Beijing 100876, China)
Abstract: A Relief-F feature weighting based support vector machine (SVM) method for semantic image classification was proposed. Firstly, the feature weight of images in training data set was computed by the Relief-F algorithm; Then, the SVM classifier was trained by taking advantage of the feature vector with different weights; Finally, the automatic classification of images in the test data set was presented by using trained SVM classifier. Experimental results show that the Relief-F feature weighting based SVM classifier is better than the traditional SVM classifier both in classification accuracy and training time-consuming in semantic image classification.
Key words: Relief-F algorithm; weighted feature; support vector machine (SVM); semantic image classification
目前,随着基于内容的图像检索技术的迅速发 展[1],用户对图像搜索、浏览工具的要求越来越高。基于内容的图像检索可分为3层。第1层是基于颜色、纹理、形状等反映图像基本物理特征的检索,是最直接和最基本的层面,需采用到图像信息处理、图像分析和相似性匹配技术[2]。第2层是基于图像对象语义的检索,如图像中实体及实体之间空间关系的检索。对象级检索技术建立在第1层的特征基础上,并引入了对象模型库、对象识别和人工智能等图像理解技术[3]。第3层是基于图像概念级语义的检索,其技术建立在对象层语义特征提取的基础上,引入了对象和场景之间的逻辑、情感等高层语义的描述及识别,需要用到语义库和更加有效的人工智能和机器学习技术[4]。
语义鸿沟问题是目前基于内容的图像检索研究中的难点[5]。许多研究人员对减小语义鸿沟提出了许多值得借鉴的观点[6]。例如,监督式的机器学习方法是减小语义鸿沟的有力工具[7-8]。监督学习的目标是根据输入数据集预测输出数据集,其中支持向量机和贝叶斯分类器[9]经常被用于从低图像特征中学习高层语义。
支持向量机被广泛用来减小基于内容的图像检索中的语义鸿沟,已被用于对象识别、文本分类等领域,被认为是图像检索系统中的一个很好的学习工具[10]。为了加强图像分类的准确性,文献[11]集成了2类支持向量机用于分类,即基于多实例学习的支持向量机和基于全局特征的支持向量机。文献[12]提出了一个多模态模糊框架。该框架将从被测文本和低层视觉特征中提取的信息运用到了双支持向量机分类器中。前述的SVM算法都没有对图像语义特征的重要性进行区分,其采取的方法是给提取的低层特征赋予相同的权重。目前,已经有一些研究人员在进行基于内容的图像分类研究中用到了图像语义特征加权的方法,但是分类效果还有待提高。
本文作者提出了一种基于Relief-F特征加权支持向量机的语义图像分类方法,使用Relief-F算法计算图像特征权重。权重越大的特征向量越能够作为该分类集的支配向量,权重越小的特征向量对分类结果的影响越小。因此,可以根据Relief-F算法的计算结果为图像特征向量指定相匹配的权重向量。
1 Relief-F算法
基本的Relief算法是Kira和Rendell在1992年提出的[13],局限于解决两类的分类问题。1994年Kononenko[14]扩展了Relief算法,使得Relief-F可以解决多类问题。Relief-F算法给特征集中每一特征赋予一定的权重。设X={x1,x2,…,xn}是待进行分类分析的对象的全体,其中:xi=[xi1,xi2,…,xiN]T表示第i个样本的N个特征值,λ是N×1的矩阵,表示各维特征的权值。对于任意的一个样本xi,首先找出R个与xi同类的最近邻的样本hj,j=1,2,…,R。在每一个与xi不同类的子集中找出R个最近邻的样本mij,j=1,2,…,R,l≠class(xi),设diff_hit是N×1的矩阵,表示hj与xi在特征上的差异。
 (1)
(1)
设diff_miss是N×1的矩阵,表示mij与xi在特征上的差异。

 (2)
(2)
式中:P(l)为第l类出现的概率,可以用第l类的样本数比上数据集中样本的总数。
Relief-F算法中λ由下式更新:
 (3)
(3)
如此重复若干次,就可以得到特征集中每一个特征的权重。
2 支持向量机
SVM用一个非线性映射把数据映射到一个高维特征空间,在高维特征空间中进行线性分类,求解时把原始问题转化为一个凸二次优化问题,其基本思想是通过选择训练集中的一组特征子集(支持向量),使得对该子集的划分等价于对整个数据集的划分,在保证分类精度的同时降低了运算的复杂度。与一些传统的分类算法相比,SVM在过拟合、运算速度和分类精度等方面都有着明显的优越性[15]。考虑线性可分的分类问题,设训练集T为:

对该训练集建立一个没有分类误差的分类超平面。训练集如果是线性不可分的,建立起来的分类超平面就会有分类误差,但是可以找到一个最优超平面,使它对整个训练集平均的分类误差的几率达到最小。因此,可放宽上面的约束条件,通过引入一个松弛变量ξ≥0来实现。原始的优化问题变为:

 (4)
(4)
式中:C≥0是一个惩罚参数。C越大表示对错误的惩罚越重。用Lagrange乘子法将上式化为对偶形式:

 (5)
(5)
求解上述对偶问题得到的最优分类函数:
 (6)
(6)
式中: 。这里的样本点(xj・yj)所对应的Lagrange乘子αj满足0<αj<C。
。这里的样本点(xj・yj)所对应的Lagrange乘子αj满足0<αj<C。
3 基于Relief-F特征加权支持向量机的语义图像分类方法
3.1 特征提取方法
特征提取的目标是让图像能够被语义合理的表达,并且在图像检索与识别中可对语义进行计算。因此,在提取图像属性形成语义的过程中,把图像属性的n个特征量表示为x1,x2,…,xn;同一图像的属性作为一个整体来考虑。将它们表示为X=(x1,x2,…,xn)T。该矢量称之为图像语义的特征矢量,是对图像的一种数字化描述,用它的值来代替原图像,即为原图像的特征值。
当实际用于图像语义抽取的特征数目d给定后,直接从已获得的n个原始特征中选出d个特征x1,x2,…,xd,使可分性判据J的值满足:
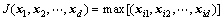 (7)
(7)
式中:xi1,xi2,…,xid是n个原始特征中的任意d个特征,即直接寻找n维特征空间中的d维子空间。为了更方便地在n个原始特征构成的特征矢量X=(x1,x2,…,xn)T中选择d个特征,可以使用一个特征提取矩阵或变换矩阵来实现,Y=(x1,x2,…,xd)T=WXT(W为特征选取矩阵或权重矩阵[16])。使用文献[16]的方法抽取图像特征向量作为计算的原始数据。
3.2 分类器的构造
将图像的抽取图像特征向量作为原始空间的输入向量。由于图像的内容的非确定性和多样性,即使提取的特征良好,也不能保证图像线性可分,即图像是非线性可分的[18]。因此,需要选取非线性特征加权支持向量机来进行分类器的构造。
对于非线性可分的分类问题要引入核函数,把特征权向量和核函数结合起来得到特征加权核函数,然后再应用到非线性支持向量机中,并称为非线性特征加权支持向量机[19]。
定义:设K是定义在X×X上的核函数, ,P是给定输入空间的d阶线性变换矩阵,其中d是输入空间的维数。特征加权核函数Kp定义为:
,P是给定输入空间的d阶线性变换矩阵,其中d是输入空间的维数。特征加权核函数Kp定义为:
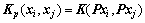 (8)
(8)
线性变换矩阵P也叫做特征加权矩阵,由此得到下列常用的特征加权核函数。
特征加权多项式核函数:

 (9)
(9)
特征加权Gaussian核函数:

 (10)
(10)
特征加权Sigmoid核函数:
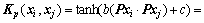
 (11)
(11)
为了得到较佳的实验效果,选择在进行非线性特征分类中表现优异的特征加权高斯径向基核函数作为分类器的核函数。在依据Relief-F算法确定特征权重后,就可构造基于Relief-F特征加权支持向量机,步骤如下:
(1) 收集原始样本数据集T:

(2) 根据Relief-F算法分别计算每个特征的权值,并构造特征权向量:

(3) 选择适当的惩罚参数C>0,构造并求解最优化问题:

(12)
其中,
得最优解α=(α1,…,αl)T。
(4) 计算 ,选择α的一个分量0<αj<C所对应的样本点(xj・yj),并据此计算:
,选择α的一个分量0<αj<C所对应的样本点(xj・yj),并据此计算: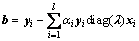 。
。
构造最优分划超平面(w・x)+b=0,由此求得决策函数f(x)=sgn((w・x)+b)。
4 实验和结果分析
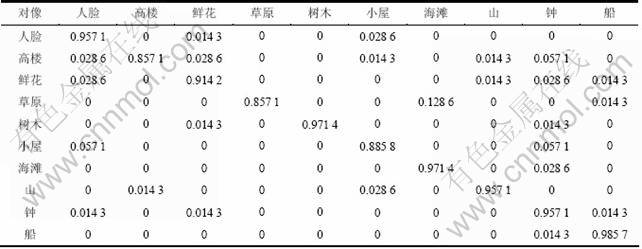
为了验证本文作者所提出的方法的有效性,从IAPR TC-12 Benchmark[20]中选择10大分类,近2 000张图片,进行分类实验。这10大分类分别是:人脸、海滩、鲜花、山、树木、小屋、高楼、草原、船、钟。使用1 300张图片进行训练,700张图片进行测试。使用分类准确度作为评判标准。分类准确度是指一张图片被分类器判定为其所属类别的几率。表1和表2分别表示基于经典SVM和本文提出的基于Relief-F特征加权SVM的分类结果。实验结果中每一行表示对于测试图片被判定到不同类别的几率,对角线上的数据表示分类准确率。为了更直观地进行比较,选取高楼类图片的分类结果数据对传统SVM方法和本文提出的分类方法的实验效果进行对比,结果如图1所示。图1中,C5表示正确的分类集(高楼),其余均为其他类别的分类集。从图1可以看出,对于测试集数据,使用传统SVM方法的分类错误率均高于使用本文提出方法的分类错误率。本文提出的基于Relief-F特征加权SVM的分类方法的分类正确率优于传统SVM方法的分类正确率。
表1 基于传统SVM的分类结果
Table 1 Classification result based on traditional SVM

表2 基于Relief-F特征加权SVM的分类结果
Table 2 Classification result based on Relief-F feature weighting SVM
本文提出的方法不仅在分类准确度方面优于传统的SVM分类器,在训练时间上也好于传统的SVM分类器。在相同的服务器上,传统的SVM的训练平均时间为3 s,而本文提出的方法的训练时间平均为1 s,仅为传统方法耗时的1/3,显示出其在学习时间上的优势。
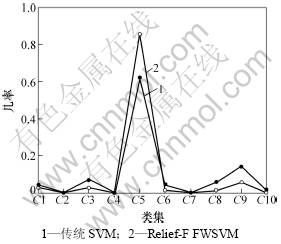
图1 传统SVM方法与基于Relief-F特征加权SVM方法的效果比较
Fig.1 Comparison of classification results by traditional SVM and Relief-F feature weighting SVM
5 结论
本文提出了基于Relief-F特征加权支持向量机的语义图像分类方法,详细论述了分类器的构造方法,并利用该分类器对多个类别的图片集进行了分类。实验结果表明:本文提出的图像分类方法在分类准确率上优于传统的SVM分类器。本文提出的图像分类方法具有计算快速、简单、高效的特点。
参考文献:
[1] 章毓晋. 基于内容的视觉信息检索[M]. 北京: 科学出版社, 2003: 3-5.
ZHANG Yu-jin. Content-based visual information retrieval[M]. Beijing: Science Press, 2003: 3-5.
[2] XIE Hua, Omega A. Feature representation and compression for content-based retrieval[C]//Proceedings of SPIE. The International Society for Optical Engineering. 2001: 111-122.
[3] 陈光鹏, 杨育彬. 利用蚁群算法的记忆式图像检索方法[J]. 计算机科学与探索, 2011, 5(1): 32-37.
CHEN Guang-peng, YANG Yu-bin. Memory-type image retrieval method based on ant colony algorithm[J]. Journal of Frontiers of Computer Science and Technology, 2011, 5(1): 32-37.
[4] Kavitha K, Arivazhagan S. A novel feature derivation technique for SVM based hyper spectral image classification[J]. International Journal of Computer Applications, 2010, 15(1): 25-31.
[5] Hare J S, Lewis P H, Enser P G B, et al. Mind the gap: Another look at the problem of the semantic gap in image retrieval[C]// Proceedings of SPIE―The International Society for Optical Engineering, 2006, 6073(1): 0-9.
[6] Liu Y, Zhang D, Lu G, et al. A survey of content-based image retrieval with high-level semantics[J]. Pattern Recognition, 2007, 40(1): 262-282.
[7] Carneiro G, Chan A B, Moreno P J, et al. Supervised learning of semantic classes for image annotation and retrieval[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(3): 394-410.
[8] Feng H, Chua T S. A boostrapping approach to annotating large image collection[C]//Proceedings of the 5th ACM SIGMM International Workshop on Multimedia Information Retrieval. Berkeley: ACM, 2003: 55-62.
[9] Jin W, Shi R, Chua T S. A semi-naive bayesian method incorporating clustering with pair-wise constraints for auto image annotation[C]//Proceedings of the 12th Annual ACM International Conference on Multimedia. New York: ACM, 2004: 336-339.
[10] 高永岗, 周明全, 耿国华, 等. 基于特征选择和SVMs的图像分类[J]. 计算机工程与应用, 2010, 46(5): 169-172.
GAO Yong-gang, ZHOU Ming-quan, GENG Guo-hua, et al. Image classification based on feature selection and SVMs[J]. Computer Engineering and Applications, 2010, 46(5): 169-172.
[11] QI Xiao-jun, HAN Yu-tao. Incorporating multiple SVMs for automatic image annotation[J]. Journal of Pattern Recognition, 2007, 40(2): 728-741.
[12] ZHU Qiang, YEH Mei-chen, CHENG Kwang-ting. Multimodal fusion using learned text concepts for image categorization[C]//Proceedings of the 14th Annual ACM International Conference on Multimedia. Santa Barbara: ACM, 2006: 211-220.
[13] Kira K, Rendell L. A practical approach to feature selection[C]//Proceedings of the 9th International Workshop on Machine Leaning. San Francisco: Morgan Kaufmann, 1992: 249-256.
[14] Kononenko I. Estimating at tributes: Analysis and extensions of RELIEF[J]. Lecture Notes in Computer Science, 1994, 784: 171-182.
[15] 田英杰, 邓乃扬. 数据挖掘中的新方法―支持向量机[M]. 北京: 科学出版社, 2004: 33-36.
TIAN Ying-jie, DENG Nai-yang. A new data mining method: Support vector machines[M]. Beijing: Science Press, 2003: 33-36.
[16] 石跃祥, 朱东辉, 蔡自兴, 等. 图像语义特征的抽取方法及其应用[J]. 计算机工程, 2007, 33(19): 177-179.
SHI Yue-xiang, ZHU Dong-hui, CAI Zi-xing, et al. Extraction of image semantic attributes and its application[J]. Computer Engineering, 2007, 33(19): 177-179.
[17] Wang L, Khan L. Automatic image annotation and retrieval using weighted feature selection[J]. Journal of Multimedia Tools and Applications, 2006, 29(1): 55-71.
[18] Gunn S R. SVM for classification and regression[R]. Southampton: School of Electronics and Computer Science, University of Southampton, 1998.
[19] 汪廷华, 田盛丰, 黄厚宽, 等. 样本属性重要度的支持向量机方法[J]. 北京交通大学学报, 2007, 31(5): 87-90.
WANG Ting-hua, TIAN Sheng-feng, HUANG Hou-kuan, et al. Support vector machine based on weightiness of sample attribute[J]. Journal of Beijing Jiaotong University, 2007, 31(5): 87-90.
[20] Escalante H J, Hernández C A, Gonzalez J A, et al. The segmented and annotated IAPR TC-12 benchmark[J]. Computer Vision and Image Understanding, 2010, 114(4): 419-428.
(编辑 杨华)
收稿日期:2011-04-15;修回日期:2011-06-15
基金项目:国家自然科学基金资助项目(91024001,61070142);北京市自然科学基金资助项目(4111002)
通信作者:杜军平(1963-),女,河北保定人,教授,博士生导师,从事智能信息处理研究;电话:13501233431;E-mail:junpingdu@126.com

