基于改进混合粒子群算法的服务动态选择方法
舒振,陈洪辉,罗雪山
(国防科技大学 信息系统工程重点实验室,湖南 长沙,410073)
摘要:针对服务组合过程中的服务动态选择问题,建立带约束的Web服务组合QoS全局优化问题的描述模型,分析当前已有各种算法的缺陷和不足,提出一种改进混合粒子群算法的求解方法,并从可行性、有效性以及运行效率3个方面进行仿真实验。研究结果表明:改进的混合粒子群算法综合利用了群体自身信息、局部较优信息、全局较优信息以及遗传算法的交叉、变异、选择等操作对粒子进行更新,增强了粒子群的搜索空间和搜索效率,可以较好地解决服务组合中服务的动态选择问题。
关键词:Web服务;粒子群算法;遗传算法;服务动态选择;服务质量(Qos)
中图分类号:TP39 文献标志码:A 文章编号:1672-7207(2011)10-3086-09
A Web service dynamic selection method based on improved hybrid particle swarm optimization algorithm
SHU Zhen, CHEN Hong-hui, LUO Xue-shan
(Science and Technology on Information Systems Engineering Laboratory,
National University of Defense Technology, Changsha 410073, China)
Abstract: Aiming at the Web service dynamic selection problem during Web service composition, a model of the whole QoS (quality of service) optimize problem of Web service composition with restriction was established, the current research of mathematical solving algorithms for solving the model were analyzed, and an improved hybrid particle swarm optimization algorithm was put forward to solve the model. Finally, comprehensive experiments based on simulation case was set up. The results show that in the improved hybrid particle swarm optimization algorithm, the new particle is refreshed by particle information self, optimal solutions of population and individual, the cross, mutation and selection operators of genetic algorithm. The algorithm is feasibile, valid and efficient and it is proved that the algorithm can resolve the whole QoS optimize problem of web service composition efficiently.
Key words: Web service; particle swarm optimization algorithm; genetic algorithm; service dynamic selection; quality of service (QoS)
目前,随着互联网服务应用的快速发展,Web服务已逐步从企业级服务集成过渡到面向互联网环境的服务体系结构之上[1],通过服务组合技术构建功能强大的应用系统已成为工业界与学术界的热点研究内容,近些年,研究工作者提出了多种服务组合方法[2-4]。从服务实例调用方式上来看,服务组合方法可以分为静态组合、半自动组合和自动组合3种模式[5],其中:静态组合因需事先确定所需调用的服务实例而难以适应快速变化的网络环境和应用需求;自动组合大多需结合智能规划的知识及算法,运算复杂难度大;半自动组合模式是先建立抽象的服务组合模型,然后,在运行过程中依据具体的需求信息动态地发现和绑定所需调用的服务实例,具有灵活性与运算简单的特点,因此,成为目前服务组合技术的主要方法。采用半自动服务组合模式时,用户应首先依据自身的业务需求构建相应的业务逻辑模型。而功能相同的业务需求可能会同时存在多个满足要求但质量(Quality of Service,QoS)不同Web服务,如何有效地选择“最佳”的应用服务,是评判服务组合技术质量的关键问题。为解决这一难题,需重点研究2方面问题:(1) 依据服务节点的功能需求,从种类众多、功能各异的Web服务中发现合适的Web服务候选集;(2) 在Web服务候选集基础上,结合Web服务性能指标和逻辑模型执行流程,选择一组运行效果最佳的服务实例。国内外有众多学者研究了第1个问题,并从语义服务的角度出发提出了一系列服务搜索算法[6-11],取得了良好效果。本文重点研究第2个问题,即如何在Web服务候选集中依据实际需求快速选择一组整体效果最优的服务实例,实现Web服务的动态选择。目前,国内外关于服务动态选择的研究多是基于QoS局部最优的选择方法[12-14],注重为各个服务节点选择相应的服务,而不考虑各服务节点之间的逻辑关系,因此,难以解决服务组合中的QoS全局优化问题。而针对服务组合QoS全局优化的研究相对有限,比较有代表性的工作见文献[15-17],其主要思想是通过把各服务节点的QoS参数约束线性加权转化为单目标函数,再利用线性规划方法来解决服务选择的QoS全局优化问题;文献[18]基于模拟退火算法提出了一种求解性价比最高的QoS全局最优化问题;文献[19-20]用遗传算法等非线性优化的仿生算法求解QoS全局最优化问题。但这些算法都存在一些不足:一是大多数方法都只能求得问题的局部最优解,而无法有效获取全局最优解,二是算法自身的操作困难,运行时间长,尤其是在候选服务个数迅速增加的情况下,很难保证算法时间的收敛性,无法适应实时系统的需要。粒子群算法(Particle swarm optimization,PSO)已被证明为全局最优化方法,且操作较遗传算法简单,具有可并行搜索、可求解不可微分方程和无需方程梯度信息等优点,已成为继遗传算法、退火模拟算法之后优化领域研究的新方向。本文作者在传统粒子群算法基础上,结合遗传算法的交叉、变异、选择等操作,提出一种基于改进混合粒子群算法的Web服务动态选择方法,在确保提供一组满足系统质量约束的最优非劣解条件上,能减小候选服务迅速增加的影响,提高算法的计算效率。实验证明该方法优于传统的线性规划算法和遗传算法,具有良好的时间收敛性,能有效解决Web服务组合的QoS全局优化问题。
1 问题描述
为了便于分析,现将本文所需解决的问题描述如下。
定义1 Web服务(WS)通常可以用以下四元组来表示:WS=(D,I,O,Q)。其中:D表示服务的基本信息,包括服务名称、服务标识、服务提供者等相关内容;I表示服务所有输入参数的集合;O表示服务所有输出参数的集合;Q为服务的非功能属性,Q=(q1,q2,…,qm);q1,q2,…,qm分别对应于服务的各个具体QoS指标,如服务的响应时间、费用、可靠性、可用性和可访问性等;m表示指标的数量。
定义2 业务逻辑模型(Business logic model,BLM)是系统业务执行逻辑的抽象描述,可以通过一组相关的业务活动及活动间的制约关系来表示。各业务活动在执行时都通过相应的Web服务来实现,模型中1个业务活动节点对应1个服务节点,但服务节点并不直接对应于某个服务实例,而是代表了满足活动需求的一组服务,该组服务中的任意1个都能满足业务活动的功能需求。由满足特定活动需求的服务实例所构成的集合就是相应服务节点的候选服务集。图1所示是采用IDEF3建模方法描述的1个业务逻辑模型,其中各业务活动节点用行为单元表示,各活动节点间的关联关系通过交汇点和联接来单独或组合表示。
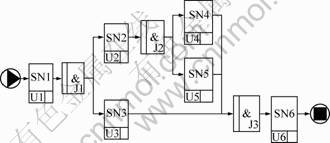
图1 采用IDEF3方法描述的业务逻辑模型示例
Fig.1 Example of business logic model using IDEF3
基于上述分析,可以用1个五元组形式化描述业务逻辑模型:BLM=(BD,SN,SR,CanS,A)。其中:BD表示业务逻辑模型的基本信息,包括模型的标识、模型的名称以及模型的创建者等相关内容;SN表示模型中各服务节点的集合,即:SN={sni|1≤i≤n}(n为模型中服务节点的数量);SR表示模型中有关联关系的服务节点对以及相应的关联关系的集合,即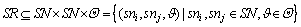 (Θ表示所有关联关系的集合)。工作流管理联盟(WfMC)规定了4种基本的关联关系[15],即顺序、选择、并行以及循环,通过采用这些关联关系可以实现不同服务节点间的有效连接; CanS表示业务逻辑模型中所有候选服务集构成的集合;A表示服务节点与候选服务集之间的映射关系,即:A:SN→CanS,通过该映射关系可以使模型用户由服务节点快速定位至所需的候选服务集。
(Θ表示所有关联关系的集合)。工作流管理联盟(WfMC)规定了4种基本的关联关系[15],即顺序、选择、并行以及循环,通过采用这些关联关系可以实现不同服务节点间的有效连接; CanS表示业务逻辑模型中所有候选服务集构成的集合;A表示服务节点与候选服务集之间的映射关系,即:A:SN→CanS,通过该映射关系可以使模型用户由服务节点快速定位至所需的候选服务集。
Web服务组合的QoS全局优化需从业务逻辑模型的整体要求出发,为各服务节点选择合适的服务实例,使其在执行过程中整体效能达到最优。
Web服务组合的QoS全局优化问题的数学描述如下。假设:
(1) SN={sni|1≤i≤n}表示业务逻辑模型中服务节点的集合,n表示服务节点的数量;
(2) CanS={Cansi|1≤i≤n}表示业务逻辑模型中候选服务集的集合;
(3) 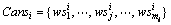 表示候选服务集Cansi所包含服务实例的集合,其中
表示候选服务集Cansi所包含服务实例的集合,其中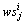 表示具体的服务实例,mi表示该候选服务集所包含的服务实例个数;
表示具体的服务实例,mi表示该候选服务集所包含的服务实例个数;
(4) 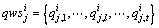 表示服务实例的QoS指标,其中
表示服务实例的QoS指标,其中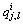 表示服务实例的第l个QoS指标,t表示服务实例QoS指标的数量;
表示服务实例的第l个QoS指标,t表示服务实例QoS指标的数量;
(5) Q(ql),1≤l≤t表示业务逻辑模型中第l个QoS指标的约束值;
(6) Fi:SN→Cansi表示服务节点与服务实例之间的映射关系,即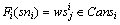 ;
;
(7) 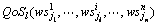 ,1≤l≤t表示在业务逻辑模型中选取服务实例
,1≤l≤t表示在业务逻辑模型中选取服务实例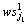 至
至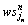 后第l个QoS指标的聚合值。
后第l个QoS指标的聚合值。
带约束的Web服务组合QoS全局优化问题就是要求出一组最优的服务实例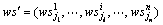 ,使得目标函数为:
,使得目标函数为:
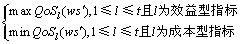 (1)
(1)
约束条件:
 (2)
(2)
 表示所选用服务实例的第l个QoS指标的聚合值应满足相应约束条件的要求。
表示所选用服务实例的第l个QoS指标的聚合值应满足相应约束条件的要求。
文献[21]证明了上述问题是一个NP-Complete问题,虽然在服务节点数目不多且候选服务集规模不大的情况下,该问题可以通过穷举法来求解,但随着业务逻辑模型中服务节点数目的不断增加以及候选服务集规模的不断扩大,可选的执行路径也会迅速增长,计算的复杂性同时增加,时间和空间开销也会加大,无法用确定性的算法进行求解。而且由于各优化目标之间的不可公度性和相互冲突性,某目标状态的改善往往会引起其他目标性能下降(如执行时间短的服务执行费用较高,执行费用低的服务执行时间较长),一般不存在所有目标函数共同的极小点(执行时间与费用同时极小),因此,上述问题优化的结果应该是一个最优解的集合,集合中的元素称为Pareto优化解或非劣最优解。其中,Pareto优化解就是指不存在优于其中一个目标而其他目标非劣的更好的解。
在通常情况下,对于Pareto优化解集的各元素而言,无法综合比较所有目标。但由于各QoS需求侧重点各不相同,因此,通过给不同的目标函数赋予不同权重并加权求和,即将多目标函数转换为单目标函数可以找出用户最满意解。但无论用户偏重于哪些服务质量指标,其最满意解一定是在Pareto优化解集合中。在求解上述问题时,也通过对各目标函数进行加权求和,将其由多目标优化问题转换为单目标优化问题。
2 基本粒子群算法
1995年,Kennedy和Eberhart提出了粒子群优化算法[22-23],由于其容易理解、易于实现和收敛速度快等特征,已经在函数优化、神经网络训练、数据挖掘等多个领域得到了成功应用,并且在很多情况下PSO比遗传算法更有效。因此,PSO算法能有效解决工程领域的多目标优化问题。
PSO算法是通过记忆与反馈机制实现高效的寻优搜索。PSO算法在寻求一致认知过程中,个体除了记住它们自己的经验外,同时考虑其他同伴的经验,向自己的经验学习,又向同伴学习。在PSO中,每个优化问题的潜在解都可以看作D维搜索空间上的1个点,称为“粒子”(Particle)。粒子在搜索空间中以一定速度飞行,这个速度根据其自身和同伴的飞行经验来动态调整。所有的粒子都有一个被目标函数决定的适应值(Fitness value),并且知道自己到目前为止发现的最好位置(particle best,记作pbest)和当前位置,这个可以看作是粒子自己的飞行经验。除此之外,每个粒子还知道目前为止整个群体中所有粒子发现的最好位置(global best,记作gbest)是所有pbest的最好值,这个可以看作是粒子同伴的飞行经验。每个粒子使用下列信息更新自己的当前位置:(1) 当前位置;(2) 当前速度;(3) 当前位置与自己最好位置之间的距离;(4) 当前位置与群体最好位置之间的距离。优化搜索正是在这样一群随机初始化形成的粒子组成的种群中迭代进行。而每个粒子在D维空间中速度和位置可以采用下述公式来进行计算:
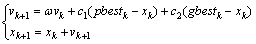 (3)
(3)
其中:vk为速度;xk为位置;pbestk为粒子本身找到最优解的位置;gbestk为群体找到最优解的位置;ω为惯性系数,一般取(0,1)之间的随机数;c1和c2为群体认知系数,一般取(0,2)之间的随机数。每一维的速度都被限制在最大速度vmax (vmax>0)内,当vk>vmax时,vk=vmax;当vk<-vmax时,vk=-vmax。
3 改进的混合粒子群算法
在基本粒子群算法中,若某粒子发现一个当前最优位置恰好为局部最优点,其他粒子就会迅速向其靠拢,从而粒子无法再搜索新的全局极值gbest,容易出现早熟收敛情况,陷入局部最优。就上述Web服务组合的QoS全局优化问题而言,其变量取值都为离散变量,并且难以描述基本粒子群算法中的速度信息。为了克服这些不足,本文借鉴遗传算法思想提出了一种改进的混合粒子群算法。其主要思想是:利用粒子群中局部最优信息和全局最优信息更新每一代粒子,通过对粒子群的不断迭代更新获取最优解。它与基本粒子群算法的不同在于:(1) 两者在算法初始化时生成初始种群的方法不一样;(2) 每一轮迭代中更新粒子群的具体操作不尽相同。改进的混合粒子群算法可以分为数据预处理、产生初始粒子群和粒子群更新3步,其中数据预处理就是对不同量纲、不同类型的QoS数据进行预处理,将其转化到统一的数据范围,以平衡各QoS指标对目标函数的贡献;产生初始粒子群就是依据实际需要,为改进的混合粒子群算法产生初始的可行种群;粒子群更新就是在每次迭代时产生新的粒子变量,并保证粒子群适应值不断优化。
3.1 数据预处理
由于服务的QoS指标往往具有度量单位不相同、取值范围不一致以及评价标准相对抗(即有的指标取值越大越好,而有的取值越小越好)等特征,为了更有效地对各服务的QoS性能指标进行综合评价,必须先对服务的QoS指标进行规范化处理,包括针对效益型指标和成本型指标的规范化处理[24]。
(1) 效益型指标:
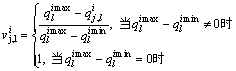 (4)
(4)
(2) 成本型指标:
 (5)
(5)
其中:为服务实例的第l个QoS指标,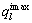 和
和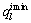 分别为服务实例集
分别为服务实例集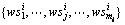 中第l个QoS指标的最大值和最小值。
中第l个QoS指标的最大值和最小值。
经过上述处理,候选服务集cansi中各服务实例QoS指标的描述如下:
 (6)
(6)
在数据预处理时,需根据用户的偏好将式(1)的多目标优化转化为单目标优化。由于式(1)目标函数中的max函数可以通过转化为min函数,同时根据用户的QoS偏好为每个目标函数设置不同的权重,再通过加权求和可将上述多目标优化方案转换为如下目标 函数:
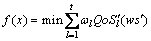 (7)
(7)
该函数同时也可以作为改进混合粒子群算法的适应值函数。
3.2 产生初始粒子群
由于QoS全局优化问题的解对应于具体的服务实例,而基本粒子群算法无法直接处理这些变量,本文采用了与遗传算法类似的基因形式对服务实例变量进行编码,方法如下:对于给定的解(即一组服务实例),用一个n维向量进行描述,每一维向量的取值范围是[1,mi]的整数。其具体含义是指某业务逻辑模型中每个服务节点的候选服务集包含mi个服务实例,并使用[1,mi]的整数对候选服务集中的服务实例进行编号,若某向量q=(x1,x2,…,xi,…,xn),则表示业务逻辑模型的第i个服务节点选用编号为xi的服务实例。其中:1≤xi≤mi;xi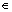 Z;n为服务节点的个数。改进混合粒子群算法中每个粒子的位置采用此向量来 表示。
Z;n为服务节点的个数。改进混合粒子群算法中每个粒子的位置采用此向量来 表示。
为了防止算法过早收敛,在产生初始粒子时,应使初始粒子群在解空间中尽可能分散,而不是集中于某一个较小区域,以扩展可行解的搜索范围。因此,本算法首先利用随机法产生一组满足约束条件的从初始服务节点(StartPoint)到终止服务节点(EndPoint)的可行解集,然后,对可行解集各解之间的相关性进行判定,再将相关性小于一定阀值的可行解纳入初始粒子群中。假设初始粒子群的规模为N,P为初始粒子群的集合。算法描述如下。
算法1:产生初始粒子群(GetIniSwarm)。
输入:种群规模N,约束函数Q(ql)
输出:初始粒子群P
Begin
①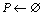
② while (|P|<N)
③ wsi=Constr(Ran(Startpoint, Endpoint))
④ if SimVal(P,wsi)<0.3 then
⑤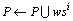
⑥ Goto ②
⑦ OutPut P
End
算法2:判断可行解的相关性(SimVal)
输入:初始粒子群的集合P,所需判断的可行解wsi
输出:相关性判断结果si
Begin
① si=0
② for each wsjP do
③ hi,j←-P×lnP
④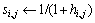
⑤ if si,j>si then
⑥ si=si,j
⑦ Output si
End
其中Constr(A)表示从集合A中选取满足约束函数Q(ql)要求的可行元素,即选取满足业务逻辑模型整体质量要求的一组服务实例;Ran(Startpoint,Endpoint)表示利用随机法从初始服务节点(StartPoint)到终止服务节点(EndPoint)选取一组服务实例;SimVal(P,wsi)表示所选取的可行解与初始粒子群中已有元素的相关性,只有相关性小于阀值(0.3)的可行解才能加入初始粒子群的集合,从而保证了初始可行解的分散性。相关性的判定方法如算法2所示。
算法2使用了信息熵来判定各可行解之间的相关性。首先在步骤(3)中计算可行解的信息熵hi,j,其中P为可行解wsi与可行解wsj对应的编码位所表示相同的服务实例的比率;步骤(4)中计算可行解wsi与可行解wsj的相似程度si,j,其中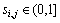 ;最后返回si,j的最大值为相似性判定结果。
;最后返回si,j的最大值为相似性判定结果。
3.3 粒子群更新
粒子群的更新方法是本算法的核心内容,针对服务组合QoS全局优化问题解的具体特点,我们在算法中引入了遗传算法的交叉、变异、选择等操作对粒子群进行更新。每一次迭代既考虑了粒子群自身的信息、局部较优信息和全局较优信息,又综合了遗传算法的交叉、变异、选择等操作,以实施粒子群的更新。这样既避免了粒子更新过程中参数选择的问题,简化了运算过程,同时也保持了算法的全局搜索能力。
以第t代的第j个粒子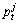 为例说明粒子的更新操作,设
为例说明粒子的更新操作,设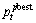 表示第t代对应于第j个粒子的局部较优值,
表示第t代对应于第j个粒子的局部较优值,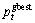 表示第t代的全局较优值。具体步骤如下:
表示第t代的全局较优值。具体步骤如下:
(1) 与进行交叉操作产生新的粒子T1与T2。该操作表示新粒子以不同的速度和方向向全局较优值靠近,并保证该值距离全局较优值不“太远”。交叉过程如下。
由粒子群编码方式可知,与都是编码长度为n的向量,首先随机生成一个编码长度为n的0~1向量,并以该向量作为变异操作的中间算子。交叉原则是以中间算子作为判断和对应位置的值是否交换的依据,若中间算子某位置值为“1”,则和对应位置的值进行交换;若中间算子某位置值为“0”,则和对应位置的值不交换;经过此轮交叉,便可得到新的粒子T1与T2。然后,判断新粒子T1与T2是否满足约束条件Q(q1)的要求(即判断是否为可行解),若满足则交叉过程结束,若不满足则需继续进行交叉。其方法是比较T1(T2)与中哪些位置的编码不一致,然后随机从这些位置中选取1位,并用在该位置的值替换T1(T2)中相应位置的值,再判断更新后的T1(T2)是否满足约束条件的要求,确定是否要继续进行交叉。可以证明该交叉过程在有限步骤内一定能够结束,因为本身满足约束条件的要求,在最坏情况下,与经过若干步交叉后,最终可以获得与完全一致的T1(T2),此时,交叉过程可以终止。但通常不会出现这种情况,即只需1~2次交叉便可以得到满足约束条件的新粒子。
以一个5维向量粒子为例说明。假设随机生成的中间算子为(0,1,0,1,1),图2所示为该交叉过程。其中:T1的产生经历了1次交叉,T2的产生则经历了2次交叉。

图2 粒子与全局较优值的交叉示意图
Fig.2 Sample of mutation between particle swarm and optimal solutions of population
(2) 与进行交叉操作产生新粒子T3与T4。该操作表示新粒子以不同的速度和方向向局部较优值靠近,并保证该值距局部较优值也不会“太远”。交叉方法与(1)的相同。
(3) 自身进行变异操作产生新粒子T5与T6。此操作是为了避免粒子过早陷入局部最优解。该操作首先在解空间中随机产生1个可行解,并按粒子的编码方式得到新的粒子向量,然后,将该粒子与进行交叉操作产生新粒子T5与T6,交叉方法也与(1)的相同。
(4) 按照式(7)分别计算新粒子T1,T2,T3,T4,T5和T6的适应值f 1,f 2,f 3,f 4,f5和f6,从中选取最小值fmin,将fmin与全局较优值和局部较优值进行比较,若fmin<f局部较优值,则更新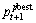 使
使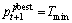 ;若fmin<f全局较优值,则更新
;若fmin<f全局较优值,则更新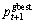 使
使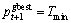 。
。
(5) 按照算法2分别计算新粒子T1,T2,T3,T4,T5,T6与的相关度,选取相关性最大的Tmax作为下一轮迭代的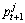 ,即
,即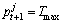 ,从而尽量保证解的分散性,防止解过早向全局较优解或局部较优解“靠近”。实验证明:采用此方法所得替代值优于直接选用Tmin作为的替代值。
,从而尽量保证解的分散性,防止解过早向全局较优解或局部较优解“靠近”。实验证明:采用此方法所得替代值优于直接选用Tmin作为的替代值。
经过上述5步即完成了一轮粒子群的更新操作,得出新的,和。以此为依据,经过多轮迭代即可不断在解空间中进行并行全局搜索,逐步获得具有更高目标适应值的新粒子,并最终得到一组具有最优目标值或近似最优目标值的服务实例集。
4 仿真实验
以下通过仿真实验分析验证算法的可行性与效率。构建一个模拟的实验环境,网络环境为100M局域网,运行算法的客户端配置了PentimuIV 2.6GHz处理器和1G内存,算法采用C++编码实现。服务器端选用ExUDDI[24]原型系统作为服务注册中心和服务代理,实施对各个服务实例以及QoS信息的注册与管理。采用服务代理实现算法程序与UDDI注册中心的通信,服务代理依据算法程序给出的服务实例编号,自动在UDDI注册中心查找相关服务的QoS信息,并将结果返回算法程序,以实现算法程序的进一步分析。
4.1 实验方案说明
实验选取了服务响应时间(Time)、费用(Cost)、可靠性(Rel)和可用性(Ava)共4个QoS指标,并采用了图1所示的业务逻辑模型。模型中共有6个服务节点,分别为每个服务节点模拟产生10,8,20,15,20和10个候选服务实例,并在各QoS指标的取值范围内用随机法生成相应的指标数据。其中,QoS指标取值范围设定为0<Time≤10 s,0<Cost≤100元,0.2<Rel≤1和0.1<Ava≤1。
同时,针对约束方程与目标函数构建的具体需要,服务组合的QoS指标设定了如下要求,Time≤25 s,Cost≤300元,Rel≥0.7,Ava≥0.6。该问题的目标函数与约束方程的构建过程如下:
首先根据业务逻辑模型的实际执行路径,分别得出了各QoS指标聚合值的计算方法:
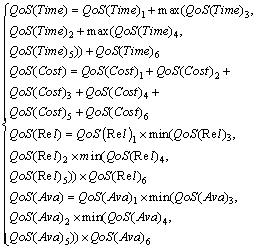
其中:QoS(q)i表示在业务逻辑模型中第i个服务节点对应于QoS指标q的取值。
根据改进混合粒子群算法的要求,首先对多目标函数和各服务实例的QoS指标进行预处理。将可靠性和可用性等效益型指标的评价函数QoS(Rel)和QoS(Ava)整体取负转换为QoS′(Rel)和QoS′(Ava),使其满足越小越优。然后,依据用户需求为目标函数设定相应权重(在实际实验时,将ωt,ωc,ωr和ωa统一设为0.25,该值也可以根据需要进行调整),由此得出以下目标函数与约束条件。
目标函数:
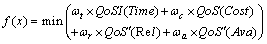
约束条件:
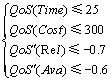
需要说明的是,参与目标函数计算的是各服务实例经过预处理之后的QoS指标值,而参与约束条件计算的是各服务实例在预处理之前的QoS指标值。
为了进一步分析和验证改进粒子群算法解决上述问题的可行性与有效性,设计了以下3组实验。
4.2 实验形式与结果分析
4.2.1 可行性实验
目的是检验改进的混合粒子群算法找到上述QoS全局优化问题最优解的可行性。实验思路是将该算法所得出的结果与穷举法所得结果进行对比,根据二者的近似程度分析本算法的可行性。为了避免随机误差,实验针对不同粒子群规模和迭代次数共运算40次,然后以统计概率作为实验结果。
图3所示为本算法在寻找最优解方面的可行性,其中横坐标代表了本算法不同的种群规模,纵坐标是找到最优解的统计概率。由图3可见:在迭代次数为300代的条件下,找到最优解的概率都在90%以上,因此,采用本算法解决带约束的Web服务组合QoS全局优化问题是可行的。
4.2.2 有效性实验
目的是通过分析算法运行中CPU开销来验证本算法的有效性。实验分别考虑了不同粒子群规模、不同迭代次数条件下的算法执行时间。针对每种情况算法都分别运行20次,取其平均值作为实验结果。
图4所示为本算法找到最优解的CPU开销,其中横坐标代表了本算法不同的迭代次数,纵坐标是所花费的CPU时间。由图4可见:随着迭代次数的不断增加,不同种群规模的CPU运行时间并没有大幅增加。本实验在种群规模为30个的情况下,算法迭代400代得到最优解仅耗时15 s,此运算效率可以满足大部分服务组合问题需求,能有效解决本问题。
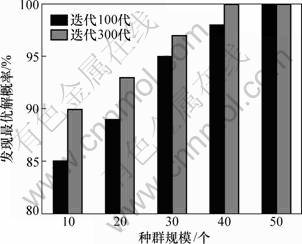
图3 算法的可行性实验结果
Fig.3 Result of feasibility experiment
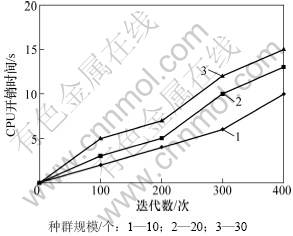
图4 算法有效性实验结果
Fig.4 Result of effectiveness experiment
4.2.3 运行效率实验
本试验的目的是通过比较本算法与传统的线性规划算法以及遗传算法在解决上述问题时的执行效率,以分析各算法的优劣。图5中比较了本算法、线性规划法以及遗传算法在解决本问题时的运行效率。图中的横坐标代表业务逻辑模型中各服务节点所包含的候选服务实例的规模,纵坐标为算法的执行时间。其中,各算法的终止条件是发现当通过不同算法计算得到的最优解的目标值与由穷举法获得的最优解的目标值的相对误差在2%的范围内,并且对于遗传算法与本文所提出的算法所使用的种群规模都是20。由图5可知:本算法的时间收敛性要明显比其他算法的优。
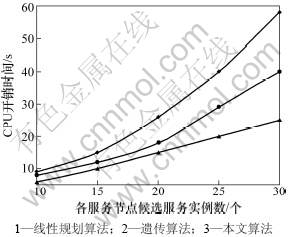
图5 算法的运行效率实验结果
Fig.5 Result of operational efficiency experiment
通过以上3个实验分析可知:本算法对于解决带约束的Web服务组合QoS全局优化问题是可行的、有效的。实际上,通过理论分析可知,本算法所具备的如下特点可以有效提高算法的运行效率:
(1) 对本问题的解都采用向量编码的形式来表示,并保证了每次迭代所产生的粒子都是可行解,这有效避免了传统连续变量的取整问题,减少了搜索可行解的时间,大大提高了算法的运行效率。
(2) 通过采用遗传算法的交叉、变异、选择等操作,既为粒子群更新提供了一种可行方法,又大大提高了可行解的收敛速度,进一步提高了算法的搜索效率,能满足服务组合问题的实际需要。
(3) 无需设置基本粒子群算法中各种参数(惯性系数以及社会认知系数等),也无需设定速度以及位置的范围,而只需设置种群规模与迭代次数,大大简化了算法的实施步骤,减少了干扰,有助于提升算法的运行速度。
此外,本算法还重点考虑了如何有效扩展可行解的分散性,以防止过早陷入局部最优解,从而提高了发现全局最优解的可能性。
5 结论
(1) 构建了带约束的Web服务组合QoS全局优化问题的描述模型,提出了一种改进的混合粒子群算法来求解该问题。该算法既使用了粒子群自身的信息、局部较优信息和全局较优信息,又进行了交叉、变异、选择等操作,增强了粒子群算法解决上述问题的适 应性。
(2) 本文提出的算法可以有效解决Web服务组合QoS全局优化问题,有助于Web服务组合中服务的动态选择。
(3) 应进一步分析各约束条件以及目标函数对于粒子群更新的影响,并以此为依据改进中间算子的选取方法以及粒子群的更新策略,从而进一步提高算法的运行效率。
参考文献:
[1] 胡春华, 吴敏, 刘国平. Web服务工作流中基于信任关系的QoS调度[J]. 计算机学报, 2009, 32(1): 42-53.
HU Chun-hua, WU Min, LIU Guo-ping. QoS scheduling based on trust relationship in Web service workflow[J]. Chinese Journal of Computers, 2009, 32(1): 42-53.
[2] Narayanan S, Mcllraith A. Simulation, verification and automated composition of Web services[C]//Proceedings of the 11th International World Wide Web Conference (WWW2002). Honolulu, USA, 2002: 77-88.
[3] Hamadi R, Benatallah B. A Petri net-based model for Web service composition[C]//Proceedings of the 14th Australasian Database Conference. Adelaide, Australian: Australian Computer Society, 2003: 191-200.
[4] Zhang R, Arpinar B, Aleman-Meza B. Automatic composition of semantic Web services[C]//Proceedings of International Conference on Web Services. Las Vegas, USA: CSREA Press, 2003: 38-41.
[5] Majithia S, Walker D W, Gray W A. A framework for automated service composition in service-oriented architectures[C]//Proceedings of the First European Web Symposium, ESWS’04. Heraklion, Berlin: Springer, 2004: 269-283.
[6] Paolucci M, Kawamura T, Payne T R, et al. Semantic matching of Web services capabilities[C]//Proceedings of the First International Semantic Web Conference. Sardinia, Italy: Springer, 2002: 333-347.
[7] LI Lei, Ian H. A software framework for matchmaking based on semantic Web technology[C]//Proceedings of the 12th International World Wide Web Conference. Budapest, Hungary: ACM, 2003: 331-339.
[8] Rajasekaran P, Miller J, Verma K, et al. Enhancing Web services description and discovery to facilitate composition[C]//First International Workshop on Semantic Web Services and Web Process Composition. San Diego, USA: Springer, 2004: 55-68.
[9] 胡建强, 邹鹏, 王怀民, 等. Web服务描述语言QWSDL和服务匹配模型研究[J]. 计算机学报, 2005, 28(4): 505-513.
HU Jian-qiang, ZOU Peng, WANG Huai-min, et al. Research on Web service description language QWSDL and service matching model[J]. Chinese Journal of Computers, 2005, 28(4): 505-513.
[10] 马应龙, 金蓓弘, 冯玉琳. 基于进化分布式本体的语义Web服务动态发现[J]. 计算机学报, 2005, 28(4): 603-614.
MA Ying-long, JIN Bei-hong, FENG Yu-lin. Dynamic discovery for semantic Web service based on evolving distributed ontologies[J]. Chinese Journal of Computers, 2005, 28(4): 603-614.
[11] 吴健, 吴朝晖, 李莹, 等. 基于本体论和词汇语义相似度的Web服务发现[J]. 计算机学报, 2005, 28(4): 595-692.
WU Jian, WU Zhao-hui, LI Ying, et al. Web service discovery based on ontology and similarity of words[J]. Chinese Journal of Computers, 2005, 28(4): 595-692.
[12] Casati F, Ilnicki S, JIN Li-jie, et al. eFlow: a Platform for developing and managing composite e-services[R]. HP Laboratories Palo Alto, 2000: 10-20.
[13] Benatallah B, Sheng Q Z, Ngu A H H, et al. Declarative composition and peer-to-peer provisioning of dynamic Web services[C]//Proceedings of the 18th International Conference on Data Engineering. San Jose, California: IEEE Computer Society, 2002: 297-308.
[14] Schuster H, Georgakopoulos D, Cichocki A, et al. Modeling and composing service-based and reference process-based multi-enterprise processes[C]//Proceedings of the 12th Conference on Advanced Information Systems Engineering. Stockholm, Sweden: Springer, 2000: 247-263.
[15] Zeng Liang-zhao, Boualem Benatallah, Marlon Dumas, et al. Quality driven Web services composition[C]//Proceedings of the Twelfth International World Wide Web Conference. Budapest, Hungary: ACM, 2003: 411-421.
[16] 赵俊峰, 谢兵, 张路, 等. 一种支持领域特性的Web服务组装方法, 计算机学报, 2005, 28(4): 731-738.
ZHAO Jun-feng, XIE Bing, ZHANG Lu, et al. A Web service compositon method supporting domain feature[J]. Chinese Journal of Computers, 2005, 28(4): 731-738.
[17] Ardagna D, Pernici B. Global and local QoS constraints guarantee in Web service seleciton[C]//Proceedings of the IEEE International Conference on Web Services. Orlando, USA: IEEE Computer Society, 2005: 805-806.
[18] CHEN Han-hua, JIN Hai, NING Xiao-ming, et al. Q-SAC: Toward QoS optimized service automatic compositon[C]//Proceeding of the 5th IEEE/ACM International Symposium on Cluster Computer and the Grid. Cardiff: IEEE Computer Society, 2005: 623-630.
[19] 王勇, 胡春明, 杜宗霞. 服务质量感知的网格工作流调度[J]. 软件学报, 2006, 17(11): 2341-2351.
WANG Yong, HU Chun-ming, DU Zong-xia. QoS-awared grid workflow schedule[J]. Journal of Software, 2006, 17(11): 2341-2351.
[20] 刘书雷, 刘云翔, 张帆, 等. 一种服务聚合中QoS全局最优服务动态选择算法[J]. 软件学报. 2007, 18(3): 646-656.
LIU Shu-lei, LIU Yun-xiang, ZHANG Fan, et al. A dynamic Web services selection algorithm with qos global optimal in Web service composition[J]. Journal of Software, 2007, 18(3): 646-656.
[21] Garey M R, Johnson D S. Computers and intractability: A guide to the theory of NP-completeness[M]. New York: W H Freeman and Company, 1979: 38-45.
[22] Eberhart R, Kennedy J. A new optimizer using particle swarm theory[C]//Proceedings of the Sixth International Symposium on Micro Machine and Human Science Piscataway. IEEE Service Center, 1995: 39-43.
[23] Kennedy J, Eberhart R. Particle swarm optimization[C]//IEEE International Conference on Neural Networks. Perth, Australia: IEEE Computer Society, 1995: 1942-1948.
[24] 郭得科, 任彦, 陈洪辉, 等. 一种QoS有保障的Web服务分布式发现模型[J]. 软件学报, 2006, 17(11): 2324-2334.
GUO De-ke, REN Yan, CHEN Hong-hui, et al. A QoS-guaranteed and distributed model for Web service discover[J]. Journal of Software, 2006, 17(11): 2324-2334.
(编辑 陈灿华)
收稿日期:2010-10-25;修回日期:2011-01-28
基金项目:国防预研重点基金资助项目(9140A06020407KG0127);国家自然科学基金资助项目(70601036)
通信作者:舒振(1977-),男,江西上饶人,博士研究生,讲师,从事指控系统总体技术、服务计算等研究;电话:0731-84576603;E-mail:sz_1226@sina.com

