Artificial neural network-based merging score for Meta search engine
��Դ�ڿ������ϴ�ѧѧ��(Ӣ�İ�)2016���10��
�������ߣ�P. Vijaya G. Raju Santosh Kumar Ray
����ҳ�룺2604 - 2615
Key words��metasearch engine; neural network; retrieval of documents; ranking list
Abstract: Several users use metasearch engines directly or indirectly to access and gather data from more than one data sources. The effectiveness of a metasearch engine is majorly determined by the quality of the results and it returns and in response to user queries. The rank aggregation methods which have been proposed until now exploits very limited set of parameters such as total number of used resources and the rankings they achieved from each individual resource. In this work, we use the neural network to merge the score computation module effectively. Initially, we give a query to different search engines and the top n list from each search engine is chosen for further processing our technique. We then merge the top n list based on unique links and we do some parameter calculations such as title based calculation, snippet based calculation, content based calculation, domain calculation, position calculation and co-occurrence calculation. We give the solutions of the calculations with user given ranking of links to the neural network to train the system. The system then rank and merge the links we obtain from different search engines for the query we give. Experimentation results reports a retrieval effectiveness of about 80%, precision of about 79% for user queries and about 72% for benchmark queries. The proposed technique also includes a response time of about 76 ms for 50 links and 144 ms for 100 links.
J. Cent. South Univ. (2016) 23: 2604-2615
DOI: 10.1007/s11771-016-3322-7
P. Vijaya1, G. Raju2, Santosh Kumar Ray3
1. Karpagam University Coimbatore, TamilNadu, India;
2. Faculty of Engineering and Technology Associate Professor, Department of Information Technology Kannur University, Kannur, Kerala-670 567, India;
3. Department of Information Technology, Al Khawarizmi International College, Al Alin, UAE
 Central South University Press and Springer-Verlag Berlin Heidelberg 2016
Central South University Press and Springer-Verlag Berlin Heidelberg 2016
Abstract: Several users use metasearch engines directly or indirectly to access and gather data from more than one data sources. The effectiveness of a metasearch engine is majorly determined by the quality of the results and it returns and in response to user queries. The rank aggregation methods which have been proposed until now exploits very limited set of parameters such as total number of used resources and the rankings they achieved from each individual resource. In this work, we use the neural network to merge the score computation module effectively. Initially, we give a query to different search engines and the top n list from each search engine is chosen for further processing our technique. We then merge the top n list based on unique links and we do some parameter calculations such as title based calculation, snippet based calculation, content based calculation, domain calculation, position calculation and co-occurrence calculation. We give the solutions of the calculations with user given ranking of links to the neural network to train the system. The system then rank and merge the links we obtain from different search engines for the query we give. Experimentation results reports a retrieval effectiveness of about 80%, precision of about 79% for user queries and about 72% for benchmark queries. The proposed technique also includes a response time of about 76 ms for 50 links and 144 ms for 100 links.
Key words: metasearch engine; neural network; retrieval of documents; ranking list
1 Introduction
The dearth of any specific structure and wide range of data published on the web makes it highly challenging for the user to find the data without any external assistance. It is a general credence [1-2] that a single general purpose search engine for all web data is improbable because its processing power cannot scale up to the fast increasing and unlimited amount of web data. A tool that swiftly gains approval among users is Meta search engines [3]. The Meta search engines can run user query across multiple component search engines concurrently, retrieve the generated outcomes and amass them. The benefits of Meta search engines against the search engines are notable [4]. The Meta search engine enhances the search coverage of the web providing higher recall. The overlap among the primary search engines is generally small [5] and it can be small as 3% of the total results retrieved. The Meta search engine solves the scalability issue of searching the web and facilitates the use of multiple search engines enabling consistency checking [6]. The Meta search engine enhances the retrieval effectiveness providing higher precision because of ��chorus effect�� [7].
The issue of rank aggregation is historic and has been studied for a century starting from a requirement to design fair elections. It can be thought as the unconfirmed analog to regression with the target of discovering a pooled ranking which minimizes the distance to each individual ranking. In spite of seeming effortlessness, it is surprisingly complex; finding the optimal pooled ranking is NP-hard [7] under certain conditions. Thus, several modern efforts portray approximation algorithms for the rank aggregation setback [8-10], after showing its association to the feedback arc set issue on tournaments [8]. Some of these are widely applied to many diverse research domains which are bioinformatics [11], Web spam detection [7], pattern ordering [12], metasearching [13-17] and many more. Web Meta searching in disparity to rank aggregation is an issue representing its own unique challenges. The outcomes that a Meta search system gathers from its component engines are not similar to votes or any other single dimensional entities: apart from the individual ranking, it is assigned by a component engine, a web outcome also incorporates a title, a small fragment of text which represents its significance to the submitted query [18-28] (textual snippet) and a uniform resource locator (URL). Ostensibly, the traditional rank aggregation techniques are insufficient for providing a robust ranking mechanism appropriate for Meta search engines, because they ignore the semantics accompanying each Web result.
In this work, we propose an artificial neural network based merging score for Meta search engine. Here, initially we give a query to the search engines for our process and take the top n list links from each search engines and combine all the n links from the search engines based on the unique links, i.e. we consider only the unique links. For each link, it would have a topic, snippet and the contents. Using this we calculate the title based calculation, snippet based calculation and content based calculation by comparing the words in the query and the synonyms of the respective words. Also, we calculate the domain calculation, position calculation and co-occurrence calculation for each links. We then give the calculated values and user ranked links for the same query to the neural network to train the neural network. After training the neural network, our system will rank and merge the links obtained from different search engines for the query we give.
2 Related works: a brief review
AKRITIDIS et al [29] presented a QuadRank technique which considered the additional information regarding the query terms, collected results and data correlation. They implemented and tested the QuadRank in real world Meta search engine. They comprehensively tested QuadRank for both effectiveness and efficiency in the real world search environment and also used the task from the TREC-2009 conference. They demonstrated that in most cases their technique outperformed all component engines.
ISHII et al [30] proposed a technique to reduce the computation and communication loads for the page rank algorithm. They developed a method to systematically aggregate the web page into groups by using the sparsity inherent in the web. For each group, they computed an aggregated page rank value that can be distributed among the group members. They provided a distributed update scheme for the aggregated Page Rank along with an analysis on its convergence properties. They provided a numerical example to illustrate the level of reduction in computation while keeping the error in rankings small.
KEYHANIPOUR et al [31] introduced a Meta search engine named WebFusion. WebFusion learns the expertness of the underlying search engines in a certain category based on the users�� preferences. It also exploits the ����click-through data concept���� to give a content- oriented ranking score to each result page. Click-through data concept is the implicit feedback of the users�� preferences, which is also used as a reinforcement signal in the learning process, to predict the users�� preferences and reduces the seeking time in the returned results list. They fused the decision lists of underlying search engines using ordered weighted averaging technique. They compared their result with some popular Meta search engines such as ProFusion and MetaCrawler. They demonstrated a significant improvement on average click rate and the variance of clicks as well as average relevancy criterion.
AMIN and EMROUZNEJAD [32] proposed a linear programming mathematical model for optimizing the ranked list result of a given group of Web search engines for an issued query. Their method first ranked the documents resulted for a specific query from each search engine and they used linear programming to combine the rank and find the optimal rank for each document in the search engines results. Their proposed model identified the score of each document retrieved from a search engine using an optimization model without a subjective procedure. An application with a numerical illustration showed the advantages of their proposed method.
LI et al [33] addressed the Web search problem on aggregating search results of related queries to improve the retrieval quality. They specifically proposed a generic rank aggregation framework which consists of three steps. First they built a win/loss graph of Web pages according to a competition rule, and then they applied the random walk mechanism on the win/loss graph. Last they sorted those Web pages by their ranks using a PageRank-like rank mechanism. Their proposed framework considered not only the number of wins that an item won in competitions, but also the quality of its competitor items in calculating the ranking of Web page items. Their experimental outcomes showed that their search system can clearly improve the retrieval quality in a parallel manner over the traditional search strategy that serially returns result lists.
FANG et al [34] considered the rank aggregation problem for information retrieval over Web making use of a kind of metric, the coherence, which consider both the normalized Kendall-�� distance and the size of overlap amid two partial rankings. They focused on the complexity and algorithmic issues for the top d CAP. Their major technical contribution is a polynomial time approximation scheme (PTAS) for top d CAP under some reasonable restriction.
A technique to aggregate rank lists in web search using ontology based user preference was proposed by LI et al [35]. They introduced a set of techniques to combine the respective rank lists produced by diverse attributes of user preference. They used the learned ontology to store the attributes such as the topics that a user is interested in and the degrees of user interests in those topics. The major motto of their work is to form a broadly acceptable rank list among those attributes using rank based aggregation. Their experimental outcome showed that their technique is effective in improving the quality of the web search in terms of user satisfaction.
3 Proposed artificial neural network based merging score for Meta search engine
This section explains our proposed technique of artificial neural network based merging score for Meta search engine. Figure 1 shows the process of our proposed technique.
Initially we give a query to different search engines and remove the stop words from the query to separate the words from the query. We choose n top list from each search engine to further process our technique. We then combine all the n top lists from the different search engines by considering the unique links alone. After separating the query words we apply each word to the word net to find the synonyms for each word and take the synonyms as separate words of query to process our technique. For each link we obtained from the different search engines, it would have title, snippet and contents. Using the information of each unique link, we do title based calculation, snippet based calculation and content based calculation. We also do domain calculation, position calculation and co-occurrence calculation based on the unique links obtained from different search engines. We then give the solutions of those calculations to the neural network along with the user given ranking of the links to train the neural network. The trained neural network would then rank the unique links obtained from different search engines. The calculations for the proposed technique are as follows.
3.1 Pre-processing query
To do title based calculation, snippet based calculation and content based calculation, we have to pre-process the query given to the different search engines. Initially, we remove the stop words from the query and give the remaining words to the word net to find the synonyms of those words. The query words and the synonyms of the respective query words together with the unique items from top n list of different search engines are used to calculate the title based calculation, snippet based calculation and content based calculation.
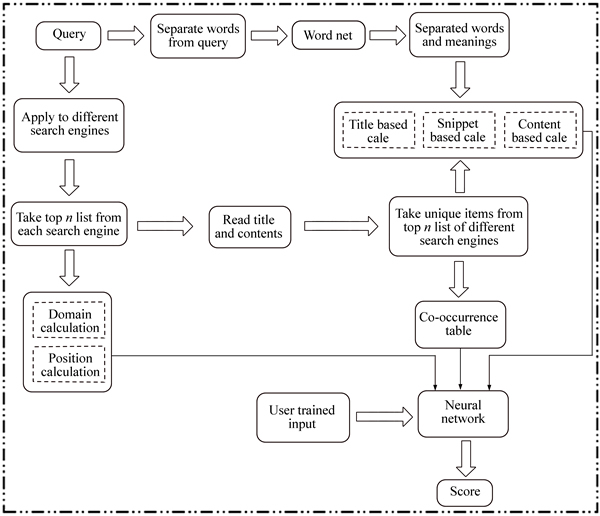
Fig. 1 Process of proposed technique
3.2 Title based calculation
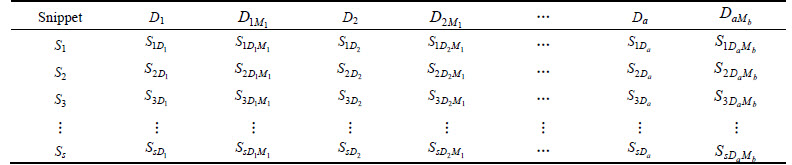
For each document (link) there would have a title and the calculation we do here is based on the title. The calculation based on title of the unique links is calculated as follows: after separating the query words and finding the meanings for each query word, we compare it with the titles of the unique links separately to find the frequency of the words as shown in Table 1.
Table 1 is explained as follows. The D1, D2, ��, Da represents the separated words of the query we give and a represents the number of separated words in the query and D1M1 represents the first meaning M of the respective word D1 and DaMb represents the bth meaning M of ath separated word D of the query we give. The T1D1 represents the number of times the first separated word present in the title of the first unique link. The T1D1M1 represents the number of times the first meaning of the first separated word present in the title of the first unique link. The title based calculation for each unique link is shown by:
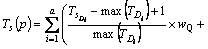
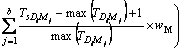
In the above equation, Ts(p) is the title based value of s th unique link; 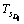 is the number of occurrence of the ith query word in the title T of sth link; max
is the number of occurrence of the ith query word in the title T of sth link; max is the maximum number of occurrence of the ith query word in the title of whole unique links;
is the maximum number of occurrence of the ith query word in the title of whole unique links; 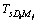 is the number of occurrence of the jth meaning of the ith query word in the title T of sth link; max
is the number of occurrence of the jth meaning of the ith query word in the title T of sth link; max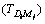 is the maximum number of occurrence of the jth meaning of the ith query word in the title of whole unique links; a is the total number of query word; b is the total number of meaning of the ith query word; wQ is the weight value of the query word and wM is the weight value of the meaning word of the query word.
is the maximum number of occurrence of the jth meaning of the ith query word in the title of whole unique links; a is the total number of query word; b is the total number of meaning of the ith query word; wQ is the weight value of the query word and wM is the weight value of the meaning word of the query word.
3.3 Snippet based calculation
The snippet is a small piece of information about the main information in the link. The snippet would be visible under each link we obtained from the search engine as a small note. The calculation based on snippet of the unique link is as follows: we check the query word and the meanings of the query word with the snippet of each link to calculate the number of occurrence in the snippet. Table 2 shows the number of occurrence of query word and meanings of query words in the snippet of each link.
Table 2 is explained as follows. S1, S2, ��, Ss represent the snippets of the unique links we obtained and 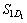 represents the number of occurrence of the first query word in the snippet of the first unique link and
represents the number of occurrence of the first query word in the snippet of the first unique link and 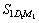 represents the number of occurrence of first meaning of first query word in the snippet of the first unique link. The snippet based calculation for each unique link is shown by an equation below:
represents the number of occurrence of first meaning of first query word in the snippet of the first unique link. The snippet based calculation for each unique link is shown by an equation below:
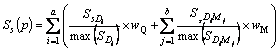
In the above equation, Ss(p) is the calculated snippet based value of the sth unique link;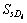 is the number of occurrence of the ith query word D in the snippet S of the sth unique link; max
is the number of occurrence of the ith query word D in the snippet S of the sth unique link; max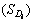 is the maximum number occurrence of the ith query word D in the snippet S of whole unique links we obtained;
is the maximum number occurrence of the ith query word D in the snippet S of whole unique links we obtained; 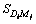 is the jth meaning of ith query word D in the snippet S of the sth unique link; max
is the jth meaning of ith query word D in the snippet S of the sth unique link; max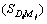 is the maximum number of occurrence of the jth meaning of the ith query word D in the snippet S of the whole unique links; wQ is the weight value of the query word; wM is the weight value of the meaning of the query word.
is the maximum number of occurrence of the jth meaning of the ith query word D in the snippet S of the whole unique links; wQ is the weight value of the query word; wM is the weight value of the meaning of the query word.
Table 1 Frequency of query words and meanings of query words in the title
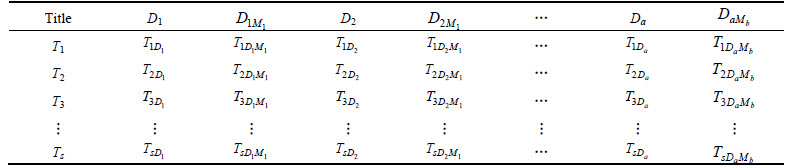
Table 2 Number of occurrence of query word and meanings of query words in snippet of each link
3.4 Content based calculation
In content based calculation, we compare the contents of each link with the separated query words and their synonyms to check the number of occurrence of separated query words and their synonyms in the contents of each link. Table 3 shows the number of occurrence of query words and their synonyms in the contents of each link.
Table 3 is explained as follows. C1, C2, ��, Cs represents the contents of the unique links and 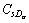 represents the number of occurrence of ath query word in the content of sth unique link and
represents the number of occurrence of ath query word in the content of sth unique link and  represents the number of occurrence of bth synonym of ath query word in the content of sth unique link. The calculation based on content is shown by
represents the number of occurrence of bth synonym of ath query word in the content of sth unique link. The calculation based on content is shown by
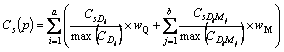
In the above equation, Cs(p) is the calculated content based value of sth unique link; 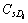 is the number of occurrence of ith query word D in the content of the sth unique link; max
is the number of occurrence of ith query word D in the content of the sth unique link; max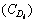 is the maximum number of occurrence of the ith query word D in the content of the sth unique link;
is the maximum number of occurrence of the ith query word D in the content of the sth unique link; 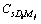 is the number of occurrence of the jth synonym of ith query word D in the content of the sth unique link; max
is the number of occurrence of the jth synonym of ith query word D in the content of the sth unique link; max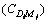 is the maximum number of occurrence of the jth synonym of the ith query word D in the content of the sth unique link.
is the maximum number of occurrence of the jth synonym of the ith query word D in the content of the sth unique link.
3.5 Domain calculation
Each link from the different search engines would come under a specific domain name. An example for domain name is ��Wikipedia��. We calculate the domain value for each unique link using the domain name for each links in the different search engine. The equation to calculate the domain value [29] for each unique link is given below:
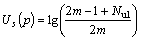
In the above equation, Us(p) is the calculated domain value of sth unique link; m is the number of search engines that we used; Nul is the number of unique links with the same domain name. For example, we have ten unique links, and five unique links are from the same domain, while checking any one of the link from those five unique links which are under the same domain; Nul value is five for unique link that we check.
3.6 Position calculation
This calculation is based on the ranking of the link in different search engines, namely, the link is present in which position in each search engine for the process. The formula to calculate the position of a link is shown below:
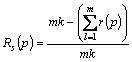
In the above equation, Rs(p) is the position value of the link; m is the number of search engines used; k is number of links that we taken for our process from each search engine; r(p) is the rank of a link in a particular search engine.
3.7 Co-occurrence calculation
The co-occurrence of each link is calculated by comparing each link with another and by calculating the ratio of number of similar contents in both comparing links to the total number of unique contents in both the comparing links. We will not compare the same links with each other. Table 4 shows the co-occurrence values after comparing each links with another.
In Table 4, 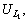
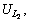 ��,
��, 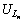 are the unique links obtained; V represents the respective values that we obtained using the equation given below:
are the unique links obtained; V represents the respective values that we obtained using the equation given below:
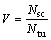
where Nsc is the number of similar contents in comparing links and Ntu is the total number of unique contents in both links.
Table 3 Frequency of query words and their synonyms in contents of each link

Table 4 Co-occurrence values

In the above equation if 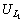 and
and 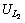 are compared, the number of similar contents are the contents which are in also in
are compared, the number of similar contents are the contents which are in also in 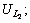 and the total number of unique contents are the remaining contents in both and
and the total number of unique contents are the remaining contents in both and 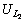 as well as the similar contents by considering one. After calculating the co-occurrence values, we calculate the total co-occurrence for each unique link using the following equation:
as well as the similar contents by considering one. After calculating the co-occurrence values, we calculate the total co-occurrence for each unique link using the following equation:
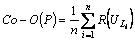
The above equation is explained as follows: n is the total number of unique links that we obtained; 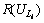 is the row wise values of the co-occurrence, i.e. the total co-occurrence value of respective unique links.
is the row wise values of the co-occurrence, i.e. the total co-occurrence value of respective unique links.
3.8 Training neural network
After doing title based calculation, snippet based calculation, content based calculation, domain calculation, position calculation and co-occurrence calculation, the values with the user given ranking of the links are given to the neural network to train the neural network. The user given ranks for the links are the discernment of different users. It is based on giving a query to different search engines taken for the process and taking top n links from each search engine. The top n links from different search engines are then merged and ranked by the users based on their discernment. It is then given to the neural network along with the values that we obtained based on the aforementioned calculations to train the neural network. Figure 2 shows a neural network of our process.
In Fig. 2, Wij is the weight values between the input layer and the hidden layer; Wjk represents the weight values between the hidden layer and the output layer; O represents the output of the neural network. The neural network would be trained based on the weight values and the weight values are adjusted based on the error. The error is calculated by checking the difference between the target value and the output obtained using neural network. The target value is based on the user ranked list and the weight values are based on back propagation algorithm. It is explained as follows: initially the weights in the neural network are random numbers and the output from the neural network for the given input is based on the weight values. Figure 3 shows a sample connection in neural network for learning back propagation algorithm.
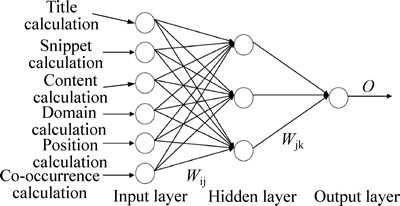
Fig. 2 Neural network of process
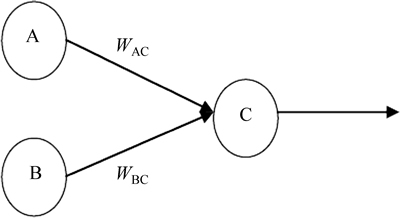
Fig. 3 Sample connection in neural network
In Fig. 3, the output of node (neuron) C is formed from the neurons A and B. Considering that C is the output layer, and A and B are hidden layers. First, we calculate the error in the output from C as
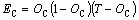
In the above equation, EC is the error from the node C; OC is the output from the node C; T is the target based on the user ranked list. Using EC the weight values are changed as shown below:
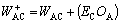

In the above equations 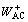 and
and 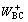 are new trained weight and WAC and WBC are the initial weights. Thereafter, we have to calculate the errors for the hidden layer neurons. Unlike output layer, we can not calculate it directly. So, we back propagate it from the output layer. It is shown by the equations below:
are new trained weight and WAC and WBC are the initial weights. Thereafter, we have to calculate the errors for the hidden layer neurons. Unlike output layer, we can not calculate it directly. So, we back propagate it from the output layer. It is shown by the equations below:
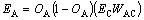
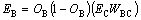
After obtaining the error for the hidden layer, we have to find the new weight values in between input layer and hidden layer. By repeating this method, we train the neural network. After training the neural network, we give the query to the system and the system will merge the unique links from different search engines and rank the unique links based on the trained neural network using the score generated in the neural network for each unique links. The algorithm of our proposed technique is given.
Algorithm of proposed technique:
Input: Query
Output: Ranked list
Give query
Apply query to different search engines
Take top n list from each search engines
Merge the lists based on unique links
For each unique links
Calculate domain value Us(p), position Rs(p) and co-occurrence Co-O(p)
End for
Separate query words from input query
Apply in word net and take synonyms
For each query word w.r.t unique links
Calculate title based value Ts(p), snippet based value Ss(p) and content based value Cs(p)
For each synonyms with respect to unique links
Calculate title based value Ts(p), snippet based value Ss(p) and content based value Cs(p)
End for
End for
Apply calculated values with user ranked list to neural network to train the system
Neural network give score for each link for the newly given query
Rank the list based on score from neural network
4 Results and discussion
This section shows the result for the proposed technique in comparison with the existing technique [29]. We use different bench mark queries from TREC 2002 web track data and user queries. Our technique is implemented in Java (jdk 1.7) that has system configuration as core2duo processor with clock speed of 2.3 GHZ and RAM as 2 GB and that runs Windows7 OS.
4.1 Query description and our process
This section explains the queries used for comparison. We use five benchmark queries from TREC 2002 web track data and three user given queries. The five benchmark queries for the process are intellectual property, foods for cancer patients, federal funding mental illness, home buying and criteria obtain US. The user given queries tickets for UEFA Champions League Final 2010, distributed index construction and lungs cancer symptoms. We take top ten links from each search engine and the search engines are Google, Bing and Yahoo. Now, we have thirty links (top ten from each search engine) and we merge the links based on unique links. For example if we use three search engines, the query will be searched in all the three web search engines and we choose top ten lists from those three search engines and we merge the lists based on unique links, i.e. if a link present in the top ten list of the first search engine and if the same link is present in the top ten list of the second search engine, we will consider that link as a single link while merging the links. To compare the response time between the proposed technique and the existing technique, the experimentation is done using top fifty links and top hundred links from each search engine.
4.2 Retrieval effectiveness evaluation
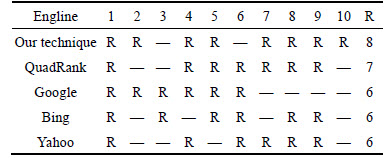
The effectiveness of the retrieval evaluation of our technique is compared with the existing technique [29]. The retrieval effectiveness is evaluated based on the benchmark queries from the TREC 2002 web track data and the queries given by the user. The evaluation is based on fifty users, i.e. the queries for our evaluation to fifty users and they take the top ten lists from each search engines and merged it based on the unique links and ranked the links based on the relationship with the query and their discernment. Eventually, the ranked lists of the fifty users are converted to a single ranked list to perform the evaluation of our technique. Table 5 shows the top list and relevant documents of the query tickets for UEFA Champions League Final 2010 when our technique is applied.
Table 5 is explained as follows. The first column represents the ranking for the query ��tickets for UEFA Champions League Final 2010�� using our technique and the second column represents the top links and the third column shows which of the documents are relevant to the given query with respect to the conclusion made by the user and the fourth column represents the ranking based on ��Google�� and the fifth column represents the ranking based on ��Bing�� and the sixth column represents the ranking based on ��Yahoo�� and the last column shows the ranking based on the existing technique. Similarly, we checked the retrieval effectiveness for all the queries given by the user and the benchmark queries from the TREC 2002 web track data. The retrieval effectiveness is then used to find the precision of our technique. Table 6 shows the relevant documents in the top ten lists for the query ��tickets for UEFA Champions League Final 2010��.
Table 6 is explained as follows: R denotes that the respective document of respective technique is relevant to the query.
4.3 Performance comparison
This section shows the performance of our technique compared to the existing technique and individual web search engines such as ��Google��, ��Bing�� and ��Yahoo��. The performance is calculated based on the precision. The precision is calculated for the queries given by the user and the benchmark queries from the TREC 2002 web track data. The precision is calculated by taking the total relevant documents retrieved for the query divided by total documents retrieved for the query.
Table 5 Top list and relevant documents of query tickets for UEFA Champions League Final 2010
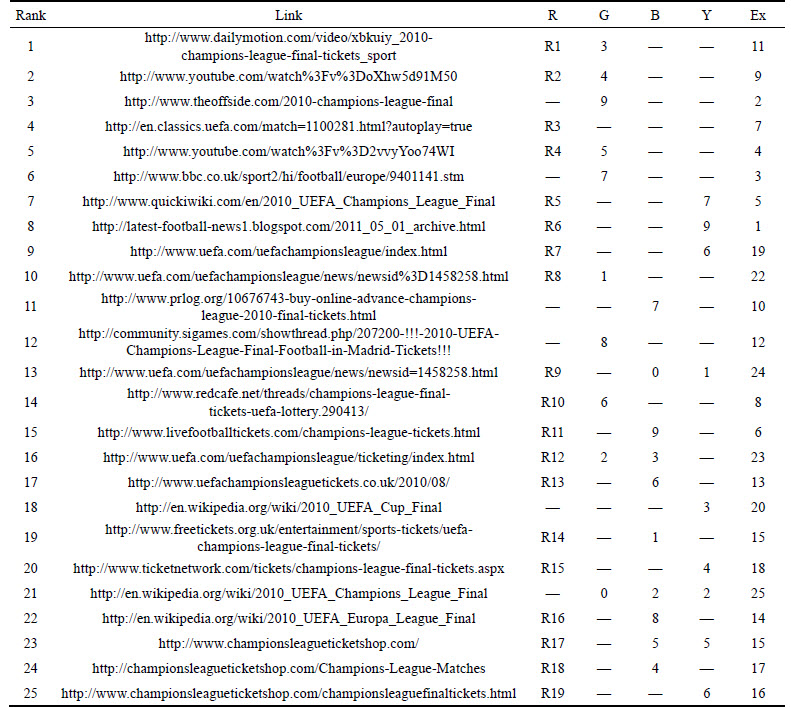
Table 6 Relevant document in top ten lists for query ��tickets for UEFA Champions League Final 2010��
4.3.1 Precision based on user given queries
The precision using user given queries is explained in this section. Figure 4 shows the precision comparison for the user given query ��tickets for UEFA Champions League Final 2010��.
Figure 4 shows the precision of our technique compared to the existing technique (QuadRank) [29] with the search engines for our technique for the user given query ��tickets for UEFA Champions League Final 2010��. Here, the precision of the technique is high compared to the other techniques. The precision for our technique is 76% and the precision obtained for the existing technique is 70% and the precision obtained using Google and Yahoo is 60% and the precision obtained using Bing is 50%.
Figure 5 shows the precision of our technique compared to the existing technique with the search engines we used. The precision in Fig. 5 is calculated for the user given query ��distributed index construction��. Here, the precision of our technique is high compared to the other techniques. The precision obtained for the technique is 76%, 72% using existing technique, 70% using Google search engine, 50% using Bing search engine and 60% using Yahoo search engine.
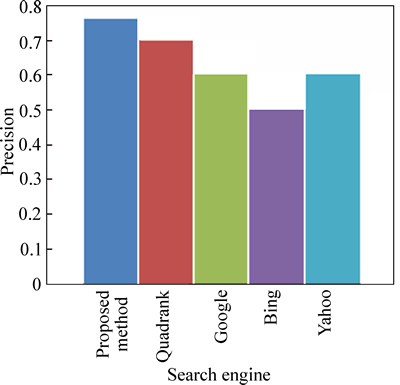
Fig. 4 Precision comparison for user given query ��tickets for UEFA Champions League Final 2010��
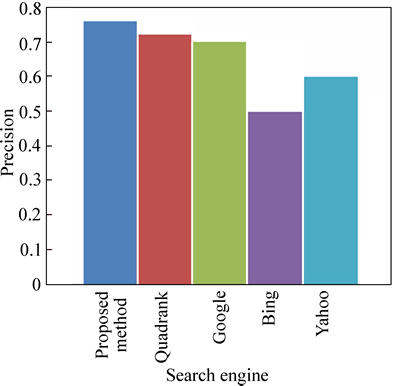
Fig. 5 Precision comparison for user given query ��distributed index construction��
Figure 6 shows the precision comparison of our technique compared to the existing technique for the user query ��lungs cancer symptoms��. Here, the precision of our technique is high compared to the existing technique. The precision obtained using our technique is 85% and the precision obtained using the existing technique is 72% and the precision obtained for the search engines Google, Bing and Yahoo are 60%.
4.3.2 Precision based on benchmark queries from TREC 2002
The precision using benchmark queries from TREC 2002 web track data is explained in this section. The TREC 2002 web track data queries that we used are intellectual property, foods for cancer patients, federal funding mental illness, home buying and criteria obtain US. Figure 7 shows the precision comparison based on TREC 2002 query intellectual property.
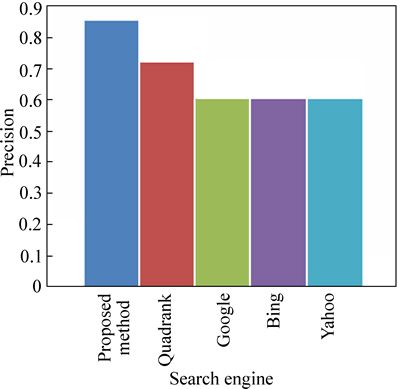
Fig. 6 Precision comparison for user given query ��lungs cancer symptoms��
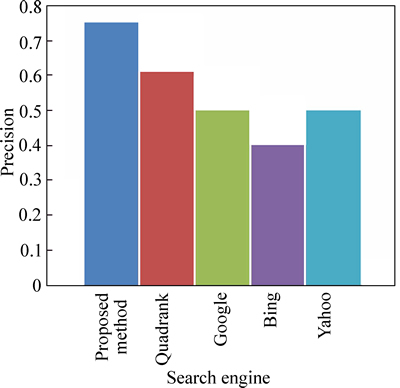
Fig. 7 Precision comparison based on TREC 2002 query intellectual property
Figure 7 shows that the precision of our technique obtained is 75% and the precision obtained by the existing technique is 61% and the precision is 50% for Google and Yahoo search engines and the precision is 40% for Bing search engine using the query ��intellectual property�� from TREC 2002 web track data.
Figure 8 shows the precision comparison of our technique compared to the existing technique based on TREC 2002 query foods for cancer patients. Here, the precision is 73% for our technique, 67% for the existing technique, 60% for Google and Yahoo search engines and 50% for Bing search engine.
Figure 9 shows the precision comparison based on the query ��federal funding mental illness�� from TREC 2002 web track data and Fig. 10 shows the precision comparison based on the query home buying from TREC 2002 web track data. In both Figs. 9 and 10, the precision of our technique is high compared to the existing technique and the web search engines that we took for our process.
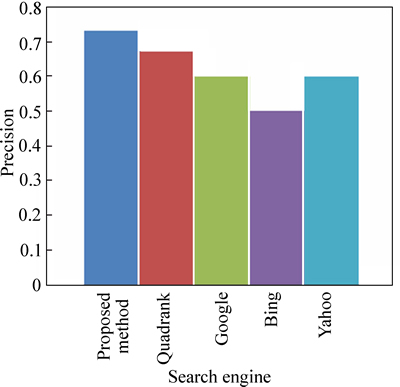
Fig. 8 Precision comparison based on TREC 2002 query foods for cancer patients
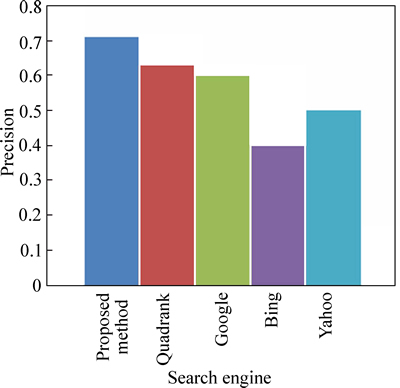
Fig. 9 Precision comparison based on TREC 2002 query federal funding mental illness
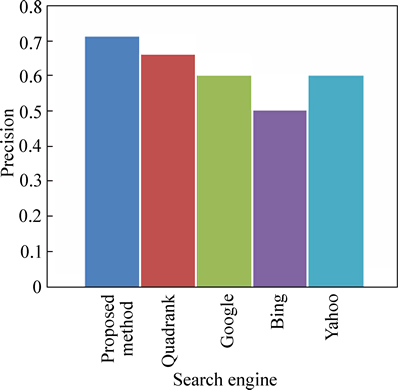
Fig. 10 Precision comparison based on TREC 2002 query home buying
Figure 11 shows the precision comparison of our technique compared to the existing technique for the query ��criteria obtain US�� from TREC 2002 web track data.Here also our technique obtains high precision compared to the existing technique and the web search engines used in our technique.
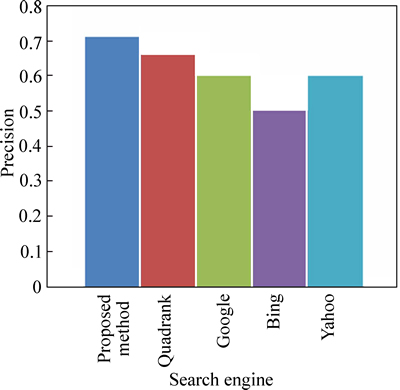
Fig. 11 Precision comparison based on TREC 2002 query criteria obtain US
4.4 Evaluation of response time
This section shows the response time of our technique compared to the existing technique for the user given queries and the benchmark queries from TREC 2002 web track data based on top fifty links and top hundred links.
Table 7 shows the response time comparison of our technique with the existing technique [29] in terms of top fifty links. After giving the query, top fifty links from each search engine are taken and merged based on the unique links. Thereafter, the queries are ranked using our technique and the existing technique. The values in Table 7 are in ms and the first column shows the queries used for our comparison and Tret represents the retrieval time that the Meta search engine needs to download the result list from the component engines and N represents the list which derives from the fusion of the input rankings and Tpr represents the time taken to rank the merged list. In most cases, the time taken to rank the merged list of our technique is less compared to the existing technique when top fifty links are taken. Table 8 shows the response time comparison in terms of top hundred links.
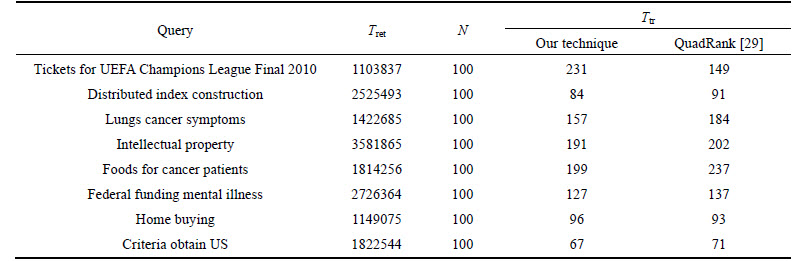
Table 8 shows the response time comparison of our technique with the existing technique [29] in terms of top hundred links. After giving the query, top hundred links from each search engine are taken and merged based on the unique links and then the queries are ranked using our technique and the existing technique. Here also the time taken to rank the merged list using our proposed technique is less in most cases compared to the time taken to rank the merged list using the existing technique.
Table 7 Response time comparison in terms of top fifty links
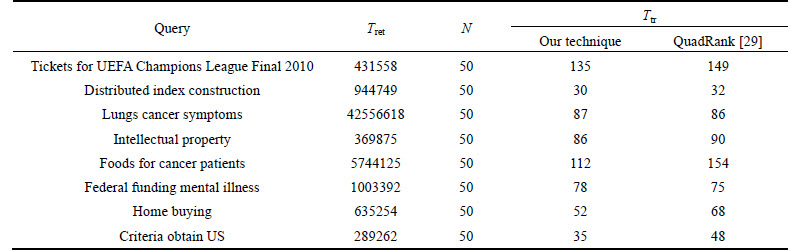
Table 8 Response time comparison in terms of top hundred links
5 Conclusions
1) An artificial neural network is proposed based on merging score for Meta search engine. We give query to different search engines and chose top n lists from different search engines and we merge based on the unique links.
2) Using the merged list, title based calculation, snippet based calculation, content based calculation, domain calculation, position calculation and co-occurrence calculation are calculated. The calculated values with the user ranked list are given to the neural network to rank the list. Different queries are used given by the user and the benchmark queries from TREC 2002 web track data to perform the analysis.
3) This technique is compared with the existing technique in terms of precision and response time. For user query our technique reported a precision of about 79% and for benchmark queries its about 72%. The proposed technique also reports a response time of about 76 ms for 50 links and 144 ms for 100 links.
4) In most cases the response time based on top fifty links and hundred links of our technique is better compared to the existing technique and the precision of our technique is high compared to the existing technique for the different queries we gave.
References
[1] SUGIURA A, ETZIONI O. Query routing for Web search engines: architecture and experiments [J]. Computer Networks, 2000, 33(1-6): 417-429.
[2] MANNING C D, RAGHAVAN P, SCHUTZE H. Introduction to Information Retrieval [M]. New York, USA: Cambridge University Press, 2008.
[3] MENG W, YU C, LIU K L. Building efficient and effective metasearch engines [J]. ACM Computing Surveys, 2002, 34(1): 48-89.
[4] SPINK A, JANSEN B J, BLAKELY C, KOSHMAN S. Overlap among major Web search engines [C]// Proceedings of the IEEE International Conference on Information Technology: New Generations (ITNG), Las Vegas, USA, 2006: 370-374.
[5] MUKHOPADHYAY D, SHARMA M, JOSHI G, PAGARE T, PALWE A. Experience of developing a meta-semantic search engine [C]// International Conference on Cloud and Ubiquitous Computing and Emerging Technologies. Pune, India, 2013: 167-171.
[6] VOGT C C. Adaptive combination of evidence for information retrieval [D]. San Diego: University of California at San Diego, 1999.
[7] FANG Qi-zhi, XIAO Han, ZHU Shan-feng. Top-d rank aggregation in web meta-search engine [C]// Proceedings of Fourth International Conference on Frontiers in algorithmic. 2010: 35-44.
[8] LI Lin, XU Guan-dong, ZHANG Yan-chun, KITSUREGAWA M. Random walk based rank aggregation to improving web search [J]. Knowledge-Based Systems, 2011, 24: 943-951.
[9] ISHII H, TEMPO R, BAI E W. A web aggregation approach for distributed randomized pagerank algorithms [J]. IEEE Transactions on Automatic Control, 2012, 57(11): 2703-2717.
[10] COPPERSMITH D, FLEISCHER L, RUDRA A. Ordering by weighted number of wins gives a good ranking for weighted tournaments [J]. ACM Transactions on Algorithms (TALG), 2010, 6(3): 1�C13.
[11] SUDEEPTHI G, ANURADHA G, BABU M S P. A survey on semantic web search engine [J]. IJCSI International Journal of Computer Science Issues, 2012, 9(2): 241-245.
[12] TAN P N, JIN R. Ordering patterns by combining opinions from multiple sources [C]// Proceedings of the ACM International Conference on Knowledge Discovery and Data Mining (SIGKDD). Seattle, USA, 2004: 695-700.
[13] LIU Y T, LIU T Y T, MA Q, LI Z M H. Supervised rank aggregation [C]// Proceedings of the ACM International Conference on World Wide Web (WWW). Alberta, Canada, 2007: 481-489.
[14] RENDA M E, STRACCIA U. Web metasearch: rank vs score based rank aggregation methods [C]// Proceedings of the ACM International Symposium on Applied Computing (SAC). 2003: 841-846.
[15] ALI R, NAIM I. Neural network based supervised rank aggregation [C]// Proceedings of International Conference on Multimedia, Signal Processing and Communication Technologies. Uttar Pradesh, India, 2011: 72-75.
[16] SHOKOUHI M. Segmentation of search engine results for effective data-fusion [C]// Proceedings of the European Conference on Information Retrieval (ECIR). Rome, Italy, 2007: 185-197.
[17] OZTEKIN B U, KARYPIS G, KUMAR V. Expert agreement and content based reranking in ametasearch environment using Mearf [C]// Proceedings of the ACM International Conference on World Wide Web (WWW). Honolulu, USA, 2002: 333-344.
[18] LAMBERTI F, SANNA A, DEMARTINI C. A relation-based page rank algorithm for semantic web search engines [J]. IEEE Transactions on Knowledge and Data Engineering, 2009, 21: 123-136.
[19] RASHID A, SUFYAN B M M. Aggregating subjective and objective measures of web search quality using modified shimura technique [J]. Studies in Fuzziness and Soft Computing-Forging New Frontiers: Fuzzy Pioneers II, 2008, 218: 269-293.
[20] ENDRULLIS S, THOR A, RAHM E, WETSUIT: An efficient mashup tool for searching and fusing web entities [J]. Proceedings of the VLDB Endowment, 2012, 5(12): 1970-1973.
[21] RASHID A, SUFYAN B M M. Automatic performance evaluation of web search systems using rough set based rank aggregation [C]// Proceedings of the First International Conference on Intelligent Human Computer Interaction. Allahabad, India, 2009: 344-358.
[22] D��AMATO C, FANIZZI N, LAWRYNOWICZ A. Deductive aggregation of semantic web query results [J]. Research and Applications Lecture Notes in Computer Science 2010, 6088: 91-105.
[23] ARZANIAN B, AKHLAGHIAN F, MORADI P. A multi-agent based personalized meta-search engine using automatic fuzzy concept networks [C]// Third International Conference on Knowledge Discovery and Data Minning, Washington D C, USA, 2010: 208-211.
[24] SANTOS R L T, MACDONALD C, OUNIS I. Mimicking web search engines for expert search [J]. Information Processing and Management, 2011, 47: 467-481.
[25] STEINMETZ N, LAUSEN H. Ontology-based feature aggregation for multi-valued ranking [J]. Lecture Notes in Computer Science- Service-Oriented Computing. ICSOC/ServiceWave 2009 Workshops, 2010, 6275: 258-268.
[26] SKOUTAS D, SACHARIDIS D, SIMITSIS A, SELLIS T. Ranking and clustering web services using multicriteria dominance relationships [J]. IEEE Transactions on Services Computing, 2010, 3(3): 163-177.
[27] CERI S, ABID A, HELOU M A, BARBIERI D, BOZZON A, BRAGA D, BRAMBILLA M, CAMPI A, CORCOGLIONITI F, VALLE E D, EYNARD D, FRATERNALI P, GROSSNIKLAUS M, MARTINENGHI D, RONCHI S, TAGLIASACCHI M, VADACCA S. Search computing managing complex search queries [J]. IEEE Internet Computing, 2010, 14(6): 14-22..
[28] TELANG A, LI C, CHAKRAVARTHY S. One size does not fit all: Toward user- and query-dependent ranking for web databases [J]. IEEE Transactions on Knowledge and Data Engineering, 2012, 24(9): 1671-1685.
[29] AKRITIDIS L, KATSAROS D, BOZANIS P. Effective rank aggregation for metasearching [J]. The Journal of Systems and Software, 2011, 84: 130-143.
[30] ISHII H, TEMPO R, BAI E W. A web aggregation approach for distributed randomized pagerank algorithms [J]. IEEE Transactions on Automatic Control, 2012, 57(11): 2703-2717.
[31] KEYHANIPOUR A H, MOSHIRI B, KAZEMIAN M, PIROOZMAND M, LUCAS C. Aggregation of web search engines based on users' preferences in WebFusion [J]. Journal Knowledge- Based Systems, 2007, 20 (4): 321-328.
[32] AMIN G R, EMROUZNEJAD A. Optimizing search engines results using linear programming [J]. Expert Systems with Applications, 2011, 38: 11534-11537.
[33] LI Lin, XU Guan-dong, ZHANG Yan-chun, MASARU K. Random walk based rank aggregation to improving web search [J]. Knowledge-Based Systems, 2011, 24: 943-951.
[34] FANG Qi-zhi, XIAO Han, ZHU Shan-feng. Top-d rank aggregation in Web meta-search engine [C]// Proceeding FAW'10 Proceedings of the 4th international conference on Frontiers in algorithmics. Berlin, Heidelberg, Germany, 2010: 35-44.
[35] LI L, YANG Z, KITSUREGAWA M. Using ontology-based user preferences to aggregate rank lists in web search [C]// Computer Science-Advances in Knowledge Discovery and Data Mining. 2008: 923-931.
(Edited by FANG Jing-hua)
Received date: 2015-01-05; Accepted date: 2016-06-07
Corresponding author: P. Vijaya; Tel: +96-892316383; E-mail: pvijaya0169@hotmail.com

