基于改进的隐马尔科夫模型的词性标注方法
袁里驰
(江西财经大学 信息学院 数据与知识工程江西省重点实验室,江西 南昌,330013)
摘要:针对隐马尔可夫(HMM)词性标注模型状态输出独立同分布等与语言实际特性不够协调的假设,对隐马尔可夫模型进行改进,引入马尔可夫族模型。,该模型用条件独立性假设取代HMM模型的独立性假设。将马尔可夫族模型应用于词性标注,并结合句法分析进行词性标注。用改进的隐马尔可夫模型进行词性标注实验。实验结果表明:与条件独立性假设相比,独立性假设是过强假设,因而基于马尔可夫族模型的语言模型更符合语言等实际物理过程;在相同的测试条件下, 马尔可夫族模型明显好于隐马尔可夫模型,词性标注准确率从94.642%提高到97.126%。
关键词:隐马尔可夫模型;马尔可夫族模型;词性标注;Viterbi 算法
中图分类号:TP391.1 文献标志码:A 文章编号:1672-7207(2012)08-3053-05
A part-of-speech tagging method based on improved hidden Markov model
YUAN Li-chi
(Jiangxi Key Lab of Data & Knowledge Engineering, School of Information Technology,
Jiangxi University of Finance & Economics, Nanchang 330013, China)
Abstract: In order to defy the unrealistic assumption of the part-of-speech tagging method based on hidden Markov models that successive observations are independent and identically distributed within a state, Markov family model (MFM) was introduced. Independence assumption in HMM was placed by conditional independence assumption in MFM. Markov Family model was applied to part-of-speech tagging, and syntactic parsing was combined with part-of-speech tagging. The part-of-speech tagging experiments show that Markov family models (MFMs) have higher performance than hidden. From the view of the statistics, the assumption of independence is stronger than the assumption of conditional independence, so language model based on MFM is more realistic than HMM language mode. Markov models (HMMs) under the same testing conditions, the precision is enhanced from 94.642% to 97.126%.
Key words: hidden Markov model; Markov family model; part-of-speech tagging; Viterbi algorithm
所谓词性标注[1],就是根据句子上下文中的信息给句中的每个词一个正确的词性标记。词性标注是对自然语言进一步处理的重要基础,在许多应用领域,如文本索引、文本分类、语言合成、语料库加工,词性标注都是一个重要环节,因此,研究词性标注的方法具有重要意义。现有的词性标注所采用的语言模型主要分为基于规则的方法[2-3]和基于统计的方法[4-16]。基于规则的词性标注依赖手工编辑的规则,将输入的词序列分解成形态组件,将结果的词汇类别作为这些组成的函数加以计算。基于规则的标注系统与系统设计者的语言能力有关,其中规则集直接体现了设计者的语言能力。然而,要对某一种语言的各种语言现象都构造规则是一项很艰难也很耗时的任务。基于规则的标注系统另一个常见问题是:当根据规则判断1个词的词性时可能面临多种选择,若不根据上下文则很难作出正确的选择。基于规则的方法适应性较差,并且非统计模型的本质使它通常作为一个独立的标注器,很难被用作概率模型的组件部分。基于统计的方法却能弥补此缺点。隐马尔可夫模型[1]是统计模型中应用较广、效果较好的模型之一。对于隐马尔科夫模型(hidden Markov model,HMM)用于词性标注,国内外学者进行了大量研究,如:1988年Church等提出了第一个基于词语概率和转移概率的隐马尔科模型英文标注器;1994年Schvtze等提出了可变记忆马尔科夫模型(Variable memory Markov model);1999年Scott等提出了完全二阶隐马尔科夫模型(Second order hiddenv Markov model),Sang-Zoo等提出了基于词汇信息的隐马尔科夫模型(Lexicalized hidden Markov model);魏欧等[6]介绍了传统隐马尔科夫模型用于汉语词性标注的具体分析与改进;梁以敏等[7]提出了完全二阶隐马尔科夫模型;屈刚等[8]介绍了双重状态隐马尔科夫模型等等。统计标注方法如隐马尔可夫模型在计算每一输入词序列的最可能词性标注序列时,既考虑上下文,也考虑二元或三元概率参数(这些参数可通过已标注用于训练的语料估计得到)。目前,许多种语言都有人工标注的训练语料,并且统计模型有很强的健壮性,这些优点使得统计方法成为当前主流的词性标注方法。基于隐马尔可夫模型的词性标注存在的不足有:为了达到很高的标注准确率,需要大量的训练语料;传统的基于隐马尔可夫模型的标注方法没有结合现有的语言知识。隐马尔可夫模型在用于标注时进行了3个基本假设:(1) 马尔可夫性假设;(2) 不动性假设;(3) 输出独立性假设,即输出(词的出现)概率仅与当前状态(词性标记)有关。这些假定尤其第3个假定太粗糙。为此,本文作者引入一种统计模型即马尔可夫族模型[16]。假定1个词出现的概率既与它的词性标记有关,也与前面的词有关,但该词的词性标记与该词前面的词关于该词条件独立(即在该词已知条件下是独立的),在上面假设下,将马尔可夫族模型进行简化,可用于词性标注。实验结果证明:在相同的测试条件下,基于马尔可夫族模型的词性标注方法与常规的基于隐马尔可夫模型的词性标注方法相比大大提高了标注准确率。在其他许多自然语言处理技术领域中(如分词、句法分析、语音识别等),马尔可夫族模型也非常有用。
1 基于隐马尔可夫模型的词性标注
设T为标注集,W为词集,很自然地可以定义一个二元的HMM词性标注模型(T,A,W,B,π)[1]。其中:A为状态转移概率分布矩阵;B为状态符号发 射的概率分布矩阵;π为初始状态概率分布。A,B和π可通过已标注训练语料估计得到。在上述模型下,模型的状态是词性标记;输出符号是词。在已知输入词序列w1,n的条件下, 寻找最可能标记序列t1,n的任务, 可看作在给定观察序列w1,n条件下搜索最可能的HMM状态序列的问题:
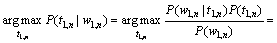
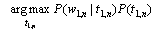 (1)
(1)
首先,引入独立性假设,认为词序列中的任意一个词wi的出现概率只同当前词的词性标记ti有关。而与周围(上下文)的词,词类标记无关。其次,采用二元假设,即认为任意词类标记的出现概率只与它紧邻的前一个词类标记有关。由上述假设,有:
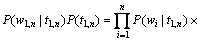
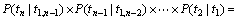
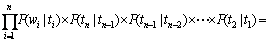
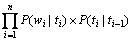 (2)
(2)
为简单起见,定义p(t1|t0)=1.0。
2 基于马尔可夫族模型的词性标注
设S1为词性标记集,S2为词表中词的集合,任意一个词的词性标记ti和该词wi前面的词关于该词条件独立(即在该词已知的条件下独立):
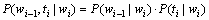 (3)
(3)
在上述假定下,可以利用马尔可夫族模型进行词性标注[16](为了简单,假定随机向量 {wi,ti}i≥1的成分变量{wi}i≥1和{ti}i≥1都是2阶马尔可夫链):
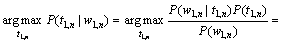
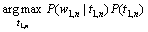 (4)
(4)
而

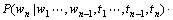
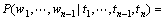
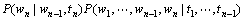 (5)
(5)
其中:
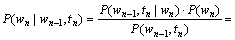
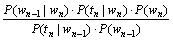 (6)
(6)
因而,
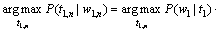
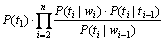 (7)
(7)
在得到词性标注模型后的下一个问题是如何寻找一种有效算法,求出在给定输入条件下概率最大的词性标记序列。Viterbi 算法[2]是一种动态编程的方法,能够根据模型参数有效地计算出一给定词序列w1,…,wn最可能产生的词性标记序列t1,…,tn。计算过程如下:
1. comment: Given: a sentence of length n, the number of the tag set is T
2 .comment: initialization
3. δ1(tj)=P(w1|tj)・P(tj),1≤j≤T
4. ψ(tj)=0,1≤j≤T
5. comment: Induction
6. for i: = 1 to n-1 step 1 do
7. for all tags tj do
8. 
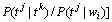
9. 
10. end
11. end
12. comment: Termination and path-readout, X1,…, Xn are the tags we choose for words w1,…,wn
13. 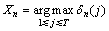
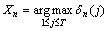
14. for j: =n-1 to 1 step -1 do
15. Xj=ψj+1(Xj+1)
16. end
17.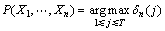
图1 词性标注算法
Fig.1 Part-of-Speech tagging algorithm
3 结合句法分析进行词性标注
在汉语短语句法分析中,首先要对句子进行汉语词语切分和词性标注,然后,在词性标注的基础上进行句法分析。词性标记在句法分析中起了至关重要的作用。英语中,词的形态变化决定了词的词性,而词性又决定了词在句子中的句法功能。在这里,“词性”作为句法分析的基础,起到了枢纽作用:一方面,“词性”是词的特征,可以从词的形态变化中直接判断出来;另一方面,词性又反映了词语在句子组织过程中充当的语法功能。
中心词驱动句法分析模型[18]是最具有代表性的词汇化模型。为了发挥词汇信息的作用,中心词驱动模型为文法规则中的每一个非终结符(None terminal)都引入核心词/词性信息。由于引入词汇信息,不可避免地将出现严重的稀疏问题。为了缓解这个问题,中心词驱动模型把每一条文法规则的右手侧分解为三大部分:一个中心成分;若干个在中心左边的修饰成分;若干个在中心右边的修饰成分。可以写成如下形式:
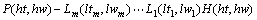
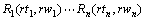 (8)
(8)
其中:P为非终结符;H为中心成分;L1为左边修饰成分;R1为右边修饰成分;hw,lw和rw均为成分的核心词,ht,lt和rt分别为它们的词性。进一步假设:首先由P产生核心成分H,然后,以H为中心分别独立地产生左右两边的所有修饰成分。这样,形如(8)式的文法规则的概率为:

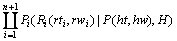 (9)
(9)
其中:Lm+1和Rn+1分别为左右两边的停止符号。
为了结合句法分析进行词性标注,对形如(8)式的文法规则的概率修改为:
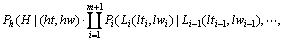
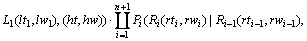
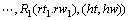 (10)
(10)
其中:Lm+1和Rn+1分别为左、右两边的停止符号。式(10)中的概率
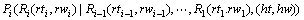
可分解为2个概率:
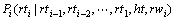 (11)
(11)
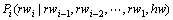 (12)
(12)
的乘积,句法分析中有关词性标注的概率为见式(11)。再假定rwi,rti-1,rti-2,…,rt1,ht关于rti条件独立,则有:
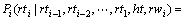
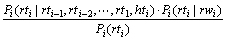 (13)
(13)
式(13)中概率
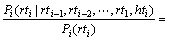
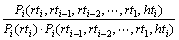 (14)
(14)
即为rti,rti-1,rti-2,…,rt1,hti间的互信息。可见:式(13) 概率意义十分明确,也符合语言现象。式(13) 中的概率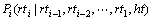 可以考虑引入基于相邻词词性搭配关系的词性标注模型来解决。
可以考虑引入基于相邻词词性搭配关系的词性标注模型来解决。
4 实验结果
选取1998年《人民日报》部分标注语料作为测试和训练语料,内容涉及政治、经济、文艺、体育、报告文学等多种题材。语料使用42种标记,从中抽取30万词的语料进行训练。从训练集外随机抽取部分语料作为测试集, 其中测试语料约有 244 974个记号,该语料有关特性如表1所示。采用词性标注的准确率对模型进行评价,实验结果见表2。
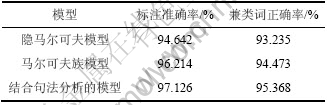
从表2可见:在相同测试条件下,基于马尔可夫族模型的词性标注方法与常规的基于隐马尔可夫模型词性标注方法相比大大提高了标注准确率, 标注准确率从94.642%提高到96.214%; 基于马尔可夫族模型,并结合中心词驱动句法分析的词性标注方法更进一步将标注准确率提高到97.126%。
表1 标注语料有关特性
Table 1 Some properties of annotated corpus
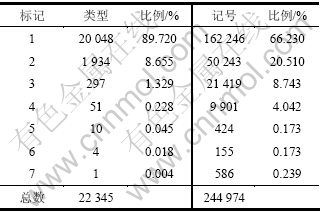
表2 词性标注实验结果
Table 2 Experimental results of part-of-speech tagging
5 结论
(1) 在基于马尔可夫族模型的词性标注中,前词的词性不但与前面词的词性有关,而且与当前词本身有关,因而,在相同测试条件下,基于马尔可夫族模型的词性标注方法与常规的基于隐马尔可夫模型词性标注方法相比大大提高了标注准确率, 标注准确率从94.642%提高到96.214%。
(2) 在汉语短语句法分析中,首先要对句子进行汉语词语切分和词性标注,然后,在词性标注的基础上进行句法分析。词性标记在句法分析中起到了至关重要的作用。对中心词驱动句法分析模型的规则进行 分解和修改,基于马尔可夫族模型,并结合中心词驱动句法分析的词性标注方法更进一步将标注准确率提高到97.126%。
参考文献:
[1] Christopher D M, Schutze H. Foundations of statistical natural language processing[M]. London: the MIT Press, 1999: 136-157.
[2] Turish B. Part-of-speech tagging with finite-state morphology[C]// Proceedings of the International Conference on Collocations and Idioms: linguistic, Computational, and Psycholinguistic Perspective. Berlin, 2003: 18-20.
[3] 姜涛, 姚天顺, 张俐. 基于实例的中文分词-词性标注方法的应用研究[J]. 小型微型计算机系统, 2007, 28(11): 2090-2093.
JIANG Tao, YAO Tian-shun, ZHANG Li. Application study of example based chinese word segmentation and part-of-speech tagging method[J]. Journal of Chinese Computer Systems, 2007, 28(11): 2090-2093.
[4] 王敏, 郑家恒. 基于改进的隐马尔科夫模型的汉语词性标 注[J]. 计算机应用, 2006, 26(12): 197-198.
WANG Min, ZHENG Jia-heng. Chinese part-of-speech tagging based on improved hidden Markov mode[J]. Computer Applications, 2006, 26(12): 197-198.
[5] Charniak E, Hendricson C, Jacobson N, et al. Equations for part-of-speech tagging[C]//Proceedings of the Eleventh National Conference on Artificial Intelligence. Menlo Park: AAAI Press/MIT Press, 1993: 784-789.
[6] Brants T. A statistical part-of-speech tagger[C]//Proceedings of the Sixth Conference on Applied Natural Language Processing (ANLP-2000). Seattle, 2000: 224-231.
[7] 魏欧, 吴健, 孙玉芳. 基于统计的汉语词性标注方法的分析与改进[J]. 软件学报, 2000, 11(4): 473-480.
WEI Ou, WU Jian, SUN Yu-fang. Analysis and improvement of statistics-based Chinese part-of-speech tagging[J]. Journal of Software, 2000, 11(4): 473-480.
[8] 梁以敏, 黄德根. 基于完全二阶隐马尔科夫模型的汉语词性标注[J]. 计算机工程, 2005, 31(10): 177-179.
LIANG Yi-min, HUANG De-gen.Chinese part-of-speech tagging based on full second-order hidden Markov model[J]. Computer Engineering, 2005, 31(10): 177-179.
[9] 屈刚, 陆汝占.一个改进的词性标注系统[J].上海交通大学学报, 2003, 37(6): 897-900.
QU Gang, LU Ru-zhan. An improved part-of-speech(POS) tagging system[J]. Journal of Shanghai Jiaotong University, 2003, 37(6): 897-900.
[10] Gimenez J, Marquez L. Fast and accurate part-of-speech tagging: The SVM approach revisited[C]//Proceedings of the International Conference on Recent Advances in Natural Language Processing. Bulgaria, 2003: 158-165.
[11] 赵岩, 王晓龙, 刘秉权, 等. 融合聚类触发对特征的最大熵词性标注模型[J]. 计算机研究与发展, 2006, 43(2): 268-274.
ZHAO Yan, WANG Xiao-long, LIU Bing-quan, et al. Fusion of clustering trigger-pair features for pos tagging based on maximum entropy model[J]. Journal of Computer Research and Development, 2006, 43(2): 268-274.
[12] 邢富坤, 宋柔, 罗智勇. SSD模型及其在汉语词性标注中的应用[J]. 中文信息学报, 2010, 24(1): 20-24.
XING Fu-kun, SONG Rou, LUO Zhi-yong. Symbol-and- statistics decoding model and its application in chinese pos tagging[J]. Journal of Chinese Information Processing, 2010, 24(1): 20-24.
[13] 刘遥峰, 王志良, 王传经. 中文分词和词性标注模型[J]. 计算机工程, 2010, 36(4): 17-19.
LIU Yao-feng, WANG Zhi-liang, WANG Chuan-jing. Model of Chinese words segmentation and part-of-word tagging[J]. Computer Engineering, 2010, 36(4): 17-19.
[14] 朱聪慧, 赵铁军, 郑德权. 基于无向图序列标注模型的中文分词词性标注一体化系统[J]. 电子与信息学报, 2010, 32(3): 700-704.
ZHU Cong-hui, ZHAO Tie-jun, ZHENG De-quan. Joint Chinese word segmentation and pos tagging system with undirected graphical models[J]. Journal of Electronics & Information Technology, 2010, 32(3): 700-704.
[15] 仲其智, 姚建民. 低频词的中文词性标注研究[J]. 计算机应用与软件, 2011, 28(3): 182-185.
ZHONG Qi-zhi, YAO Jian-min. Research on infrequent words chinese part-of-speech tagging[J]. Computer Applications and Software, 2011, 28(3): 182-185.
[16] 于江德, 葛彦强, 余正涛. 基于条件随机场的汉语词性标注[J]. 微电子学与计算机, 2011, 28(10): 63-66.
YU Jiang-de, GE Yan-qiang, YU Zheng-tao. Chinese part-of-speech tagging based on conditional random fields[J]. Microelectronics & Computer, 2011, 28(10): 63-66.
[17] 袁里驰. 基于改进的隐马尔科夫模型的语音识别方法[J]. 中南大学学报: 自然科学版, 2008, 39(6): 1303-1308.
YUAN Li-chi. A speech recognition method based on improved hidden Markov model[J]. Journal of Central South University: Science and Technology, 2008, 39(6): 1303-1308.
[18] Collins M. Head-driven statistical models for natural language parsing[D]. Pennsylvania: The University of Pennsylvania, 1999: 35-47.
(编辑 陈灿华)
收稿日期:2011-09-22;修回日期:2011-11-26
基金项目:国家自然科学基金资助项目(60763001);江西省自然科学基金资助项目(2010GZS0072);江西省教育厅科技项目(GJJ12271)
通信作者:袁里驰(1973-), 男,湖南邵阳人,博士后,副教授,从事自然语言处理研究;电话:0791-83983891;E-mail:yuanlichi@sohu.com

