�Ի���SNM������ϴ�㷨���Ż�
�Ž���1������2����ӵ��1��ԬСһ1
(1. ���ϴ�ѧ ��Ϣ��ѧ�빤��ѧԺ������ ��ɳ��410083��
2. ���ϴ�ѧ ��ѧ����ѧԺ������ ��ɳ��410083)
ժ Ҫ���Ի����ڽ������㷨SNM(basic sorted-neighborhood method)���з�����ָ���䲻�㣻�������SNM�㷨��һ���Ż��㷨��ͨ���ɼ����ϴ�ѧұ����﹤�̻���֪ʶ���2 000��������¼��Ϊ�������ݽ���ʵ���о����Լ�¼�ġ������ݡ�����DC������ع淶������ϴ�����ء��о������������SNM�㷨��ȣ���ͬ�������㻷���£��Ż��㷨���л��ʡ���ʶ���ʺ�ִ��ʱ�������������ơ�
�ؼ��ʣ������ھ�������ϴ���ظ���¼��SNM�㷨
��ͼ����ţ�TP393 ���ױ�־�룺A ���±�ţ�1672-7207(2010)06-2240-06
Optimization algorithm for cleaning data based on SNM
ZHANG Jian-zhong1, FANG Zheng2, XIONG Yong-jun1, YUAN Xiao-yi1
(1. School of Information Science and Engineering, Central South University, Changsha 410083, China;
2. School of Chemistry and Chemical Engineering, Central South University, Changsha 410083, China)
Abstract: The basic sorted-neighborhood method (SNM) was introduced and the analysis was made on its deficiency. An improved algorithm of data cleaning based on SNM was put forward. And the experiments were made on more than 2 000 sample records data from the mineral metallurgy institutional database of Central South University. Key task was cleaning dirty data and removing approximately duplicate records according to dublin core (DC) standard and other criterion. The results show that the improved algorithm is better than SNM in the aspects of recall, precision and run time in the same computer condition.
Key words: data mining; data cleaning; approximately duplicate records; SNM algorithm
�ڹ�������֪ʶ��ʱ������һ����Ҫ�Ĺ����ǽ��ո����ʱԪ���ݲִ��е�DC(Dublin core)Ԫ���ݽ��й淶��[1]�������淶���Ԫ����д��DCԪ�������ġ�������ЩԪ�������Բ�ͬ�ļӹ���λ������¼����������ʾ��һ�¡�ƴд����ͼ�¼�ظ����������������������������ظ���¼��Ϣ���أ�Ӱ���ȫ�ʺͲ��ʣ����ԣ���Ԫ���ݵ�����������ǰ����Ҫ��Ԫ���ݽ�����ϴ���ڴ���������ݼ�ʱ��ƥ���ظ���¼��һ��dz���ʱ�Ĺ��̡�Ŀǰ�����������ظ���¼ʶ����㷨Ϊ�����ڽ�����(SNM)������ƥ������൱�ڶ�2����¼�����ѿ��������㷨ʱ�临�ӶȽϴ�[2]���ڴˣ��������߷���SNM�㷨��ȱ�ݣ����һ�ֻ�������ؼ���Ԥ��������ͬ�ؼ��ֶ����ڽ��������ƶ��ٶ����С�������������ظ���¼ʶ����㷨����ͨ��ʵ��˵���Ż��㷨����ȷ�ԡ�
1 Ԫ������ϴ
������ϴ���Ƿ����������ݡ�������ԭ��ʹ�����ʽ���������м����ֶκͷ���ȥ��ϴ����������ת��Ϊ����Ҫ������ݣ��Ӷ�������ݼ�������[3]��������ϴ(Data cleaning)��Ŀ���Ǽ�������д��ڵĴ���Ͳ�һ�£������߸�������������������ݵ�����[4]��������ϴģ����ͼ1��ʾ����������ʱ���ݿ�װ�ص�����Ԫ���ݲִ�ʱ��������ϴ������Ҫ�����ݱ��������ݽ�����������ǿ���ظ����ݹ鲢4����ɣ����ݱ���������ݸ�ʽ�Ĺ淶�������ݱ��﷽ʽ��ͬһ�������ݽ�����Ҫ��������ֶεIJ�ֺͺϲ���������ǿ��Ҫ��ԭʼ���ݽ��в��䣬��֤���ݵ������ԣ��ظ����ݹ鲢��Ҫ�Ƕ������ظ���¼�������ϲ���

ͼ1 ������ϴģ��
Fig.1 Data cleaning model
1.1 ������ϴ��������
Ϊʵ��������ϴ�Զ�ִ�У��ؼ�����ϴ�����壬��ϴ������ͼ2��ʾ��

ͼ2 ������ϴ����
Fig.2 Data cleaning flow chart
�ڹ����ж����˴������ͼ�����Ӧ�Ĵ������ԡ����磬��������ֵʱ����Ӧ�ö���������¼���ǽ�ij���ض���ֵ���룬�ⶼ���ɹ������ļ��еĴ�������(error type)�������(policy)��������(op_class)����������������������������ļ���Ԥ����Ĵ���������ƥ��Ĵ���ʱ���Ͱ���Ԥ����Ĵ��������Խ��д�����������¼����������Ŀ��ṹ�����ݣ���������ӵ�����Ԫ���ݲִ�����Щ���̶�������ϴ����������ִ�С���ϴ������ϵͳ������Ҫ�IJ���������ϵͳ������ϴ����ȡ����������ϴ�����ִ�� �����
1.2 ��ϴ������
��ϴ�������2���֣�������������ԵĹ���͵�Υ��������ʱ�����õĴ�����������ϴ������һ������������������ͬʱ����Щ�����ŵ���ϴ�����ļ��У��Ա����ִ�л��߸��ٺ��ġ��������߲��ö����������������ϴ�����������������ϴ����У�������ϴ�����������ִ�С���ϴ�������ļ��й��������������[5]��
1.3 ���ݱ���
���ڲ�ͬ������Դ����ͬ�����ʵ����ݱ��ֵ���ʽ��ͬ����������Ϣ�ļ��������ݵı�����Ҫ���������ݸ�ʽ�Ĺ淶�������ݱ��﷽ʽ��ͳһ����
�����ݲִ��У��е�Ԫ�����������͵������ֶα�����ʽ���ӣ����磬YYYY��MM��DD��MM/DD/ YYYY�Լ���������ʽ����ģ������þ����ڽ�ͬһ������ͬ����ʽ���ֳ�����ͳһ��ʽΪ����ISO 8601 [W3CDTF]�淶����ʹ��YYYY-MM-DD�ĸ�ʽ[6]��
���ڡ����֡��ֶΣ���ͬϵͳ¼�����Ҳ������ͬ�������ģ�CHN��CN��Chinese�ȣ���ͳһ����RFC 1766����������ִ���淶���˱�������1����2��Ӣ����ĸ��ɵ����Դ��롣��������CN��ʾ��
1.4 ���ݽ���
���ݴ��ڲ�ͬ��ϸ�ڼ����Ϊ���ȡ�����Խ�ߣ���ʾ�ۺϳ̶�Խ�ߡ����������ݲִ��еIJ�ѯ�漰��ͬ��ϸ�ڣ���ͬ������Դ����Ϣ���������ܾ��в�ͬ�����ȣ���ʹ�ö����Բ�ͬ����Դ�����ݺ��ѽ�����Ӧ�ıȽϡ���ģ��Խṹ��ɢ�����Բ�ͬ����Դ��ԭʼ���ݽ��з�����ʹ֮�������õ��������ʺ���Ϣ�ļ�����Ҫ����Щ�ֶ���Ҫ��֣��е�����Ҫ�ϲ���
���ڿ�Ԫ�����е������ֶΣ��е�����Դ���������߶���¼��1���ֶ��У���Ҫ������Ϊ��Ҫ������(creator)�������������ֶ�(contributor)��
��������ʣ���Ҫ������ϲ���ͬһ�ֶ��У�����ͳһ�ķָ����ָ������������������ֶεĺϲ��ȡ�
1.5 ������ǿ
��������Ԫ���ݲִ�װ�����ݵĹ����У�ԭʼ���ݿ��ܲ���������ˣ��б�Ҫ��ԭʼ���ݽ��в� �䣬����������ǿ������������ǿͨ����������3�ַ�ʽ��
(1) �������в��������ֶβ����Ҫ����Ϣ��ʹ֮���������磺�ڿ���Դ�����ױ�ʶ��URL���е�ֻ�����˲���ֵ����δ����������URL��ַ����Ҫ�����������ſɶ�λ����Դ����
(2) Ϊ��ֵ�ֶ����ú��ʵ�ֵ�����ڿ����ݼ�¼���е���д������ֵ���е�û����д����δ��д����Ҫ���䡣
(3) �������ֶεķ�ʽ���Ӷ������Ϣ��������Դʱ���������е�����Դ���ܱ�֤������������Ҫ���ֶΡ�����������£�����ΪijЩȱ�ٵ�����Դ�����ֶ��Ա���������Ϣ�������ԡ����磺�ڿ���Դ����Դ���͡���Դ�����ʱ����ֶΡ�
2 �ظ���¼�鲢
�ظ���¼��ָ����������������ͬ�ģ�Ҳ����˵������ָ������ʵ������ͬһʵ�壬������֮�������һЩ��ͬ���������ԣ���ռ���˿ռ䣬Ҳ�����������ɼ�¼�������ࡣ
Ϊ�˴����ݼ��м�Ⲣ�鲢�ظ���¼����Ҫ����������ж�2����¼�Ƿ����ظ��ġ���ɿ��ļ���ظ���¼�İ취�DZȽ����ݿ���ÿ�Լ�¼��Ŀǰ�������õ��㷨�ǻ����ڽ�����(Basic sorted- neighborhood method��SNM)�������㷨ʱ�临�Ӷȴ���Ҫ����N(N-1)/2�αȽ�(���У�N�����ݿ��м�¼������)������-�ϲ������Ǽ�����ݿ�����ȫ�ظ���¼�ı�����[6]�����Ļ���˼���ǣ��ȶ����ݼ�����Ȼ�Ƚ����ڼ�¼�Ƿ����ơ���һ����ҲΪ���������ݿ⼶�ϼ���ظ���¼�ṩ��˼·��Ŀǰ�����еļ���ظ���¼�ķ���Ҳ����Դ�˼��Ϊ�������� ��[7]���ִ���ظ���¼���������Ҫ�ǻ��ڱ��ļ����ȫ��ͬ��2����¼�ķ���[8]��Hernandez��[9]����ڲ�ͬ�ļ��϶�������ֱ�����ڽ���¼�����ƶȣ�����ۺ϶�μ���Ľ����ɼ�¼ƥ����̡�����[10]����ɱ��ƶ����ڣ��Բ�ͬ���Ե���Ҫ�����ò�ͬȨֵ�����������ƶȾ��������ظ���¼����Խ���[11]���һ�ֻ���N-Gram�ľ����㷨���ڼ���ͬʱ���Զ�У�����ʵIJ��롢ɾ���������⾫�ȣ�Monge��[12-13]�Ƚ��������м�¼����Ȼ��ʹ�ð���һ������Ⱥ��cluster�����ȶ��а�˳��ɨ�����е������¼����̬�ؽ����Ǿ��ࡣKukich��[14-15]�����û�����ļ�ֵ�����ű���¼�������û��������ԳɶԵķ�ʽ(pair-wise)�Ƚϴ����ڵļ�¼��
2.1 �����ڽ������㷨
2.1.1 �㷨����
����1 ��������ؼ��֡���ȡ��¼���Ե�һ���Ӽ����л�����ֵ���Ӵ����������ݼ���ÿһ����¼�ļ�ֵ��
����2 �����ݸ�����ؼ��ֶ��������ݼ������������ܵ�ʹDZ�ڵĿ��ܵ��ظ���¼������һ���ڽ��������ڣ��Ӷ������ض��ļ�¼���Խ����м�¼ƥ��Ķ���������һ���ķ�Χ֮�ڡ�
����3 �ϲ��������������ݼ��ϻ���һ���̶���С�Ĵ��ڣ����ݼ���ÿ����¼���봰���ڵļ�¼���бȽϡ����ڵĴ�СΪW����¼����ÿ���½��봰�ڵļ�¼��Ҫ����ǰ���봰�ڵ�W-1����¼���бȽ�������ظ���¼�����Ƚ��봰���ڵļ�¼�������ڣ����һ����¼����һ����¼���봰�ڣ��ٰѴ�W����¼��Ϊ��һ�ֱȽ϶���ͼ3��ʾΪSNM�������ݼ�ʾ��ͼ��

ͼ3 SNM�������ݼ�ʾ��ͼ
Fig.3 Schematic diagram of SNM method
SNM�㷨���û������ڵķ�����ÿ�ο���ֻ�Ƚϴ����е�W����¼�������ƥ��Ч�ʣ����û�������Ҳ���������˱Ƚ��ٶȣ�ֻ��Ҫ����W��N�αȽϣ���Ȼ��W��NС�öࡣ���ǣ�SNM������������ȱ��[10]��(1) ������ؼ��ֵ������Դ�(2) �������ڵĴ�СW��ѡȡ���ѿ��ơ�
2.1.2 �����ڽ������㷨���Ż�˼��
���SNM�㷨��ȱ�㣬�Դ�ͳSNM�����е�ȱ�ݽ������¸Ľ�[16]��
(1) ����ؼ���Ԥ��������Դ�ͳ��SNM����������ؼ����д���������ԣ��ڸ���ѡȡ������ؼ��ֶ����ݼ���������֮ǰ���ȶ������Ԥ�����������ⲿԴ�ļ���������ؼ����еĴ���ͳһ���ݸ�ʽ��
(2) ѡ��ͬ�Ĺؼ���ִ�ж����ڽ�����ÿ���ڽ�����ѡ��ͬ�Ĺؼ��֡�
(3) �����ƶ��ٶȺʹ�С�������������������ڵķ�����ʹ���ڼ�¼�ıȽϹ����У������ƶ��Ĵ�С���ٶȿ�����һ���ķ�Χ�ڸ������ƹ�ģ���е�����
2.1.3 �Ż��㷨
�㷨�IJ�����2����������СֵW1���������ֵW2���㷨����Ҫ������3�������������Ƽ�¼��Match_num���ƶ��ٶ�v�͵�ǰ���ڴ�СWi��
ÿ�δ��ڵĴ�СWiΪ��
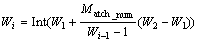 (1)
(1)
Wi�����У����Ƽ�¼����Match_num��ȡֵΪ0��1��2������Wi-1����ʽ(1)�У����Ƽ�¼Խ�࣬����Խ�����Ƽ�¼ΪWi-1��ʱ���������ΪW2����û�����Ƽ�¼ʱ��������СΪW1��ÿ�δ����ƶ����ٶ�viΪ��
 (2)
(2)
�����ƶ��ٶ�vi�����Ե��ٶȱ仯�������������Ƽ�¼��ʱ���ƶ��ٶ�С����ȫ������ʱ���ƶ��ٶ�Ϊ1�������Ƽ�¼Խ��ʱ���ƶ��ٶ�Խ����û�����Ƽ�¼ʱ���ƶ��ٶ�Ϊvi��
2.1.4 �ظ���¼��ϴ�㷨Ч�ʶ�����
�����ظ���¼����㷨Ч�ʵı����㷨�Ƿ��ܰ����ݼ��д��ڵ������ظ���¼�������������õı���Ҫ�У��ٻ���(Recall)����ʶ����(False)[17]��
(1) �л���(Recall)������Ϊ���ظ���¼����㷨��ȷʶ������ظ���¼ռ���ݼ�ʵ�ʰ������ظ���¼���ٷֱȡ�
������7����¼{X1, X2, X3, Y1, Y2, Y3, Z1}������{X1, X2, X3}��{Y1, Y2, Y3}�ֱ��Ǽ�¼X��Y���ظ���¼��ͨ��һ��������ϴ�Ĺ���ʶ���{X1, X2, Z1}��{Y1, Y2}���ظ���¼������Recall=(4/6)��100%=66.67%��
(2) ��ʶ����(False)������Ϊ���ظ���¼����㷨�����ʶ��Ϊ�ظ���¼����Ŀռ���㷨ʶ��Ϊ�ظ���¼�����İٷֱȡ���ʶ����Խ�ͣ������㷨��������ŶȾ�Խ�ߡ�
������������У�����㷨����ذ�Z1ʶ��Ϊ1���ظ���¼������False=(1/5)��100%=20%��
3 ʵ�鷽������
ʵ���������õ����ݼ��ǿ��﹤�̻������е�50���ڿ���2 000��������¼��ÿ����¼��23�����ԣ��������1��ʾ����ϴǰ����ϴ�����������ļ�¼�������2��ʾ��
SNM����SNM�Ż��㷨������ͬһ���㻷������������¼���ظ���¼�㷨Ч�ʵĽ�����3��ʾ���ӱ�3���Կ�����������֮ǰ������ؼ��ֽ���Ԥ�������Լ����ô�С���ٶȱ仯���ڵ�SNM�Ż��㷨��Ч����Ҫ���ڴ�ͳ��SNM�㷨�����ڲ����˴��ڵĴ�С���ƶ��ٶȿɱ�ļ�����ִ��ʱ�����Աȴ�ͳSNM�㷨�٣����йؼ���Ԥ�������л���������ߣ���ʶ���ʵõ����͡�
��1 �ڿ�Ԫ������Ϣ
Table 1 Metadata information of journal
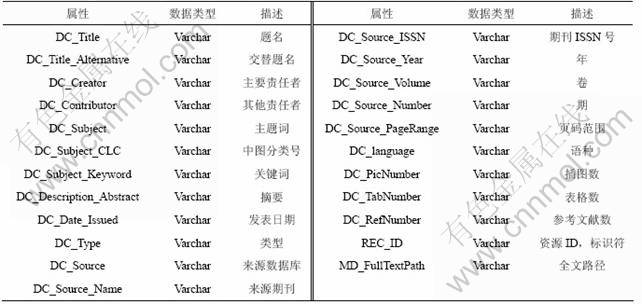
��2 ������ϴ�еIJ��֡������ݡ�ʵ��
Table 2 Partly dirty data examples of journal at data cleaning
��3 SNM���Ż�SNM�㷨Ч�ʵıȽ�
Table 3 Comparison of efficiency of SNM and improved SNM algorithm

4 �������������
(1) ���ݱ������⣺�����еķ���ʱ�����Ϊ2007.12.10���е�ʱ�����Ϊ2007-1-11��20071015�ȣ�����Ҫͳһ���ڱ��ָ�ʽ������ִ�����ݵı��������������ʹ��YYYY-MM-DD��Ϊ��ϴ������ڸ�ʽ���������ֶΣ�������ʽ��CN�����ĺ�CHN������ִ�б���������ͳһ��ʽΪCN��������ISSN�ŷָ����IJ�һ�¡�2�����ֵ������ֶ����пո��ڵ��ַ���λ����ͬ�ȣ���Щ����Ҫ���б���������
(2) ���ݽ������⣺�Ծ��ж����ߵ��ڿ�������˵����Ҫ����1���������������߷ֽ⣬���ڲ�ͬ���ֶ��У����ǣ������Ҫ���ݽ������̡�
(3) ������ǿ���⣺������ͬ������һЩ��ȱ���ֶΣ��������֡���Դ���͡���Դ�����ʱ��ȣ�����ʹ��������ǿ�������������Щ���⡣
(4) ��¼�鲢���⣺����Щ��¼�У����ڡ�ͭ����ϸ��������������ƪ���Ĵ���2����¼������Ϊͬһ���ֶ�����Ҫִ���ظ���¼�鲢�IJ����������ظ���
ͨ��������ϴ����Զ����ϴ���̰��չ�����������ϴ������ϴǰ���ݱȽϣ���ϴ������������˴ֵĴ������ݣ��Ӷ���֤�����ݿ�������
5 ����
(1) ������������ϴ��4�����̺���ϴ���̣����ݱ��������ݽ�����������ǿ���ظ����ݹ鲢�������������ϴ����Ķ��塣�����ݱ������ڵ�������з�������ȡ���ݱ��������ݽ�����������ǿ�������������������
(2) ������SNM�㷨��ָ�����ڵ�ȱ�ݣ�һ�Ǵ��ڵĴ�Сѡȡ�Խ��Ӱ��ܴ��Ƕ�����ؼ��ֵ������Դ�Ӱ����ƥ���Ч���뾫�ȡ�
(3) ��ȡ����ؼ���Ԥ������ѡ��ͬ�Ĺؼ���ִ�ж����ڽ������Լ������ƶ��ٶȺʹ�С�������ȷ����������SNM�Ż��㷨��
(4) ֤�����Ż���SNM�㷨���ڴ�ͳ��SNM�㷨����Ч�����������������Ŀǰ���÷�������ʵ���еõ�Ӧ�á�
�ο����ף�
[1] �й��ߵȽ������ױ���ϵͳ��������. �й��ߵȽ�������ͼ��ݼ�������淶[M]. ����: �й��ߵȽ������ױ���ϵͳ, 2004: 312-315.
Administrative Center for China Academic Library and Information System. China academic digital library and information system technical standards and specifications[M]. Beijing: China Academic Library and Information System, 2004: 312-315.
[2] ��֥��, �ܰ�Ӣ. ����������������ϴ�о�����[J]. ����ѧ��, 2002, 13(11): 2076-2082.
GUO Zhi-mao, ZHOU Ao-ying. Research on data quality and data cleaning: A survey[J]. Journal of Software, 2002, 13(11): 2076-2082.
[3] ����, ��·��, ��Ծ, ��. ����XML ���ݿ������������ϴ����[J]. ���������, 2008, 34(16): 16-17.
LIU Bo, YANG Lu-ming, LEI Gang-yue, et al. Intelligence data cleaning strategy for XML database[J]. Computer Engineering, 2008, 34(16): 16-17.
[4] Rahm E, Do H H. Data cleaning: Problems and current approaches[J]. IEEE Data Engineering Bulletin, 2000, 23(4): 3-13.
[5] Raman V, Hellerstein J M. Potter��s Wheel: An interactive data cleaning system[C]//Proceedings of the 27th VLDB Conference. San Francisco: Morgan Kaufmann Publishers Inc, 2001: 100-109.
[6] Bitton D, DeWitt D J. Duplicate record elimination in large data files[J]. ACM Transactions on Database Systems, 1983, 8(2): 255-265.
[7] Hernandez M A, Stolfo S J. Real-world data is dirty: data cleansing and the merge/purge problem[J]. Journal of Data Mining and Knowledge Discovery, 1998, 2(1): 9-37.
[8] QIU Yue-feng, TIAN Zong-ping, JI Wen-yun, et al. An efficient approach for detecting approximately duplicate database records[J]. Chinese Journal of Computers, 2001, 24(1): 69-77.
[9] Hernandez M A, Stolfo S J. Real-World data is dirty: Data cleansing and the merge/purge problem[J]. Data Mining and Knowledge Discovery, 1998, 2(1): 9-37.
[10] ���, ֣��. �Ի���MPN������ϴ�㷨�ĸĽ�[J]. �����Ӧ��������, 2008, 25(2): 245-246.
LI Jian, ZHENG Ning. Improvement on the algorithm of data cleaning based on MPN[J]. Computer Applications and Software, 2008, 25(2): 245-246.
[11] ��Խ��, ����ƽ, �����S, ��. һ�ָ�Ч�ļ�������ظ���¼�ķ���[J]. �����ѧ��, 2001, 24(1): 69-77.
QIU Yue-feng, TIAN Zeng-ping, JI Wen-yun, et al. An efficient approach for detecting approximately duplicate database records[J]. Chinese Journal of Computers, 2001, 24(1): 69-77.
[12] Monge A E. Matching algorithm within a duplicate detection system[J]. IEEE Data Engineering Bulletin, 2000, 23(4): 14-20.
[13] Monge A E, Elkan C P. An efficient domain-independent algorithm for detecting approximately duplicate database records[C]//Proceeding of the ACM-SIGMOD Workshop on Data Mining and Knowledge Discovery. Tucson: ACM, 1997: 23-29.
[14] Kukich K. Techniques for automatically correcting words in text[J]. ACM Computing Surveys, 1992, 24(4): 377-439
[15] Hernandez M, Stolfo S. The Merge/Purge problem for large databases[C]//Proceeding of ACM SIGMOD International Conference on Management of Data. Boston: ACM, 1995: 127-138.
[16] �Ž���. ������Դ��������Ի������йؼ������о�[D]. ��ɳ: ���ϴ�ѧ��Ϣ��ѧ�빤��ѧԺ, 2008: 43-45.
ZHANG Jian-zhong. A study of the key technology for digital library resource integration and personalized services[D]. Changsha: Central South University. School of Information Science and Engineering, 2008: 43-45.
[17] Lee M L, Ling T W, Low W L. IntelliClean: A knowledge-based intelligent data cleaner[C]//Proceedings of the 6th ACM SIGKDD International Conference on Knowledge Discovery and Data Ming. Boston: ACM Press, 2000: 290-294.
(�༭ ����ɭ)
�ո����ڣ�2009-11-15�������ڣ�2010-03-02
������Ŀ��������Ȼ��ѧ����������Ŀ(50874119)
ͨ�����ߣ��Ž���(1955-)���У��ӱ��żҿ��ˣ���ʿ�����ڣ����������ھ���Ϣ�����о����绰��0731-88836750��E-mail: jzzhang@mail.csu.edu.cn

