»щУЪҙЦІЪјҜҪөО¬әНПа№ШПтБҝ»ъөДіӨЖЪУГөзРиЗуФӨІв·Ҫ·Ё
№щПюЕф1Ј¬СоКзПј1Ј¬СоАп2
(1. »ӘұұөзБҰҙуС§ ҫӯјГУл№ЬАнС§ФәЈ¬ұұҫ©Ј¬102206Ј»
2. ёЈҪЁКЎөзБҰҝЖС§СРҫҝФәЈ¬ёЈҪЁ ёЈЦЭЈ¬350007)
ХӘТӘЈәМбіц»щУЪҙЦІЪјҜҪөО¬өДПа№ШПтБҝ»ъУГөзБҝФӨІвДЈРНЎЈСЎИЎ1996ЎӘ2010Дкұұҫ©КРөДGDPЧчОӘКдИлЦөЈ¬¶ФУҰөДИ«Йз»бУГөзБҝЧчОӘКдіцЦөҪшРР·ЦОцСйЦӨЎЈСРҫҝҪб№ыұнГчЈәПа№ШПтБҝ»ъКЗТ»ЦЦРВөДја¶ҪС§П°·Ҫ·ЁЈ¬УлЦ§іЦПтБҝ»ъПаұИЈ¬ЛьёьјУПЎКиЈ¬·ә»ҜДЬБҰёьЗҝЗТІ»РиТӘЙиЦГіН·ЈТтЧУЈ¬¶шҙЦІЪјҜҪөО¬ұ»УГУЪҙУ¶аёцПа№ШТтЛШЦРЙёСЎіцККУГУЪRVM»Ш№йДЈРНөДКдИлПтБҝјҜЈ¬Ҫш¶шМбёЯЛг·ЁР§ВКЈ»»щУЪПа№ШПтБҝ»ъөДУГөзБҝФӨІвДЈРНұИҫӯ№эУЕ»ҜІОКэәуөДЦ§іЦПтБҝ»ъФӨІвДЈРНёьУЕЎЈ
№ШјьҙКЈәҙЦІЪјҜЈ»Па№ШПтБҝ»ъЈ»RVM»Ш№йДЈРНЈ»ФӨІвЈ»УГөзРиЗу
ЦРНј·ЦАаәЕЈәTU457Ј»TU413.6 ОДПЧұкЦҫВлЈәA ОДХВұаәЕЈә1672-7207(2013)12-5133-06
Long-term electricity demand forecasting method based on rough set reduction and relevance vector machine
GUO Xiaopeng1, YANG Shuxia1, YANG Li2
(1. School of Economics and Management, North China Electric Power University, Beijing 102206, China;
2. Fujian Electric Power Research Institute, Fuzhou 350007, China)
Abstract: The electricity demand forecasting model based on the rough set and relevance vector machine was studied. To verify the validity of the model, the GDP and the electricity consumption data of Beijing from 1996 to 2010 were selected and analyzed with the GDP data was selected as input data, and the electricity consumption data used as output data. The results show that the relevance vector machine is a new supervising learning method. Compared with the support vector machine, it is sparser, with more generalization abilities and does not need to set the penalty factor. Rough set reduction is used to filter out the input vector for RVM regression model from a number of related factors, thus improving the efficiency of the algorithm. The electricity demand forecasting model based on the relevance vector machine is better than the support vector machine prediction model based on particle swarm optimization parameters.
Key words: rough set; relevance vector machine; RVM regression model; forecasting; electricity demand
УГөзБҝУліЗКРЎўөШЗшәН№ъјТөДҫӯјГ·ўХ№ГЬЗРПа№ШЈ¬ЧчәГУГөзБҝФӨІв¶ФөзБҰ№ж»®ЎўФЛРРөч¶Иј°өзБҰКРіЎҪ»ТЧөИ·ҪГжҫЯУРЦШТӘЦёөјЧчУГЎЈҪьДкАҙЈ¬УлУГөзБҝРиЗуәНөзБҰёәәЙөИПа№ШөДФӨІв·Ҫ·Ё¶ајҜЦРУЪЦЗДЬЛг·Ё·ҪГжЈ¬ИзҪ«BPЙсҫӯНшВзУлВн¶ыҝЖ·тБҙПаҪбәПФӨІвЦР№ъөзБҰРиЗу[1]Ј¬ЧйәПGM(1Ј¬1)әНЦ§іЦПтБҝ»ъ(support vector machineЈ¬јтіЖSVM)өДөзБҝФӨІвДЈРН[2]ТФј°Ҫ«ҙЦІЪјҜәНSVMЧйәПУҰУГҪшРРөзБҰРиЗуФӨІвөДДЈРН[3]ҫщҫЯУРҪПәГөДіЙ№ыЎЈФЪөзБҰёәәЙФӨІв·ҪГжЈ¬»щУЪБЈЧУИәУЕ»ҜBPЙсҫӯНшВз[4]ТФј°ҫӯ№э»мгзАнВЫәНБЈЧУИәУЕ»ҜөДЦ§іЦПтБҝ»ъ[5-7]өИФӨІвДЈРНР§№ыБјәГЎЈҙЛНвЈ¬НЁ№эТэИлТЕҙ«Лг·Ё»тБЈЧУИәУЕ»ҜЛг·ЁАҙёДҪшЦ§іЦПтБҝ»ъІОКэСЎФсөДФӨІвДЈРНДЬ№»УРР§өШёДҪшҙ«НіЦ§іЦПтБҝ»ъЛг·ЁИЭТЧПЭИлҫЦІҝј«ЦөЎў№эС§П°өИІ»ЧгЦ®ҙҰЈ¬ИЎөГБЛәЬәГөДР§№ы[6-7]ЎЈҪьДкАҙЈ¬Па№ШПтБҝ»ъ(relevance vector machineЈ¬јтіЖRVM)[8]УЙУЪҫЯУРІ»РиТӘ¶ФіН·ЈТтЧУҪшРРЙиЦГЎўёьјУПЎКиәН·ә»ҜДЬБҰёьЗҝөИУЕөг¶шКЬөҪ№ШЧўЈ¬ІўФЪөзБҰёәәЙФӨІв[9]·ҪГжИЎөГБЛҪПәГөДР§№ыЎЈФЪҪшРРіӨЖЪУГөзБҝФӨІвКұЈ¬РиТӘід·ЦҝјВЗөұөШөДGDPЎўҫУГсУГөзәНІъТөҪб№№өИ¶аёцТтЛШЎЈОӘБЛПыіэРЕПўИЯУаЈ¬ҫ«јтҪб№№Ј¬ИЎөГҪПәГөДФӨІвР§№ыЈ¬ұҫОДЧчХЯ№№ҪЁ»щУЪҙЦІЪјҜҪөО¬өДПа№ШПтБҝ»ъіӨЖЪУГөзБҝФӨІвДЈРНЈ¬ІўҪбәПҫЯМеөДКэҫЭҪшРР·ЦОцәНМҪМЦЎЈ
1 Па№ШПтБҝ»ъ»Ш№йФӨІвДЈРН
Па№ШПтБҝ»ъіЈУГУЪҪвҫц·ЦАаәН»Ш№йөИОКМвЎЈЖдЛг·ЁТАҫЭКЗФЪұҙТ¶Л№ҝтјЬПВҪшРР»Ш№й№АјЖ»сөГФӨІвЦөөД·ЦІјЈ¬ІўөГөҪ»щУЪәЛәҜКэөДПЎКиҪв[10]ЎЈRVMөДДЈРНСөБ·»щУЪҝмЛЩРтБРПЎКиұҙТ¶Л№С§П°Лг·ЁЈ¬СөБ·ЛЩ¶ИұИҪПҝм[11]Ј¬ДЬККУГУЪ¶аФӘ»Ш№йәН¶аАа·ЦАаөИОКМвЎЈ
АыУГRVMөДПЎКиұҙТ¶Л№»Ш№йДЈРНАҙЗуҪвөзБҝФӨІвОКМвЎЈјЩЙи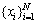 КЗСөБ·јҜөДКдИлЦөјҜәПЈ¬
КЗСөБ·јҜөДКдИлЦөјҜәПЈ¬ ОӘКдіцЦөјҜәПЈ¬ФтКдИлЦөәНДҝұкЦөЦ®јдөД¶ФУҰ№ШПөОӘ
ОӘКдіцЦөјҜәПЈ¬ФтКдИлЦөәНДҝұкЦөЦ®јдөД¶ФУҰ№ШПөОӘ
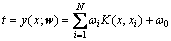 (1)
(1)
ЖдЦРЈәwОӘИЁЦШПтБҝЈ»K(xЈ¬xi)ОӘәЛәҜКэЈ»ҰШОӘ¶ФУҰөДИЁЦШЎЈУлSVMІ»Н¬өДКЗЈ¬RVM»№ТӘҙУёЕВКөДҪЗ¶Иіц·ўҝјВЗДҝұкЦөөДОуІоЎЈФЪПЎКиұҙТ¶Л№ҝтјЬАпЈ¬јЩ¶ЁХвёцОуІо·юҙУ¶АБўБгҫщЦөөДGauss·ЦІјЈ¬јҙ
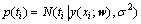 (2)
(2)
јЩЙиtiПа»Ҙ¶ФБўЈ¬ФтҝЙөГөҪСөБ·јҜ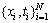 өДЛЖИ»№АјЖОӘ
өДЛЖИ»№АјЖОӘ
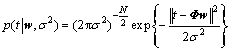 (3)
(3)
ЖдЦРЈә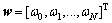 Ј»ҰөОӘУЙёчКдИлЦөҙъИләЛәҜКэЦ®әуРОіЙөДҫШХуЈ¬
Ј»ҰөОӘУЙёчКдИлЦөҙъИләЛәҜКэЦ®әуРОіЙөДҫШХуЈ¬
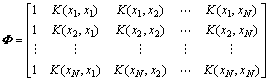
КҪ(3)ЦРөДІОКэҪП¶аЈ¬ИЭТЧПЭИл№эДвәПЎЈОӘБЛҪвҫцХвёцОКМвЈ¬ОӘИЁЦШПтБҝwёіУиБгҫщЦөGaussПИСй·ЦІјЈә
 (4)
(4)
ЖдЦРЈәҰБОӘN+1О¬өДі¬ІОКэ(hyper parameters)ПтБҝЎЈёщҫЭКҪ(4)јҙҝЙҪЁБўИЁЦШУлі¬ІОКэЦ®јдөДТ»Т»¶ФУҰ№ШПөАҙҝШЦЖПИСй·ЦІј¶Фі¬ІОКэөДУ°ПмЈ¬Ҫш¶шИ·ұЈRVMөДПЎКиРФЎЈ
ёщҫЭЗ°ГжөД·ЦІј№«КҪЈ¬ҪбәПұҙТ¶Л№ФӯАнЈ¬ҝЙөГіцІОКэөДәуСйёЕВК·ЦІјЈә

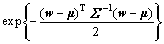 (5)
(5)
ЖдЦРЈә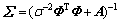 Ј»
Ј»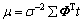 Ј»
Ј»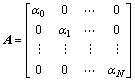 ЎЈ
ЎЈ
КҪ(5)ЦРРиТӘЗуөГҰБәНҰТ2өДЧоҝЙДЬ(most-probable)Ҫв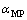 әН
әН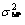 ЎЈҙУКҪ(5)ЗуИЎЧоҝЙДЬҪвөД№эіМұИҪПёҙФУЈ¬ЧоәГІЙУГКэЦөјЖЛгЦРөДөьҙъұЖҪьЛг·ЁАҙЗуИЎЧојСөДҪьЛЖЦөЈ¬јЖЛ㹫КҪОӘЈә
ЎЈҙУКҪ(5)ЗуИЎЧоҝЙДЬҪвөД№эіМұИҪПёҙФУЈ¬ЧоәГІЙУГКэЦөјЖЛгЦРөДөьҙъұЖҪьЛг·ЁАҙЗуИЎЧојСөДҪьЛЖЦөЈ¬јЖЛ㹫КҪОӘЈә
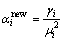 (6)
(6)
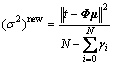 (7)
(7)
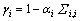 (8)
(8)
КҪЦРЈәҰМiОӘөЪiёцәуСйЖҪҫщИЁЈ»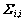 ОӘ
ОӘ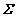 ҫШХуЦРөЪiПоФЪ¶ФҪЗПЯЙПөДФӘЛШЎЈИфёш¶ЁКдИлЦөxЈ¬ФтЖд¶ФУҰөДКдіцёЕВК·ЦІј·юҙУGauss·ЦІјЈә
ҫШХуЦРөЪiПоФЪ¶ФҪЗПЯЙПөДФӘЛШЎЈИфёш¶ЁКдИлЦөxЈ¬ФтЖд¶ФУҰөДКдіцёЕВК·ЦІј·юҙУGauss·ЦІјЈә
 (9)
(9)
ФӨІвЦөОӘ
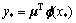 (10)
(10)
ЖдЦРЈә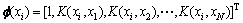 Ј¬ОӘҰөЦРөДөЪiРРПтБҝЎЈҙЛКұЈ¬ЗуөГөДy*јҙОӘt*өДФӨІвЦөЎЈ
Ј¬ОӘҰөЦРөДөЪiРРПтБҝЎЈҙЛКұЈ¬ЗуөГөДy*јҙОӘt*өДФӨІвЦөЎЈ
Па№ШПтБҝ»ъ»щУЪұҙТ¶Л№АнВЫөД»Ш№йФӨІв№эіМјыОДПЧ[8]ЎЈ
2 ҙЦІЪјҜҪөО¬
ҙЦјҜАнВЫУЙPawlakМбіцЈ¬КЗТ»ЦЦҙҰАнДЈәэәНІ»И·¶ЁЦӘК¶өДКэС§№ӨҫЯЈ¬УГУЪ·ЦОцәНҙҰАнІ»ҫ«И·ЎўІ»Т»ЦВ»тІ»НкХыөДРЕПўЈ¬ІўҪТКҫЗұФЪөД№жВЙЎЈ
НЁ№эҙЦІЪјҜАнВЫЙёСЎУГөзБҝРиЗуФӨІвЦёұкЈ¬ЖдұҫЦККЗФјИҘ¶аУаөД»тТвТеІ»ҙуөДЦёұкТтЛШЈ¬Н¬КұұЈБф¶ФФӨІвУРЦШТӘУ°ПмөДЦёұкЈ¬јҙұЈБфҙЦІЪјҜөДәЛјҜЈ¬Хвёц№эіМКөЦКЙПКЗЗуөГФӨІвЦёұкјҜөДЧојС№йФјјҜ[11-12]ЎЈ
КфРФ№йФјКЗЦёјЩЙиКфРФ КЗCөДТ»ёц№йФј,өұЗТҪцөұPOSB(D)=POSc(D)КұЈ¬BЦРөДГҝёцКфРФ¶ФУЪD¶јКЗІ»ҝЙИұЙЩөДЎЈКфРФ№йФјјЗОӘred(BЈ¬D)Ј¬ЖдІҪЦиОӘЈәКЧПИЈ¬ЗуіцКфРФ№йФјјҜөДәЛРДЈ»И»әуЈ¬ФЛУГ№йФјЛг·ЁјЖЛг№йФјјҜ,ІўёщҫЭДіЦЦЖАЕРұкЧјИ·¶ЁЧојС№йФјјҜЎЈ
КЗCөДТ»ёц№йФј,өұЗТҪцөұPOSB(D)=POSc(D)КұЈ¬BЦРөДГҝёцКфРФ¶ФУЪD¶јКЗІ»ҝЙИұЙЩөДЎЈКфРФ№йФјјЗОӘred(BЈ¬D)Ј¬ЖдІҪЦиОӘЈәКЧПИЈ¬ЗуіцКфРФ№йФјјҜөДәЛРДЈ»И»әуЈ¬ФЛУГ№йФјЛг·ЁјЖЛг№йФјјҜ,ІўёщҫЭДіЦЦЖАЕРұкЧјИ·¶ЁЧојС№йФјјҜЎЈ
ёщҫЭМхјюКфРФC={c1Ј¬c2Ј¬ЎӯЈ¬cm}әНҫцІЯКфРФD={d1Ј¬d2Ј¬ЎӯЈ¬dm}ј°¶ФУҰөДЦөVЈ¬АҙјЖЛгёчМхјюКфРФ¶ФУЪҫцІЯКфРФөДЦШТӘРФЎЈЙиМхјюКфРФОӘci(i=1Ј¬2Ј¬ЎӯЈ¬m)Ј¬ҫцІЯКфРФОӘdj(j=1Ј¬2Ј¬ЎӯЈ¬n)Ј¬ФтҫцІЯКфРФdj¶ФУЪМхјюКфРФciөДПаТА¶ИОӘ
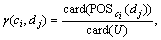 0ЎЬҰГ(ciЈ¬dj)ЎЬ1 (11)
0ЎЬҰГ(ciЈ¬dj)ЎЬ1 (11)
ЖдЦРЈә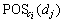 ОӘМхјюКфРФci¶ФУЪҫцІЯКфРФdjөДХэЗшЈ»card(ЎӨ)ОӘјЖЛгЗшУтөД»щЎЈЙиБнУР
ОӘМхјюКфРФci¶ФУЪҫцІЯКфРФdjөДХэЗшЈ»card(ЎӨ)ОӘјЖЛгЗшУтөД»щЎЈЙиБнУР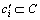 Ј¬Фт
Ј¬Фт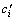 ¶ФУЪҫцІЯКфРФdjөДЦШТӘ¶ИSGFОӘ
¶ФУЪҫцІЯКфРФdjөДЦШТӘ¶ИSGFОӘ
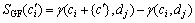 (12)
(12)
ёГЛг·ЁКЧПИјЖЛгГҝёцМхјюКфРФјҙёчУ°ПмТтЛШ¶ФУЪҫцІЯКфРФөДЦШТӘРФЈ¬ІўёщҫЭГҝёцМхјюКфРФөДЦШТӘРФЕЕРт,Іў°ҙЦШТӘРФҙУҙуөҪРЎҪ«МхјюКфРФТАҙОјУИлКфРФјҜredUЈ¬ІўҝјІмКфРФјҜredUУлҫцІЯКфРФЦ®јдөДТААөіМ¶ИЈ¬УЙҙЛКфРФјҜredUҪ«°ьә¬ЖрЦШТӘЧчУГөДМхјюКфРФЎЈИ»әуЈ¬ҙУКфРФјҜredUЦР°ҙЦШТӘРФҙУРЎөҪҙуҫщИҘөфКфРФЎЈИфИҘөфКфРФ»бФміЙТААө¶Иұд»Ҝ,Фт»ЦёҙёГКфРФЈ¬ЧоәуКЈПВөДКфРФјҜҫНКЗЧојС№йФјјҜЎЈ
3 ҙЦІЪјҜҪөО¬ј°Па№ШПтБҝ»ъ»Ш№йФӨІвөДБчіМ
ІЙУГҙЦІЪјҜҪөО¬әНRVMҪшРРФӨІвөД»щұҫҙҰАнБчіМИзПВЎЈ
Step 1 іхКј»ҜСөБ·јҜЎЈАэИзЈ¬¶ФКдИлЦөәНКдіцЦөҪшРРұкЧј»ҜҙҰАнЈ¬ТФФцҙуФӨІвөДҫ«¶ИЎЈ
Step 2 УГҙЦІЪјҜ·Ҫ·Ё¶ФҙҰАнәуөДКэҫЭјҜҪшРРҪөО¬Ј¬СЎФсЗЎөұөДПа№ШПтБҝЎЈ
Step 3 ЙиЦГҫ«¶ИТӘЗуЎўөьҙъҙОКэЎўі¬КұКұјдөИҝШЦЖІОКэЎЈ
Step 4 ёщҫЭСөБ·јҜКэҫЭҪшРРККУҰ¶ИС§П°Ј¬өГөҪИЁЦШПтБҝЎЈСөБ·№эіМТӘёщҫЭStep 2өДҝШЦЖІОКэАҙЕР¶ПКЗ·сВъЧгөьҙъЦРЦ№МхјюЎЈ
Step 5 ёщҫЭСөБ·өГөҪөДДЈРНЈ¬өГөҪФӨІвҪб№ыЎЈ
ҙЦІЪјҜҪөО¬ј°Па№ШПтБҝ»ъФӨІвБчіМИзНј1ЛщКҫЎЈ
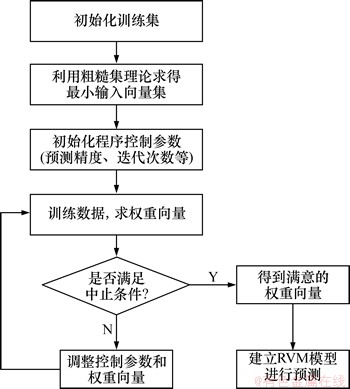
Нј1 ҙЦІЪјҜҪөО¬ј°Па№ШПтБҝ»ъФӨІвБчіМКҫТвНј
Fig. 1 Flow chart of RS-RVM forecasting model
4 КөАэ·ЦОц
ұҫОДЛщЙжј°өДФӨІв№эіМИ«ІҝІЙУГMatlabұаіМКөПЦЎЈФЪіМРтөДҫЯМеұаВлҙҰАн№эіМЦРЈ¬УлRVMПа№ШөДФӨІвЛг·ЁЦчТӘҪиЦъБЛSPARSEBAYES Matlab Toolbox 2.0[13]ЎЈ
БнНвЈ¬Ҫ«»щУЪҙЦІЪјҜҪөО¬өДRVMФӨІв·Ҫ·Ё(јтјЗОӘRVM)ЛщөГФӨІвҪб№ыУлSVM»Ш№йДЈРНөДФӨІвҪб№ыҪшРР¶ФұИЈ¬ЖдЦРSVMөДФӨІвЛг·ЁКөПЦҪиЦъБЛLibSVM[14]№ӨҫЯ°ьЎЈАыУГSVMДЈРНҪшРРФӨІвКұЈ¬ІОКэСЎФс¶ФЧоЦХөДҪб№ыУ°ПмҪПҙуЎЈОӘБЛұЬГвёщҫЭҫӯСйЦё¶ЁІОКэҝЙДЬөјЦВөДОуІоЈ¬УГБЈЧУИәУЕ»ҜЛг·Ё(particle swarm optimizationЈ¬PSO)СЎФсSVMІОКэЈ¬ІўФЪҙЛ»щҙЎЙП№№ҪЁSVMФӨІвДЈРНЈ¬ХвК№өГұҫОДЦРөДФӨІв·Ҫ·ЁУлSVMФӨІв·Ҫ·ЁЦ®јдөДФӨІвҪб№ы¶ФұИ·ЦОцёьУРКөјКТвТеЎЈ
4.1 ФӨІвКэҫЭөДСЎФсУлФӨҙҰАн
ұҫОДСЎИЎұұҫ©КР1996ЎӘ2010ДкИ«КРУГөзБҝј°ұұҫ©КРGDPЎўөЪТ»ІъТөЎўөЪ¶юІъТөЎўөЪИэІъТөЎўіЗПзҫУГсУГөзБҝұИАэөИКэҫЭјҜҪшРР·ЦОцЎЈКЧПИНЁ№эҙЦІЪјҜ¶ФПа№ШТтЧУҪөО¬Ј¬ЧоЦХСЎФсІЙУГGDPУлИ«Йз»бУГөзБҝҪшРР·ЦОцСйЦӨЎЈЖдЦРЈ¬GDPОӘRVMДЈРНЦРөДКдИлЦөЈ¬И«Йз»бУГөзБҝФтЧчОӘКдіцЦөЈ¬ХвСщЈ¬јҙҝЙҪЁБўGDPУлУГөзБҝЦ®јдөДRVM»Ш№йФӨІвДЈРНЎЈ
ұҫОДҙУЛщУРКэҫЭјҜЦРСЎИЎ1996ЎӘ2005ДкЛщ¶ФУҰөД2ЧйКэҫЭЧчОӘСөБ·КэҫЭЈ¬ҫЭҙЛҪшРРККУҰ¶ИСөБ·Ј¬ҙУ¶шҪЁБўRVMФӨІвДЈРНЎЈДЈРНҪЁБўәуЈ¬ФЩУГ2006ЎӘ2010ДкөДКэҫЭҪшРРФӨІвәНСйЦӨЎЈБнНвЈ¬ОӘБЛ»сөГЛг·ЁёьәГКХБІР§№ыЈ¬Ҫ«СөБ·Ҫб№ыәНФӨІвҪб№ыҪшРР[0Ј¬1]Ц®јдөД№йТ»»ҜФӨҙҰАнЎЈёГФӨҙҰАн№эіМОӘ
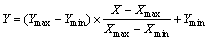
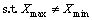 (13)
(13)
ЖдЦРЈәXОӘФӯКјКэҫЭјҜЈ»XmaxОӘФӯКјКэҫЭЦРөДЧоҙуЦөЈ»XminОӘФӯКјКэҫЭЦРөДЧоРЎЦөЈ»YОӘҙҰАнәуөДКэҫЭјҜЈ»YmaxОӘҙҰАнәуКэҫЭөДЧоҙуЦө(ИЎЦөОӘ1)Ј»YminОӘҙҰАнәуКэҫЭөДЧоРЎЦө(ИЎЦөОӘ-1)ЎЈөұXmax =XminКұЈ¬Y=XЎЈ
RVMДЈРНСөБ·КэҫЭЦ®әуЈ¬ҝЙөГөҪИзНј2әНұн1ЛщКҫөДДвәПҪб№ыЎЈ
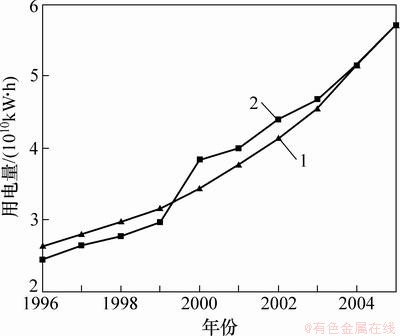
Нј2 RVMФӨІвДЈРНөДДвәПЗйҝц
Fig. 2 RVM forecasting modelЎҜs fitness chart
ұн1 RVMФӨІвДЈРНөДДвәПЗйҝц·ЦОц
Table 1 RVM forecasting model's fitness analysis
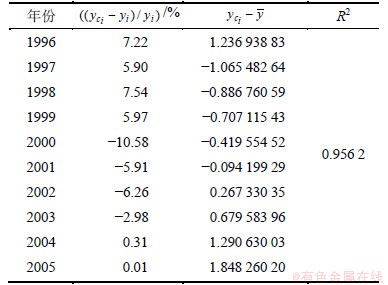
ұн1ЦРЈә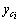 ОӘөЪiёцФӨІвЦөЈ»yiОӘөЪiёцКөјКЦөЈ»
ОӘөЪiёцФӨІвЦөЈ»yiОӘөЪiёцКөјКЦөЈ» ОӘКөјККэҫЭөДЖҪҫщЦөЎЈR2өДјЖЛ㹫КҪОӘ
ОӘКөјККэҫЭөДЖҪҫщЦөЎЈR2өДјЖЛ㹫КҪОӘ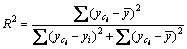 ЎЈУЙR2=0.956 2ҝЙЦӘЈ¬ұҫОДФӨІвДЈРНөДДвәПР§№ыәЬәГЎЈ
ЎЈУЙR2=0.956 2ҝЙЦӘЈ¬ұҫОДФӨІвДЈРНөДДвәПР§№ыәЬәГЎЈ
4.2 ФӨІвҪб№ы·ЦОц
ФӨІвНкіЙәуЈ¬ТӘ·ЦОцФӨІвҪб№ыУлКөјКҪб№ыЦ®јдөДОуІоЈ¬Н¬КұЈ¬»№ТӘ·ЦОцФӨІвҪб№ыөДҫщ·ҪёщПа¶ФОуІоyRMSREЈә
 (14)
(14)
ЖдЦРЈәОӘөЪiёцФӨІвЦөЈ»yiОӘ¶ФУҰөДөЪiёцКөјКЦөЎЈ
ұн2ЛщКҫОӘХжКөУГөзБҝЎўRVMФӨІвҪб№ыәН»щУЪPSOУЕ»ҜІОКэөДSVMФӨІвҪб№ыЈ¬Іў·ЦұрБРіцБЛёчЧФөДПа¶ФОуІоәНҫщ·ҪёщПа¶ФОуІоЎЈЖдЦРЈ¬Па¶ФОуІоәНҫщ·ҪёщПа¶ФОуІоКЗФӨІвР§№ыөДЦШТӘЖАјЫЦёұкЈ¬ЖдЦөФҪРЎЈ¬ФтДЈРНөДФӨІвР§№ыФҪәГЎЈ
ұн2 ұұҫ©КР2006ЎӘ2010ДкУГөзБҝј°ФӨІвҪб№ы·ЦОц
Table 2 Electricity consumption data and predicted results of Beijing from 1996 to 2010 1010kWЎӨh
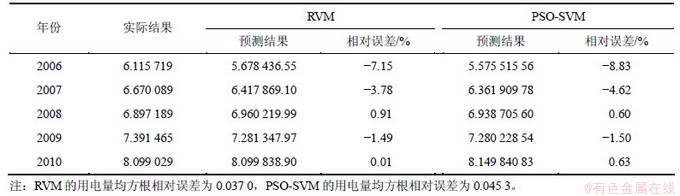
ФӯКјҪб№ыЎўRVMФӨІвҪб№ыәНPSO-SVMФӨІвҪб№ыөД¶ФұИИзНј3ЛщКҫЈ»RVMФӨІвОуІоәНPSO-SVMФӨІвОуІоЦ®јдөД¶ФұИИзНј4ЛщКҫЎЈ
ёщҫЭҫӯСйЈ¬Па¶ФОуІоөДҫш¶ФЦөРЎУЪ3%өДФӨІвҪб№ыКЗұИҪПАнПлөДЎЈУЙұн2ҝЙЦӘЈә»щУЪRVMәНPSO-SVMФӨІвДЈРНЛщІъЙъөД5ёцПа¶ФОуІоЦРЈ¬әу3ДкөД¶јРЎУЪ3%Ј»ФЪ2ёцФӨІвДЈРНЦРЈ¬іцПЦЧоҙуОуІоөДөгҫщОӘ2006ДкөДУГөзБҝЈ¬ЖдПа¶ФОуІо·ЦұрОӘ-7.15%әН-8.83%Ј»2007ДкөДФӨІвОуІоҪУҪь3%ЎЈХвұнГчRVMФӨІвДЈРНәНPSO-SVMДЈРНөДФӨІвР§№ы¶јұИҪПәГЎЈҫНұҫОДөДФӨІвҪб№ы¶шСФЈ¬RVMФӨІвДЈРНФЪФӨІвҫ«¶ИЙПВФұИPSO-SVMФӨІвДЈРНөДёЯ(RVMФӨІвөД5ёцФӨІвКэҫЭЦРЦ»УР1ёцОуІоұИPSO-SVMФӨІвДЈРНөДёЯЈ¬ө«ёГПа¶ФОуІоТІҪцОӘ0.91%)ЎЈ

Нј3 ФӯКјКэҫЭЎўRVMФӨІвҪб№ыәНPSO-SVMФӨІвҪб№ы¶ФХХНј
Fig. 3 Comparison among original results,RVM predicted results and PSO-SVM predicted results

Нј4 RVMФӨІвҪб№ыәНPSO-SVMФӨІвҪб№ыөДОуІо¶ФұИНј
Fig. 4 Comparison ofa predicted resultsЎҜ relative errors between RVM and PSO-SVM
ҙУҫщ·ҪёщПа¶ФОуІо(ұн2)ҝҙЈ¬RVMОӘ0.037 0Ј¬¶шPSO-SVMОӘ0.045 3Ј¬ФӨІвҪб№ы¶јұИҪПАнПлЎЈ°ҙХХұҫОДөДКФСйҪб№ыЈ¬RVMөДФӨІвР§№ыұИ PSO-SVMөДәГЎЈ
БнНвЈ¬ОҙҫӯУЕ»ҜөДSVMЛг·ЁФЪІОКэСЎФсЙПКЬҫӯСйУ°ПмҪПҙ󣬻бЦұҪУУ°ПмФӨІвҫ«¶ИЎЈИфІОКэСЎФсІ»өұЈ¬ФтФӨІвОуІо»бәЬҙуЎЈОӘБЛИЎөГЧоәГөДSVMФӨІвҪб№ыЈ¬ұҫОДІЙУГБЈЧУИәУЕ»ҜЛг·ЁАҙ»сИЎSVMФӨІвДЈРНөДЧојСІОКэЎЈҙУЛг·ЁКөПЦөДДСТЧіМ¶И¶шСФЈ¬RVMОҙУлЖдЛыЖф·ўКҪЛг·Ё»тЦЗДЬЛг·ЁПаҪбәПЈ¬ұаіМКөПЦҪПјтөҘЎЈ
5 ҪбВЫ
(1) RVM»Ш№йФӨІвДЈРН»щУЪұҙТ¶Л№ФӯАнЈ¬УлSVMПаұИёьОӘПЎКиЈ¬ЖдСөБ·Кұјдёь¶МЎЈБнНвЈ¬RVMҪшРР»Ш№йФӨІвКұЈ¬ОЮРи¶ФіН·ЈТтЧУҪшРРЙиЦГЈ¬ДЬУРР§ұЬГв№эС§П°өИОКМвЎЈRVMөДІОКэЙиЦГұИSVMёьјУјтөҘЈ¬ЖдЛг·ЁөДұаіМКөПЦёьјУјтҪаЎўЦұ№ЫЎЈ
(2) НЁ№эҙЦІЪјҜҪөО¬ҝЙЙёСЎіцКдИлПа№ШПтБҝЧојС№жФјјҜЈ¬ҙУ¶шФЪМбёЯRVMіӨЖЪУГөзБҝФӨІвДЈРНР§ВКөДН¬КұЈ¬ДЬ№»И·ұЈЖдФӨІвҫ«¶ИЎЈ
(3) ұҫОДІЙУГөДRVMФӨІвДЈРНФЪФӨІвУГөзБҝ·ҪГжҫЯУРБјәГөДР§№ыЈ¬ЖдФӨІвҫ«¶ИТІВФұИҫӯ№эPSOС°ІОУЕ»ҜәуөДSVMДЈРНёЯЈ¬ЦӨГчБЛRVMДЈРНөДУРР§РФЎЈ
(4) ұҫОДГ»УРЙжј°RVMДЈРНУлЖдЛыЦЗДЬЛг·ЁПаҪбәПөИ·ҪГжөДУЕ»ҜөИОКМвЎЈКВКөЙПЈ¬RVMФЪҙҰАнРЎСщұҫКэҫЭЦ®КұР§№ыҪПәГЈ¬ө«Йжј°ҙуБҝөДСөБ·КэҫЭКұҙҰАнРФДЬҪПІоЈ¬ХвР©ОКМвУРҙэҪшТ»ІҪСРҫҝЎЈ
ІОҝјОДПЧЈә
[1] LI Cunbin, WANG Kecheng. A new grey forecasting model based on BP neural network and Markov chain[J]. Journal of Central South University of Technology, 2007, 14(5): 713-718.
[2] ЛОПю»Ә, ЧжШ§¶р, ТБҫІ, өИ. »щУЪёДҪшGM(1,1)әНSVMөДіӨЖЪөзБҝУЕ»ҜЧйәПФӨІвДЈРН[J]. ЦРДПҙуѧѧұЁ: ЧФИ»ҝЖС§°ж, 2012, 43(5): 1803-1807.
SONG Xiaohua, ZU Pie, YI Jing, et al. An optimally combined forecast model for long-term power demand based on improved grey and SVM model[J]. Journal of Central South University: Science and Technology, 2012, 43(5): 1803-1807.
[3] YANG Shuxia, CAO Yuan, LIU Da, et al. RS-SVM forecasting model and power supply-demand forecast[J]. Journal of Central South University of Technology, 2011, 18(6): 2074-2079.
[4] ҙЮјӘ·е, ЖтҪЁС«, СоЙР¶«. »щУЪБЈЧУИәёДҪшBP ЙсҫӯНшВзөДЧйәПФӨІвДЈРНј°ЖдУҰУГ[J]. ЦРДПҙуѧѧұЁ: ЧФИ»ҝЖС§°ж, 2009, 40(1): 190-194.
CUI Jifeng, QI Jianxun, YANG Shangdong. Combined forecasting model based on BP improved by PSO and its application[J]. Journal of Central South University: Science and Technology, 2009, 40(1): 190-194.
[5] NIU Dongxiao, WANG Yongli, MA Xiaoyong. Optimization of support vector machine power load forecasting model based on data mining and Lyapunov exponents[J]. Journal of Central South University of Technology, 2010, 17(2): 406-412.
[6] HE Yongxiu, HE Haiying, WANG Yuejin, et al. Forecasting model of residential load based on general regression neural network and PSO-Bayes least squares support vector machine[J]. Journal of Central South University of Technology, 2011, 18(4): 1184-1192.
[7] LI Yanbin, ZHANG Ning, LI Cunbin. Support vector machine forecasting method improved by chaotic particle swarm optimization and its application[J]. Journal of Central South University of Technology, 2009, 16(3): 478-481.
[8] Tipping M E.Sparse Bayesian learning and the relevance vector machine[J].Journal of Machine Learning Research,2001, 13(1): 211-244.
[9] »ЖЛ§¶°, ОАЦҫЕ©, ёЯЧЪәН, өИ. »щУЪ·ЗёәҫШХу·ЦҪвөДПа№ШПтБҝ»ъ¶МЖЪёәәЙФӨІвДЈРН[J]. өзБҰПөНіЧФ¶Ҝ»Ҝ, 2012, 36(11): 62-66.
HUANG Shuaidong, WEI Zhinong, GAO Zonghe, et al. A short-term load forecasting model based on relevance vector machine with nonnegative matrix factorization[J]. Automation of Electric Power Systems, 2012, 36(11): 62-66.
[10] Со№ъЕф, ЦЬРА, УаРсіх. ПЎКиұҙТ¶Л№ДЈРНУлПа№ШПтБҝ»ъС§П°СРҫҝ[J]. јЖЛг»ъҝЖС§, 2010, 37(7): 225-228.
YANG Guopeng, ZHOU Xin, YU Xuchu. Research on sparse bayesian model and the relevance vector machine[J]. Computer Science, 2010, 37(7): 225-228.
[11] XIE Gang, ZHANG Jinlong, Lai K K, et al. Variable precision rough set for group decision-making: An application[J]. International Journal of Approximate Reasoning, 2008, 49(2): 331-343.
[12] QIAN Yuhua, LIANG Jiye, Pedrycz W, et al. Positive approximation: An accelerator for attribute reduction in rough set theory[J]. Artificial Intelligence, 2010, 174(9/10): 597-618.
[13] Tipping M E. Sparse Bayesian Models (& the RVM)[EB/OL]. [2013-11-14]. http://www.miketipping.com/sparsebayes.htm.
[14] Chang C C, Lin C J. LIBSVM: A library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3): 1-27.
(ұајӯ іВІУ»Ә)
КХёеИХЖЪЈә2012-12-03Ј»РЮ»ШИХЖЪЈә2013-03-02
»щҪрПоДҝЈә№ъјТЧФИ»ҝЖС§»щҪрЧКЦъПоДҝ(71071054)Ј»ЦРСлёЯРЈ»щұҫҝЖСРТөОс·СЧЁПоЧКҪрЧКЦъПоДҝ(11QR34)
НЁРЕЧчХЯЈә№щПюЕф(1979-)Ј¬ДРЈ¬әУДПјГФҙИЛЈ¬І©КҝЈ¬ҪІКҰЈ¬ҙУКВөзБҰҫӯјГөИ·ҪГжөДСРҫҝЈ»өз»°Јә13520328997Ј»E-mailЈәguoxp2004@gmail.com

