
J. Cent. South Univ. (2021) 28: 760-770
DOI: https://doi.org/10.1007/s11771-021-4643-8
Energy efficient virtual machine migration approach with SLA conservation in cloud computing
GARG Vaneet1, JINDAL Balkrishan2
1. Computer Science and Engineering Section, Punjabi University, Patiala 147002, India;
2. Computer Engineering Section, Yadvindra College of Engineering, Punjabi University, Guru Kashi Campus, Talwandi Sabo 151302, India
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2021
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2021
Abstract: In the age of online workload explosion, cloud users are increasing exponentialy. Therefore, large scale data centers are required in cloud environment that leads to high energy consumption. Hence, optimal resource utilization is essential to improve energy efficiency of cloud data center. Although, most of the existing literature focuses on virtual machine (VM) consolidation for increasing energy efficiency at the cost of service level agreement degradation. In order to improve the existing approaches, load aware three-gear THReshold (LATHR) as well as modified best fit decreasing (MBFD) algorithm is proposed for minimizing total energy consumption while improving the quality of service in terms of SLA. It offers promising results under dynamic workload and variable number of VMs (1-290) allocated on individual host. The outcomes of the proposed work are measured in terms of SLA, energy consumption, instruction energy ratio (IER) and the number of migrations against the varied numbers of VMs. From experimental results it has been concluded that the proposed technique reduced the SLA violations (55%, 26% and 39%) and energy consumption (17%, 12% and 6%) as compared to median absolute deviation (MAD), inter quartile range (IQR) and double threshold (THR) overload detection policies, respectively.
Key words: cloud computing; energy efficiency; three-gear threshold; resource allocation; service level agreement
Cite this article as: GARG Vaneet, JINDAL Balkrishan. Energy efficient virtual machine migration approach with SLA conservation in cloud computing [J]. Journal of Central South University, 2021, 28(3): 760-770. DOI: https://doi.org/10.1007/s11771-021-4643-8.
1 Introduction
Nowadays, cloud service providers are expanding their data centers as the numbers of cloud-based users are increasing day by day. It has been reported that the number of cloud users has increased from 1.1 billion cloud users in 2014 to 2 billion by 2019, where, more than 86% of tasks of IT workload will be performed in cloud data centers [1]. The increasing dependency on cloud services is augmenting the energy consumption, SLA violation, and emission of CO2 gases. In a survey, it has been reported that data centers at most consume 18% of total global energy used by information communication technology (ICT) and utilize 1.3% of worldwide generated electricity [2]. It is expected that energy consumption will increase by 8% in the future [3]. Additionally, to meet the growing demand, major cloud service providers, such as Microsoft Azure, Yahoo, IBM, Google, Alibaba, and other similar large enterprises, are expanding their data center��s support which makes cloud computing an energy-constrained system. It has outlined that servers are mostly underutilized as they only work up to 10% to 50% of their full capacity, hence wasting a lot of energy.
Therefore, virtualization technology is used to maximize resource utilization for improving the energy consumption of cloud data center (CDC) [4, 5]. This technology offers on-demand access to serve requested resources in the pay-as-you-use model [6, 7]. According to statistics, 40% of the data center��s total electricity is consumed by information technology (IT) devices [8]. Thus, the resource optimization in IT devices is most achievable by maximizing utilization of computational resources. Several studies have shown that servers in the idle state consume approximately 70% of their peak power [9, 10]. Therefore, it is not wise to leave the server running under little workload (below lower CPU threshold value). Hence, to reduce energy consumption, underutilized servers need to put on sleep mode by migrating its virtual machines (VMs).
Besides energy consumption constraints, service level agreement (SLA) between cloud service providers (CSPs) and cloud service users (CSUs) is equally important [11]. The unification and live migration of virtual machines dramatically reduces energy consumption at the cost of SLA violations. Thus, improving energy consumption is a significant challenge while maintaining SLA. Designing a data center with this unification approach is called VM consolidation.
The process of VM consolidation has been divided into four subsequent stages; 1) Detection of an overloaded host that may cause SLA violations; 2) Detection of an under loaded host that has to be switched to a power-saving mode for improving energy efficiency; 3) VM selection from an overloaded host; 4) VM-to-PM placement. The proposed work is focused on energy consumption and SLA violations, which has been achieved by optimizing the first and second sub-sequent stages of the VM consolidation process. Earlier, violation of the single upper CPU utilization threshold is widely used to resolve overload detection and VM placement issues [12-14]. This single threshold is not appropriate for the hosts of entire data center. The operational load of VMs and the number of allocated VMs operating on a host dynamically vary, which directly impacts the trade-off between energy consumption and SLA violations [15]. Thus, a strong statistical algorithm is needed to combat the unnecessary VM migration, which further dilutes contract between CSUs and CSPs. Therefore, in our algorithm a load aware upper CPU utilization threshold is opted for an individual host, to handle the dynamic workload.
The previous work has focused on adaptive and static thresholds with its own limitations and advantages. The major drawback of adaptive threshold scheme is that it has more VM migrations; as threshold level is defined on the basis of historical data, it will result in SLA degradations. On the other hand, in static schemes fixed threshold has been used for over loaded host detection, irrespective of historical as well as real time workload. The proposed work comprises of adaptive features as well as computational complexity of static system. The execution of proposed algorithm is compiled into two instances. In the first instance, average of CPU utilization is computed for VMs linked to an individual host; in the second instance, robust statistical method is incorporated for assigning particular gear to individual host, which is decision making phase. The optimal values of three gears as upper threshold trigger the process of VM consolidation to maximize resource utilization and control the VM migrations yields reduction in overall CDC��s energy consumption. Further, reduced number of VM migration helps to improve the SLA. The effectiveness of proposed scheme is evaluated through dynamic work load based simulations and shows an average improvement in service level agreement of 41%, number of migrations of 19% and energy savings of 11% as compared in terms of median absolute deviation (MAD), inter quartile range (IQR) and double threshold (THR) approaches. The following is the main contributions of this paper.
We propose LATHR algorithm to estimate upper CPU utilization threshold value for each host, which can effectively reduce the number of active hosts and VM migrations that lead to minimizing energy consumption as well as SLA violations.
We introduce load aware modified best fit decrease (MBFD) algorithm. This algorithm reduces the number of unneccesary VM migrations with optimal use of upper threshold and hence improves service level agreement.
Matlab tool kit is used to evaluate the performance and effectiveness of the LATHR algorithm with MAD, IQR, THR in the literature.
The rest of the paper is organized as follows. Highlights of the previous contribution in the field of cloud computing along with the challenging gaps and opportunities are discussed in Section 2. The proposed system model, terminology and total energy consumption of data center are explained in Section 3. The heuristic algorithm Load Aware three gear THReshold (LATHR) for overload host detection in the process of VM consolidation is described in Section 4. The simulation results and experimental setup of the proposed work is analyzed in Section 5. Finally, the performance of the proposed work is concluded in Section 6.
2 Related work
In the cloud data center, energy consumption is measured at the server��s CPU utilization level as energy consumption has a linear relation with CPU utilization [16]. For this reason, most of the related work focuses on virtualization technology to optimize computing resources in the data center. BELOGLAZOV et al [17] have revolutionized cloud computing by introducing the novel idea of VM consolidation by incorporating random selection (RS), maximum correlation (MC), and minimum migration time (MMT) algorithms to select migratable VMs from the overloaded host by adopting MAD, IQR and THR as overload detection policies. Further, the authors developed a modified best fit decreasing (MBFD) algorithm for VM placement. This approach is an NP-hard problem with three categories of load such as under load, overload, and normal load, and found a much time-consuming approach. Further, the work was carried out by ZHOU et al [18] and extended the load categories into four instances normal, critical, under load, and overload which reduces the VM migrations and enhances the SLA. In continuation of their previous work, the authors introduced adaptive threshold energy-aware (ATEA) algorithm where threshold value is calculated on the basis of K-means clustering [19]. This technique resolves the VM placement issues and reduces energy consumption as compared to the IQR, MAD, and THR policies.
Recently, YADAV et al [20] came up with a idea of adaptive gradient descent-based regression (Gdr) method, maximum correlation percentage (MCP) and bandwidth aware algorithm for host detection and VM selection respectively. A significant improvement was reported in terms of energy efficiency and SLA. The major drawback of this approach is that it is not suitable to tackle unnecessary migrations. Previously, reinforcement learning-based algorithms were introduced by CIOARA et al [21] to improve energy efficiency. This approach uses entropy and Euclidean distance to evaluate the greenness level while selecting the VMs for migration and compare the results to predefined threshold values to trigger the consolidation process.
A multi-agent distributed scheme for dynamic resource allocation was presented by MAZREKAJ et al [22]. Their work is better than the existing resource allocation schemes in terms of SLA violations. The other factors that can be incorporated into the proposed scheme are network traffic, security, and consideration of VM consolidation algorithms. A least medial square regression-based analysis called LmsReg heuristics algorithm to find over-utilized hosts has been proposed by YADAV et al [23] that reduces SLA violations with improved energy efficiency. A new aspect of fuzzy logic based energy saving consolidation scheme was introduced by MONIL et al [24] to predict the workload. In this work, the authors developed Mean, Mode, and Standard Deviation (MMSD) based adaptive threshold method. The fuzzy method was introduced for VM selection in terms of three statistical parameters (RAM, correlation, and standard deviation) to improve the energy efficiency by 8.5% while an 84% reduction in SLA was reported in the work. An automata-based host overutilization prediction method was developed by RANJBARI et al [25] where standard deviation and average of VMs are used to estimate the ascending (ASC) and descending (DESC) functions. Another overload and under load prediction method was introduced by HSIEH et al [26]. All the above cited papers have problems relating with real-time load estimation in the near future as the number of workloads changes dynamicly. To solve the above mention problems, we have adopted multiple upper thresholds for CDC instead of single upper CPU utilization threshold.
3 System models
The proposed work aims to minimize the overall energy consumption of the data center by optimizing the resources utilization while improving SLA. This section configures the cloud data center to define the problem definition.
3.1 Modelling of physical machines and VM requests
During the modelling N virtual machines denoted by V=(V1, V2, ��, VN) and M host machines denoted by H=(H1, H2, ��, HM) are considered in a cloud data center. The host Hh (1��h��M) is characterized by its processing capacity Ch, CPU utilization 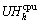 and power consumption PCh. The maximum CPU capacity Ch of host h is measured by million instructions per second (MIPS). Similarly each virtual machine Vv (1��v��N) is characterized by its CPU utilization
and power consumption PCh. The maximum CPU capacity Ch of host h is measured by million instructions per second (MIPS). Similarly each virtual machine Vv (1��v��N) is characterized by its CPU utilization  in MIPS as we only takes CPU utilization of VMs in our modelling.
in MIPS as we only takes CPU utilization of VMs in our modelling.
3.2 Modelling of energy consumption
Energy consumption by servers in the cloud data center is connected with CPU utilization. However, power distribution units as well as cooling systems also consume a major part of electricity. Therefore, the optimization of computational power without upgrading any hardware is the main concern of many researchers. Recent studies have shown that the server in idle state approximately consumes 70% of their peak power and has a linear relation with CPU utilization [27]. The mathematical linear relation of power consumption PCh of host h with host��s CPU utilizationis expressed in Eq. (1) [28, 29]. In the proposed experimental work the value of PCmax is set to 117 W as used in server HP G4 [26].

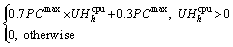 (1)
(1)
The CPU utilization may vary with time due to dynamic workload. Thus, host��s CPU utilization is a function of time  Therefore, the overall energy consumption (ECh) by the host can be represented as integral of power consumption over a period of time as shown in Eq. (2):
Therefore, the overall energy consumption (ECh) by the host can be represented as integral of power consumption over a period of time as shown in Eq. (2):
 (2)
(2)
whereas the total energy consumption (TEC) of data center for N virtual machines and M physical machines is represented by Eq. (3):
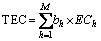 (3)
(3)
In the proposed method instruction energy ratio (IER) is used to estimate energy efficiency by the average number of executed instructions for a given amount of consumed energy in million instructions per joule (MIPJ), as shown in Eq. (4):
 (4)
(4)
It is noteworthy here that virtual machines only get a host when bh and avh are 1, where bh means that host h is active and avh means that virtual machine v is assigned to host h. The main objective of this study is to minimize TEC, maximize IER and reduce SLA violations.
4 Proposed work
A single threshold for all the servers in CDC solves the VM consolidation problem for improving either energy efficiency or SLA violations. But it is very challenging to cope up with both metrics. To embrace the strength of adaptive threshold and static threshold policies this paper proposes load aware three-gear threshold algorithm.
4.1 Load aware three-gear threshold
BELOGLEZOV et al [30] stated that the maximum threshold offers more energy-efficient VM consolidations at the cost of SLA violations. Whereas, VM consolidation with load based threshold is an effective method to improve energy efficiency while restricting unnecessary VM migrations. Therefore, a load aware three-gear threshold policy is proposed. The flowchart of the proposed LATHR approach is shown in Figure 1, where VMLh is defined as an average of allocated VMs on host h and Uthr1, Uthr2, Uthr3 are three threshold parameters defined in Eq. (9):
In this work, three upper CPU utilization thresholds, i.e., gear1, gear2 and gear3 are used. The allocation of particular gear to individual host depends on the conditions as shown in Eq. (5) and further derived from Eq. (9). In this policy, host supposed to be overloaded in successive iterations is restricted to gear1, in order to control further VM placements. Such placements result into unnecessary VM migrations, thus degrading the performance resulting into elevated SLA violations. On the other hand, host with a minimal number of excessively loaded VMs is assigned to gear3, which leads to the maximum utilization of resources, hence improving the energy efficiency. Rest normal loaded host is associated with gear2.

Figure 1 Flowchart of proposed technique (LATHR)
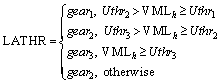 (5)
(5)
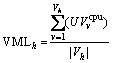 (6)
(6)
where Vh represents the list of virtual machines allocated to host h (Vh=Getvmlist(h)).
 (7)
(7)
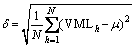 (8)
(8)
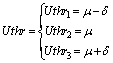 (9)
(9)
In the proposed work, flexibility of the VM consolidation process is based on average CPU utilization capacity of VMs served by each host discussed in algorithm 1.The proposed work is implememted using two instances. Initially, the the function of Lines 1-5 is to inspect an average load of VMs served by each host (VMLh) and then mean and variance are used to find three threshold parameters (Uthr1, Uthr2, Uthr3) as illustrated in Eq. (9). In the second instance, the function of Line 6 is to decide the gear in which the host will operate VM consolidation. If VMLh on the current host is greater than utilization threshold parameter Uthr3, then the host will work in high gear in order to maximize utilization of resources, as it will pertain a small number of heavily loaded VMs on it. If VMLh of a host is between Uthr2 and Uthr3, then the host is associated with middle gear; else, VMLh of a host is between Uthr1 and Uthr2, and then the host will work on gear1 to restrict the number of migrations in iterations. The pseudo-code of the proposed algorithm (LATHR) is shown in algorithm 1. The complexity of the LATHR algorithm is O(M+N) where M is the number of hosts and N is the number of virtual machines. The appropriate value of gears as the upper threshold is decided based on the series of experiments conducted in Section 5.
Algorithm 1: Load aware three-gear threshold

4.2 VM placement
A review of the widely used threshold policies revealed that THR in a static class and MAD, IQR in adaptive class are the existing methods for solving overload host detection problem, whereas, modified best fit decrease (MBFD) algorithm is applied to solve VM allocation problem. The process of VM placement is divided into two parts. In the first part VMs are allocated based on new requested resources by assuming 100% CPU utilization of the host. The first part can be modeled as a bin packing problem with variable bin sizes and the second part is to optimize allocated VMs. As discussed in algorithm 1, hosts are associated with proper gear that helps to detect over utilized hosts. Then one or more virtual machines from over utilized host and all VMs from an underutilized host are added into the migration list. Further, the migratable virtual machines are placed on one of the normal loaded host using load aware MBFD algorithm. It provides the least increase in power consumption to improve the energy efficiency and restrict the SLA violations. The pseudo-code of proposed load aware modified MBFD algorithm is as follows:
Algorithm 2: load aware modified best fit decrease algorithm

The function of Lines 6-7 is to calculate CPU utilization of active host after VM allocation. Line 8 keeps the host with normal load according to provided upper threshold. After_allo_energy(host, vm) function calculates energy consumption by host after VM allocation. The function of Lines 10-15 is to allocate VM to the host with the least increase in power consumption. The complexity of the load aware MBFD algorithm is O(M, N), where M is the number of hosts and N is the number of VMs that must be allocated.
5 Experiment and results
5.1 Setting of experiments
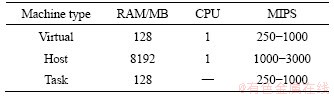
In this section, the experimental results of the proposed method are presented and discussed. In this work, computer-based simulation is designed in Matlab R2017a to perform the process of VM consolidation that includes data center, host machines, and virtual machines. The data center comprises of 100 host machines, and each node is modeled to have the maximum performance equivalent to 3��109 s-1, 128 MB of RAM and one core CPU. Requested tasks are served by 290 VM on the datacenter. Each VM can run any kind of application with adynamic workload. Tables 1 and 2 show the specification details of the hosts and virtual machines taken from the existing studies [4]. The data center has been simulated with 10 iterations for verification of results. The results are verified using SLA violations and energy consumption metrices. A well established analytical formulation of IER is discussed in Section 3.2. Another parameter like number of VM migrations related with SLA violation is also used for investigating the performance of the proposed method [17].
Table 1 Data center specifications

Table 2 Machine specifications
5.2 Optimal interval among three gears of LATHR
Considering the trade-off between energy efficiency and SLA violations, it is important to determine the optimal interval among values of three gears as upper threshold gear1, gear2 and gear3. A number of experiments have been conducted on the proposed algorithm to select optimal intervals between different gears as well as to obtain optimal value of gears. In the proposed method upper threshold 70% is consider base value described in Ref. [30]. In this method, difference between values of three gears is taken as multiple of 0.02, i.e., {0.02, 0.04, 0.06, 0.08, 0.10, 0.12, 0.14, 0.16, 0.18, 0.20, 0.22, 0.24, 0.26, 0.28, 0.30}. Thus, by taking the value of gerar2 0.7, the threshold value for gear3 belongs to (0.72, 0.74, 0.76, 0.78, 0.80, 0.82, 0.84, 0.86, 0.88, 0.90, 0.92, 0.94, 0.96, 0.98, 1.0} as well as the value of gear1 belongs to {0.68, 0.66, 0.64, 0.62, 0.60, 0.58, 0.56, 0.54, 0.52, 0.50, 0.48, 0.46, 0.44, 0.42, 0.40}.
Therefore, to find the optimal values of all the gears, we substituted the above said possible combinations for gear1 and gear3 on different values of gear2 with a gap of 5%. For example, gear2 is 0.75, and then threshold value of gear3 belongs to (0.77, 0.79, 0.81, 0.83, 0.85, 0.87, 0.89, 0.91, 0.93, 0.95, 0.97, 0.99} as well as the value of gear1 belongs to {0.73, 0.66, 0.64, 0.62, 0.60, 0.58, 0.56, 0.54, 0.52, 0.50, 0.48, 0.46, 0.44, 0.42, 0.40} and so on upto the value of gear2 1.
Energy consumption and SLA violations for all possible combinations are shown in Figures 2 and 3. From Figure 2 it has been concluded that energy consumption is inversely proportional to the gap and increased by 2%. From Figure 3 it has been concluded that SLA violations are increasing with the gap and increased by 2%. The outcomes are re-verified by implementing IER as depicted in Figure 4 with interval gap of 10% when gear2 is 70%.

Figure 2 Finding gap based on energy consumption
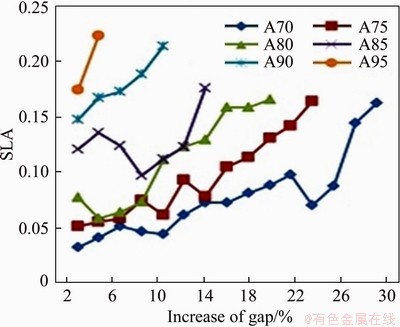
Figure 3 Finding gap based on SLA
5.3 Performance metrics and evaluation
The performance of the proposed method is compared with the existing techniques THR, MAD and IQR as shown in Figures 5-11.
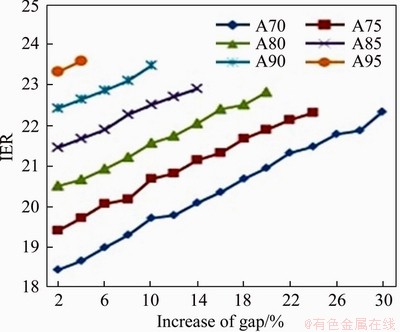
Figure 4 Finding gap based on IER

Figure 5 Idle hosts vs virtual machines
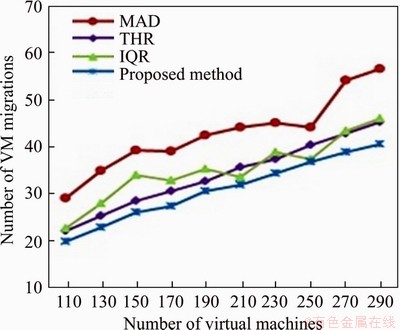
Figure 6 VM migrations vs virtual machines

Figure 7 Energy consumption vs virtual machines
The performance of the proposed method is compared with existing policies as shown in Figure 5 in terms of idle hosts over the varying number of virtual machines. From Figure 5 it has been concluded that the proposed approach outperforms with 8%, 5% and 3% less number of idle hosts as compared with the MAD, IQR and THR algorithms, respectively.
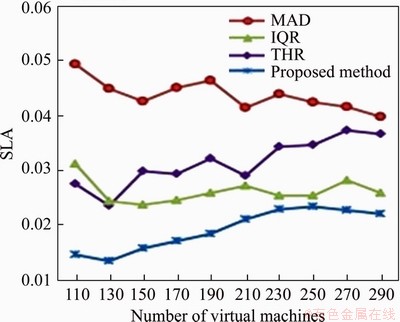
Figure 8 SLA violation for varying number of virtual machines
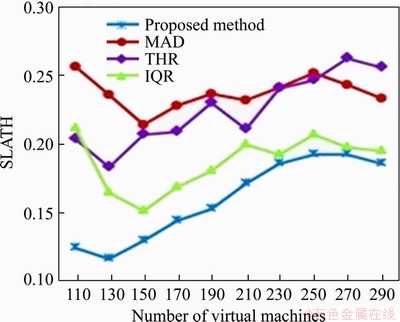
Figure 9 SLATH for varying virtual machines

Figure 10 PDM for varying virtual machines
From Figure 6, it has been concluded that the proposed algorithm has nearly 48%, 37% and 35% fewer migrations as compared with the MAD, IQR, and THR algorithms, respectively. It has been observed from Figures 5 and 6 that due to fewer migrations and idle hosts the proposed approach poses 17%, 12% and 6% less energy demand as compared with the MAD, IQR and THR algorithms respectively as shown in Figure 7.

Figure 11 Instruction energy ratio v/s virtual machines
Moreover, Figures 8 to 10 illustrate the comparison of the proposed method with other policies in terms of SLAV, SLATH, and PDM. From Figure 8, it has been concluded that the proposed approach outperforms with 56%, 26% and 39% fewer SLA violations as compared with the MAD, IQR and THR algorithms, respectively. From Figure 11, it has been interpreted that the proposed method provides a remarkable improvement of 23%, 16%, and 8% in instruction energy ratio as compared with the MAD, IQR and THR algorithms, respectively. Figure 12 shows the overall percentage improvement in the proposed method over the other existing techniques, as stated individually in Figures 5-11.
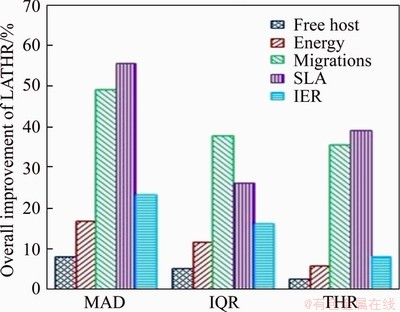
Figure 12 Percentage improvement in proposed algorithm compared to others
6 Conclusions
In this paper for the dynamic virtual machine consolidation, LATHR and modified MBFD algorithms are proposed based on mean and variance of VMs utilization allocated to an individual host. In this method three gears as upper threshold are used to detect overloaded hosts and optimal VM placement. The main objectives of the proposed method are to minimize unwanted VM migrations and the number of idle hosts to economize energy consumption while maintaining SLA violations. The proposed scheme prevents the host from overloading while consolidating the under-utilized servers to maximize idle nodes. The outcomes of the proposed method reveal a significant improvement in the number of migrations while preventing the hosts from experiencing 100% CPU utilization, hence offering better QoS. Subsequently, improvement in IER is also observed which makes it highly scalable. The proposed method is compared with the existing techniques MAD, IQR and THR in terms of the number of idle hosts, energy efficiency, IER, SLA violations and VM migrations. The reduction of 5.3% in the active hosts, 40.2% in SLA violations, and 11.4% improvement in the energy consumption in the proposed algorithm was compared with existing methods. The complexity of the proposed method LATHR is O(M+N). The performance of the proposed method is better than existing methods. The proposed technique may be used in future cloud industry. In future, the work will be extended in the same direction.
Contributors
GARG Vaneet developed and implemented the proposed algorithm in MATLAB and prepared the first draft of manuscript. JINDAL Balkrishan supervised the overall implementation of the proposed algorithm and analyzed the result section for the betterment of the manuscript.
Conflict of interest
GARG Vaneet and JINDAL Balkrishan declare that they have no conflict of interest.
References
[1] YADAV R, ZHANG W, CHEN H, GUO T. MuMs: Energy-aware VM selection scheme for cloud data center [C]// Proceedings of the 28th International Workshop on Database and Expert Systems Applications (DEXA). Lyon: 2017: 132-136.
[2] GELENBE E, LENT R. Optimising server energy consumption and response time [J]. Theoretical and Applied Informatics, 2013, 24(4): 257�C270.
[3] YADAV R, ZHANG W. MeReg: Managing energy-SLA tradeoff for green mobile cloud computing [C]// Wireless Communications and Mobile Computing. Hindawi, 2017: 6741972.
[4] SOLTANSHAHI M, ASEMI R, SHAFIEI N. Energy-aware virtual machines allocation by krill herd algorithm in cloud data centers [J]. Heliyon, 2019, 5(7): 1�C9.
[5] WAJID U, CAPPIELLO C, PLEBANI P, PERNICI B, MEHANDJIEV N, VITALI M. On achieving energy efficiency and reducing CO2 footprint in cloud computing [J]. IEEE Transactions on Cloud Computing, 2016, 4(2): 138�C151.
[6] MANVI SS, KRISHNA SHYAM G. Resource management for infrastructure as a service (IaaS) in cloud computing: A survey [J]. Journal of Network and Computer Applications, 2014, 41(1): 424�C440.
[7] HAMEED A, KHOSHKBARFOROUSHHA A, RANJAN R, JAYARAMAN PP, KOLODZIEJ J, BALAJI P. A survey and taxonomy on energy efficient resource allocation techniques for cloud computing systems [J]. Computing, 2016, 98(7): 751�C774.
[8] KLIAZOVICH D, BOUVRY P, KHAN S U. DENS: Data center energy-efficient network-aware scheduling [J]. Cluster Computing, 2013, 16(1): 65�C75.
[9] FAN X, WEBER W D, BARROSO L A. Power provisioning for a warehouse-sized computer [J]. ACM SIGARCH Computer Architecture News, 2007, 35(2): 1-13.
[10] SAADI Y, EL KAFHALI S. Energy-efficient strategy for virtual machine consolidation in cloud environment [J]. Soft Computing, 2020, 2(1): 1-10.
[11] ZHANG W, BAI E, HE H, CHENG A M K. Solving energy-aware real-time tasks scheduling problem with shuffled frog leaping algorithm on heterogeneous platforms [J]. Sensors, 2015, 15(6): 13778�C13804.
[12] WU L, GARG S K, BUYYA R. SLA-based resource allocation for software as a service provider (SaaS) in cloud computing environments [C]// Proceedings of the 11th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, CCGrid 2011. Newport Beach, CA, 2011: 195-204.
[13] HUANG C J, GUAN C T, CHEN H M, WANG Y W, CHANG S C, LI C Y. An adaptive resource management scheme in cloud computing [J]. Engineering Application of Artificial Intelligence, 2013, 26(1): 382�C389.
[14] ESFANDIARPOOR S, PAHLAVAN A, GOUDARZI M. Structure-aware online virtual machine consolidation for datacenter energy improvement in cloud computing [J]. Computers and Electrical Engineering, 2015, 42(6): 74-89.
[15] RUAN X, CHEN H, TIAN Y, YIN S. Virtual machine allocation and migration based on performance-to-power ratio in energy-efficient clouds [J]. Future Generation Computer Systems, 2019, 100: 380�C394.
[16] ALHARBI F, TIAN Y C, TANG M, ZHANG W Z, PENG C, FEI M. An ant colony system for energy-efficient dynamic virtual machine placement in data centers [J]. Expert Systems with Applications, 2019, 120: 228�C238.
[17] BELOGLAZOV A, BUYYA R. Optimal online deterministic algorithms and adaptive heuristics for energy and performance efficient dynamic consolidation of virtual machines in cloud data centers [J]. Concurrency Computation Practice Experience, 2012, 24(13): 1397�C1420.
[18] ZHOU Z, HU Z G, SONG T, YU J Y. A novel virtual machine deployment algorithm with energy efficiency in cloud computing [J]. Journal of Central South University, 2015, 22(3): 974-983.
[19] ZHOU Z, HU Z, LI K. Virtual machine placement algorithm for both energy-awareness and SLA violation reduction in cloud data centers [J]. Scientific Programming, 2016, 15: 1-11.
[20] YADAV R, ZHANG W, KAIWARTYA O, SINGH P R, ELGENDY I A, TIAN Y C. Adaptive energy-aware algorithms for minimizing energy consumption and SLA violation in cloud computing [J]. IEEE Access, 2018, 6: 55923-55936.
[21] CIOARA T, ANGHEL I, SALOMIE I, COPIL G, MOLDOVAN D, KIPP A. Energy aware dynamic resource consolidation algorithm for virtualized service centers based on reinforcement learning [C]// Proceedings of the 10th International Symposium on Parallel and Distributed Computing, ISPDC 2011 ClujNapoca, 2011: 163-169.
[22] MAZREKAJ A, MINAROLLI D, FREISLEBEN B. Distributed resource allocation in cloud computing using multi-agent systems [J]. Telfor Journal, 2017, 9(2): 110-115.
[23] YADAV R, ZHANG W, LI K, LIU C, SHAFIQ M, KARN NK. An adaptive heuristic for managing energy consumption and overloaded hosts in a cloud data center [J]. Wireless Networks, 2020, 26(3): 1905-1919.
[24] MONIL M A H, RAHMAN R M. VM consolidation approach based on heuristics fuzzy logic, and migration control [J]. Journal of Cloud Computing, 2016, 5(1): 1-18.
[25] RANJBARI M, AKBARI TORKESTANI J. A learning automata-based algorithm for energy and SLA efficient consolidation of virtual machines in cloud data centers [J]. Journal of Parallel Distributed Computing, 2018, 113(1): 55-62.
[26] HSIEH S Y, LIU C S, BUYYA R, ZOMAYA A Y. Utilization-prediction-aware virtual machine consolidation approach for energy-efficient cloud data centers [J]. Journal of Parallel Distributed Computing, 2020, 139: 99-109.
[27] ARYANIA A, AGHDASI H S, KHANLI L M. Energy-aware virtual machine consolidation algorithm based on ant colony system [J]. Journal of Grid Computing, 2018, 16(3): 477-491.
[28] ZHENG Q, LI R, LI X, SHAH N, ZHANG J, TIAN F. Virtual machine consolidated placement based on multi- objective biogeography-based optimization [J]. Future Generation Computer Systems, 2016, 54(1): 95-122.
[29] ZHANG X, WU T, CHEN M, WEI T, ZHOU J, HU S. Energy-aware virtual machine allocation for cloud with resource reservation [J]. Journal of Systemsand Software, 2019, 147(1): 147-161.
[30] BELOGLAZOV A, ABAWAJY J, BUYYA R. Energy-aware resource allocation heuristics for efficient management of data centers for cloud computing [J]. Future Generation Computer Systems, 2012, 28(5): 755-768.
(Edited by ZHENG Yu-tong)
���ĵ���
�Ƽ�����SLA�غ�ĸ�Ч�����Ǩ�Ʒ���
ժҪ���������߹������ļ��������û���ָ����������Ȼ�����ƻ����������µ����ģ�������Ľ����¸��ܺġ���ˣ��Ż���Դ���ö���������������ĵ���Ч������Ҫ���������״���ע�����(VM)���ϣ��Լ���ˮƽЭ��Ϊ�����������Ч����������˸��ظ�֪����������ֵ(LATHR)�Ľ��������ϼ���(MBFD)�㷨������߷���������ͬʱ������ȵؽ������ܺġ��ڵ��������Ϸ���Ķ�̬�������غͿɱ������������(1-290)�£��ṩ����Ч�����ʵ����ͨ��SLA���������ġ�ָ��������(IER)�Լ�����ڲ�ͬ�����������Ǩ�ƴ�����������ʵ��������������λ������ƫ��(MAD)���ķ�λ��Χ(IQR)��˫��ֵ(THR)���ؼ�������ȣ��ü���SLAΥ���ʷֱ���55%��26%��39%���ܺķֱ���17%��12%��6%��
�ؼ��ʣ��Ƽ��㣻��Ч��������ֵ����Դ���䣻����ˮƽЭ��
Received date: 2020-05-16; Accepted date: 2020-10-18
Corresponding author: GARG Vaneet, Assistant Professor; Tel: +91-9876536136; E-mail: Aggarwal.vkg@gmail.com; ORCID: https://orcid.org/0000-0003-0502-1292

