»щУЪТАґж№ШПµµДѕд·Ё·ЦОцНіјЖДЈРН
Ф¬ Ап іЫ1, 2
(1. ЅОчІЖѕґуС§ РЕПўС§ФєКэѕЭУлЦЄК¶№¤іМЅОчКЎЦШµгКµСйКТЈ¬ЅОч ДПІэЈ¬330013Ј»
2. ЦРДПґуС§ РЕПўїЖС§У빤іМС§ФєЈ¬єюДП і¤ЙіЈ¬410083)
ХЄ ТЄЈєАыУГУпТеЎўУп·ЁµИУпСФЦЄК¶Ј¬ЅЁБўТ»ЦЦ»щУЪТАґж№ШПµµДѕд·Ё·ЦОцНіјЖДЈРНЈ¬ІўАыУГёДЅшµДѕд·Ё·ЦОцДЈРНЅшРРѕд·Ё·ЦОцКµСйЎЈСРѕїЅб№ы±нГчЈєАыУГТАґж№ШПµЎў»ҐРЕПў¶ФґКѕЫАаЈ¬ДЬЅвѕцДЈРНКэѕЭПЎКиОКМвЈ»ДЈРНїЙН¬К±їјВЗјёЦЦУпТеТАґж№ШПµЈ»ёГДЈРНКЗТ»ёцґК»г»ЇµДѕд·Ё·ЦОцДЈРНЈ¬ДЬЅбєП·ЦґКЎўґКРФ±кЧўЅшРРѕд·Ё·ЦОцЈ»ёЕВКЙППВОДОЮ№ШУп·ЁЦРУЙёЕВКµДЙППВОДОЮ№ШРФјЩЙиєНЧжПИЅбµгОЮ№ШРФјЩЙиТэЖрµДОКМвФЪёГДЈРНЦеõЅУРР§ЅвѕцЈ»ѕ«И·ВКєНХЩ»ШВК·Ц±рОЄ86.96%єН85.25%Ј¬ЖдЧЫєПЦё±кFУлCollinsµДН·Зэ¶Їѕд·Ё·ЦОцДЈРНµДFПа±ИМбёЯ4.75%ЎЈ
№ШјьґКЈєЧФИ»УпСФґ¦АнЈ»ґКѕЫАаЈ»ЦРРДґКЗэ¶ЇЈ»ѕд·Ё·ЦОцНіјЖДЈРН
ЦРНј·ЦАаєЕЈєTP391.1 ОДПЧ±кЦѕВлЈєA ОДХВ±аєЕЈє1672-7207(2009)06-1630-06
Statistical language paring model based on dependency
YUAN Li-chi1, 2
(1. School of Information Technology, Jiangxi University of Finance and Economics, Nanchang 330013, China;
2. School of Information Science and Engineering, Central South University, Changsha 410083, China)
Abstract: By incorporating linguistic features such as semantic dependency and syntactic relations, a novel statistical Parsing model was proposed. The experiments were conducted for the refined statistical parser. The results show that the model is constructed on word cluster, so the problem of data sparseness is not serious. The model can take advantage of a few semantic dependencies at the same time. The model is a parser based on lexicalized model, it is combined with segmentation and POS tagging model and thus a language parser is built. The questions caused by context-free hypothesis and ancestor-free hypothesis in probability context free grammar are solved well in this model. It achieves 86.96% precision and recall 85.25%, F value is improved by 4.75% compared with that of the head-driven parsing model introduced by Collins.
Key words: natural language processing; word clustering; head-driven parsing model; statistical parsing model
ѕд·Ё·ЦОц[1]Ј¬ѕНКЗЦёёщѕЭёш¶ЁµДУп·ЁЈ¬ЧФ¶ЇµШК¶±ріцѕдЧУЛщ°ьє¬µДѕд·ЁµҐО»єНХвР©ѕд·ЁµҐО»Ц®јдµД№ШПµЎЈѕд·Ё·ЦОцКЗЧФИ»УпСФАнЅвµДТ»ёц№ШјьЧйіЙІї·ЦЈ¬КЗ¶ФЧФИ»УпСФЅшРРЅшТ»ІЅУпТе·ЦОцµД»щґЎЎЈЛжЧЕЧФИ»УпСФУ¦УГµДИХТж№г·єЈ¬МШ±рКЗ¶ФОД±ѕґ¦АнРиЗуµДЅшТ»ІЅФцјУЈ¬ѕд·Ё·ЦОцµДЧчУГУъјУН»іцЈ¬ЛьјёєхіЙОЄґу¶аКэЧФИ»УпСФґ¦АнУ¦УГµД№ШјьТтЛШЈ¬Из»ъЖч·ТлЎўРЕПўійИЎЎўОКґрПµНіЎўјмЛчПµНіµИЎЈѕд·Ё·ЦОцµДСРѕїґуМе·ЦОЄ2ЦЦНѕѕ¶Јє»щУЪ№жФтµД·Ѕ·ЁєН»щУЪНіјЖµД·Ѕ·ЁЎЈ»щУЪ№жФтµД·Ѕ·ЁКЗТФЦЄК¶ОЄЦчМеµДАнРФЦчТе(Rationalism)·Ѕ·Ё[2]Ј¬ТФУпСФС§АнВЫОЄ»щґЎЈ¬ЗїµчУпСФС§јТ¶ФУпСФПЦПуµДИПК¶Ј¬ІЙУГ·ЗЖзТеµД№жФтРОКЅГиКц»тЅвКНЖзТеРРОЄ»тЖзТеМШРФЎЈ»щУЪНіјЖµДѕд·Ё·ЦОц[1, 3]±ШРлТФДіЦЦ·ЅКЅ¶ФУпСФµДРОКЅєНУп·Ё№жФтЅшРРГиКцЈ¬¶шЗТХвЦЦГиКц±ШРлїЙТФНЁ№э¶ФТСЦЄѕд·Ё·ЦОцЅб№ыЅшРРСµБ·»сµГЈ¬Хв±гКЗѕд·Ё·ЦОцДЈРНЎЈ»щУЪКчївµДНіјЖѕд·Ё·ЦОц[4-6]КЗПЦґъѕд·Ё·ЦОцµДЦчБчјјКхЎЈ№№ЅЁНіјЖѕд·Ё·ЦОцДЈРНµДДїµДКЗТФёЕВКµДРОКЅЖАјЫИфёЙёцїЙДЬµДѕд·Ё·ЦОцЅб№ы(НЁіЈ±нКѕОЄУп·ЁКчРОКЅ)ІўФЪХвИфёЙёцїЙДЬµД·ЦОцЅб№ыЦРЦ±ЅУСЎФсТ»ёцЧоїЙДЬµДЅб№ыЎЈ»щУЪНіјЖµДѕд·Ё·ЦОцДЈРНЖдКµЦККЗТ»ёцЖАјЫѕд·Ё·ЦОцЅб№ыµДёЕВКЖАјЫєЇКэ,јґ¶ФУЪИОТвТ»ёцКдИлѕдЧУsєНЛьµДѕд·Ё·ЦОцЅб№ыtЈ¬ёшіцТ»ёцМхјюёЕВКP(t|s)Ј¬ІўУЙґЛХТіцёГѕд·Ё·ЦОцДЈРНИПОЄёЕВКЧоґуµДѕд·Ё·ЦОцЅб№ыЈ¬јґХТµЅ ,ѕд·Ё·ЦОцОКМвµДСщ±ѕїХјдОЄSЎБT(ЖдЦРЈєSОЄЛщУРѕдЧУµДјЇєПЈ¬TОЄЛщУРѕд·Ё·ЦОцЅб№ыµДјЇєП)ЎЈ
,ѕд·Ё·ЦОцОКМвµДСщ±ѕїХјдОЄSЎБT(ЖдЦРЈєSОЄЛщУРѕдЧУµДјЇєПЈ¬TОЄЛщУРѕд·Ё·ЦОцЅб№ыµДјЇєП)ЎЈ
НіјЖѕд·Ё·ЦОцГжБЩµДТ»ёцЦчТЄОКМвКЗИзєО·ўПЦєНАыУГѕЯУРЗїПыЖзДЬБ¦µДУпСФМШХчЦЄК¶[7-9]Ј¬Н¬К±±ЈЦ¤УпСФЦЄК¶µДУ¦УГІ»»бК№ДЈРНµДІОКэј±ѕзЕтХН¶шµјЦВСПЦШµДКэѕЭПЎКиОКМвЎЈ±ѕДЈРНґУ3ёц·ЅГжАґИЪєП·бё»УпСФМШХчЦЄК¶Јєa. АыУГТАґж№ШПµЎў»ҐРЕПў¶ФґКѕЫАаЈ¬ЅвѕцБЛДЈРНКэѕЭПЎКиОКМвЈ»b. Н¬К±їјВЗјёЦЦУпТеТАґж№ШПµЈ»c. Ѕ«ѕд·Ё·ЦОцДЈРНУл·ЦґКЎўґКРФ±кЧўДЈРНЅбєПЅшРРѕд·Ё·ЦОцЎЈ
1 Н·Зэ¶Їѕд·Ё·ЦОцДЈРН
CollinsК№УГPenn tree bankКµПЦµДН·Зэ¶ЇµДУўУпѕд·Ё·ЦОцЖч[10]Ј¬КЗДїЗ°ЛщЦЄФЪПаН¬µДСµБ·УпБПєНІвКФјЇПВ»сµГµДЧоєГЅб№ыЎЈCollinsЛщМбіцµДѕд·Ё·ЦОцДЈРНКЗТ»ЦЦґК»г»ЇДЈРНЈ¬Жд»щ±ѕЛјПлКЗФЪЙППВОДОЮ№Ш№жФтЦРТэИлГїёц¶МУпµДєЛРДґКРЕПўЎЈ
Collins°С·ЦОцКчµДёЕВК·ЦЅвОЄ BaseNPs(B) ёЕВКєНТАґж№ШПµ(D)ёЕВКµДіЛ»эЈє
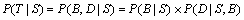 ЎЈ (1)
ЎЈ (1)
КЅЦРЈєSОЄґшУРґКРФ±кјЗµДґэ·ЦОцµДі¤¶ИОЄn µДУўУпѕдЧУЎЈґКРФ±кјЗІЙИЎЧоґумШ±кЧў·Ѕ·ЁЈ¬ФЪSЦРИҐµф±кµг·ыєЕЈ¬Іў°СBaseNPs УГЖдЦРРДґК±нКѕЈ¬РОіЙ Ј¬Фтґэ·ЦОцµДѕдЧУіЙОЄ Ёў ґК, ґКРФ±кјЗ ? ¶ФµДПµБРЎЈ
Ј¬Фтґэ·ЦОцµДѕдЧУіЙОЄ Ёў ґК, ґКРФ±кјЗ ? ¶ФµДПµБРЎЈ
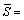 Ёў
Ёў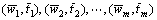 ?Ј¬mЎЬnЎЈ
?Ј¬mЎЬnЎЈ
·ЦОцКчµЅТАґжЅб№№µДУіЙдКЗТАґжДЈРНµДєЛРДЈ¬ёГПµНіІЙИЎБЛТФПВІЅЦијЖЛг ЎЈ
ЎЈ
ІЅЦи1 ¶ФУЪ·ЦОцКчЦРГїёцѕд·ЁіЙ·ЦPЎъ ЁўC1, C2, Ў, Cn?Ј¬И·¶ЁPµДЦРРДґКЈ¬ЦРРДґКґУ·ЦОцКчµДТ¶ЅЪµгПтЙПґ«ІҐЎЈ
ІЅЦи2 ЦРРДґК-РЮКО№ШПµµДійИЎЈ¬РОіЙИэФЄЧйЈ¬¶ЁТе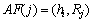 Ј¬Ль±нКѕФЪЦРµДµЪjёцґККЗµЪ
Ј¬Ль±нКѕФЪЦРµДµЪjёцґККЗµЪ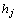 ёцґКµДРЮКОґКЎЈЛьГЗЦ®јдѕЯУР№ШПµ
ёцґКµДРЮКОґКЎЈЛьГЗЦ®јдѕЯУР№ШПµ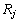 Ј¬D¶ЁТеОЄУРТАґж№ШПµµДmФЄЧйЎЈ
Ј¬D¶ЁТеОЄУРТАґж№ШПµµДmФЄЧйЎЈ
 Ј» (2)
Ј» (2)
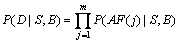 ЎЈ (3)
ЎЈ (3)
ДЈРНЦРЈ¬·ЗЦХЅб·ыРОИзX(x)ЎЈЖдЦРЈєx =Ёўw, t?Ј¬wОЄ¶МУп¶ФУ¦єЛРДґКЈ¬tОЄєЛРДґКµДґКРФ±кјЗЈ¬ЦХЅб·ыРОИзt(w)ЎЈ
 ЎЈ (4)
ЎЈ (4)
КЅЦРЈєPОЄ·ЗЦХЅб·ыЈ»hОЄєЛРДЅбµгЛщФЪ¶МУпµД·ыєЕ±кјЗєНґКРЕПўЈ»LiОЄєЛРДіЙ·ЦµДЧу±ЯіЙ·ЦЈ»RiОЄєЛРДіЙ·ЦУТ±ЯіЙ·ЦЎЈ
УЙУЪТэИлґК»гРЕПўЈ¬І»їЙ±ЬГвЅ«іцПЦСПЦШµДКэѕЭПЎКиОКМвЎЈОЄБЛ±ЬГвКэѕЭПЎКиОКМвЈ¬CollinsІЙИЎ°С№жФт·ЦЅвµД·Ѕ·ЁЈ¬јґФЪСµБ·УпБПЦР°СГїТ»Мх№жФт·ЦЅвіЙИфёЙёц¶ФУ¦ЖдН·ЅЪµгµДТАґж№жФтЎЈ
ТСЦЄ№жФтЈє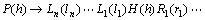
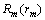 Ј¬№жФтµДёЕВКУЙєЛРДіЙ·ЦµДёЕВКЎўєЛРДіЙ·ЦµДЧуТАґжёЕВКєНУТТАґжёЕВКЧйіЙЈ¬јґЈє
Ј¬№жФтµДёЕВКУЙєЛРДіЙ·ЦµДёЕВКЎўєЛРДіЙ·ЦµДЧуТАґжёЕВКєНУТТАґжёЕВКЧйіЙЈ¬јґЈє
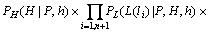
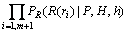 ЎЈ (5)
ЎЈ (5)
Н·Зэ¶ЇµДѕд·Ё·ЦОцДЈРНУлPCFGДЈРНЧоЦчТЄµДЗш±рОЄИзПВ2ёц·ЅГжЈє
a. ФЪ№жФтЦРТэИлєЛРДЅбµгµДґК»гРЕПўЎЈ
b. ¶ФЙППВОДОЮ№Ш№жФтЅшРР·ЦЅв,Их»ЇБЛЙППВОДОЮ№Ш№жФтµДЅб№№РЕПўЈ¬Ѕб№№РЕПўНЁ№эµ±З°ЅбµгФЪєЛРДЅбµгµДЧу»тУТАґМеПЦЎЈ
ТэИлґК»гРЕПўЈ¬ОЮТЙФцЗїБЛѕд·Ё·ЦОцµДПыЖзДЬБ¦ЎЈЅ«ЙППВОДОЮ№Ш№жФтЅшРР·ЦЅвЈ¬Т»·ЅГжЅвѕцБЛТэИлґК»гРЕПўЛщґшАґµДКэѕЭПЎКиОКМвЈ»БнТ»·ЅГжЈ¬№жФтЅшРР·ЦЅвєуїЙТФЦШРВЧйєПіцСµБ·№эіМЦРОґіцПЦµДЙППВОДОЮ№Ш№жФтЈ¬ТІФЪТ»¶ЁіМ¶ИµШЅвѕцБЛЙППВОДОЮ№Ш№жФтµДКэѕЭПЎКиОКМвЎЈ
µ«ЅшТ»ІЅµДКµСйЅб№ы±нГчЈ¬ѕд·Ё·ЦОцК±Ј¬№жФтµДЅб№№РЕПўЛщѕЯУРµДПыЖзДЬБ¦ЗїУЪґК»гРЕПўЛщЖрµДЧчУГЎЈУлPCFGµД¶Ф±ИКµСйЅб№ы±нГчЈ¬К№УГКЅ(5)Лщ№№ЅЁµДѕд·Ё·ЦОцЖчР§№ыІ»ИзPCFGДЈРНµДР§№ыЎЈОЄґЛЈ¬Collins[10]ФЪДЈРНЦРФцјУБЛТ»ёцѕаАлєЇКэАґІ№іҐЅб№№РЕПўµДИ±К§ЎЈѕаАлРЕПўїјВЗБЛ3ЦЦЗйїцЈєa. ёГіЙ·ЦЗ°КЗ·сУРіЙ·ЦЎЈb. ёГіЙ·ЦЗ°КЗ·сіцПЦ¶ЇґКЎЈc. ёГіЙ·ЦЗ°КЗ·сіцПЦ±кµг·ыєЕЎЈ
ЧоЦХ№жФтµДёЕВКЖАјЫєЇКэОЄЈє

Н·Зэ¶Їѕд·Ё·ЦОцДЈРНјУИлґК»гРЕПўЈ¬МбёЯБЛѕд·Ё·ЦОцДЈРНµДЖзТеПыЅвДЬБ¦Ј¬µ«І»їЙ±ЬГвµШУЦґшАґБЛКэѕЭПЎКиОКМвЈ¬ОЄґЛЈ¬CollinsІЙУГ»ШНЛ·Ё¶ФКэѕЭЅшРРЖЅ»¬ЎЈФЪН·Зэ¶ЇµДѕд·Ё·ЦОцДЈРНЦРЈ¬ЅвѕцКэѕЭПЎКиОКМвКЗМбёЯѕд·Ё·ЦОцРФДЬµД№ШјьЎЈ
2 »щУЪТАґж№ШПµєН»ҐРЕПўµДґКѕЫАа ·Ѕ·Ё
ФЪєєУпµД»щ±ѕѕдРНЦРЈ¬ѕшґу¶аКэѕдЧУµДЦРРДУпКЗУЙ¶ЇґК(¶МУп)µЈµ±Ј¬Ц»УРЙЩКэѕдЧУµДЦРРДУпКЗУЙРОИЭґК»тМеґКµЈµ±ЎЈН¬СщЈ¬ФЪєєУпµД»щ±ѕѕдРНЦРЈ¬ѕшґу¶аКэѕдЧУµДЦчУпєН±цУп¶јКЗУЙГыґК(¶МУп)µЈµ±Ј¬Ц»УРЙЩКэѕдЧУЦчУпєН±цУпКЗУЙРОИЭґК»т¶ЇґК(¶МУп)µЈµ±ЎЈУЙУЪѕдЧУµДЦРРДУпЦ§ЕдЧЕѕдЧУЦРµДЖдЛыіЙ·Ц(ЦчУпЎў±цУпЎўЧґУпєНІ№Уп)Ј¬ЛщТФЈ¬УР±ШТЄ¶Ф¶ЇґКЎўГыґКєНРОИЭґКµИёчЦЦґКµДУпТеЦЄК¶ЅшРР·ЦОцІўјУТФ·ЦАаЈ¬Ѕш¶шґУЦРЧЬЅбіцЦРРДУпУлёч±»Ц§ЕдіЙ·ЦЦ®јдµДУпТе№ШПµЎЈ
¶ЇґК¶ФГыґКАа±рµДСЎФсѕц¶ЁБЛКІГґАаµДГыґКДЬМнИлКІГґСщµДІЫДЪЈ¬ЧчХЯіЖЦ®ОЄ¶ЇґК¶ФГыґКµДЦЖФјСЎФсЎЈґУФФтЙПЛµЈ¬¶ЇґКµДёЕДо¶ЁТеѕНѕц¶ЁБЛ¶ЇґКµДЦЖФјСЎФсЎЈАэИзЈ¬ТАѕЭЧчУГ¶ЇґКµДёЕДо¶ЁТеЈ¬¶ЇґКµДК©КВ±ШИ»КЗДЬ·ўіцК№ёР№ЩЦ±ЅУёРКЬµЅѕЯМе»о¶ЇµДТеАаГыґКЈ¬ЖдКЬКВФт±ШИ»К№ДЬЅУКЬХвЦЦ»о¶ЇµДТеАаГыґКЎЈЖдУаТАґЛАаНЖЎЈ
2.1 ґКµДПаЛЖ¶И¶ЁТе
ЧЫЙПЛщКц, ёщѕЭУпТеТАґж№ШПµ[11]єНУп·ЁМШРФ¶ФґКЅшРР·ЦАаєЬОЄ±ШТЄЎЈµ±И»Ј¬ХвР©·ЦАаїЙТФУЙУпСФС§јТТАѕЭУпСФЦЄК¶ЅшРРЈ¬µ«АыУГНіјЖДЈРНЎўЅбєПУпСФС§ЦЄК¶¶ФґКЧФ¶ЇѕЫАа[12-13]µД·Ѕ·ЁїЙДЬёьїЙИЎЎЈ
Йиw1єНw2КЗѕЯУРТАґж№ШПµrelµДґК¶ФЈ¬УГИэФЄЧй(w1, rel, w2)±нКѕґК¶ФєНЛьГЗЦ®јдµДТАґж№ШПµЎЈФтґК¶Ф(w1, w2)ФЪТАґж№ШПµrelПВµД»ҐРЕПў¶ЁТеОЄЈє

2.2 ѕЫАаЛг·Ё
ХыёцЛг·ЁµДБчіМИзПВЛщКѕЈє
a. јЖЛгґК¶ФЦ®јдµДПаЛЖ¶ИЎЈ
b. іхКј»ЇЈ¬ґК±нЦРµДГїёцґКёчґъ±нТ»АаЈ¬№ІNАа(NОЄґК±нЦРґКµДКэБї)ЎЈ
c. ХТіцѕЯУРЧоґуПаЛЖ¶ИµД2ёцґКАаЈ¬Ѕ«Хв2ёцґКАаєПІўіЙ1ёцРВµДґКАаЎЈ
d. јЖЛгёХєПІўґКАаУлЖдЛыґКАаµДПаЛЖ¶ИЎЈ
e. јмІйКЗ·сґпµЅЅбКшМхјю(ґКАаЦ®јдЧоґуПаЛЖ¶ИРЎУЪДіёцФ¤ПИѕц¶ЁµДГЕјчЦµЈ¬»тКЗґКАаµДКэДїґпµЅБЛТЄЗу)Ј¬ИфКЗЈ¬ФтіМРтЅбКшЈ»·сФтЈ¬ЧЄІЅЦиcЎЈ
3 »щУЪТАґж№ШПµєНѕЫАаµДѕд·Ё·ЦОцДЈРН
ФЪК№УГёГДЈРНЗ°Ј¬ПИАыУГЖдЛыµДѕд·Ё·ЦОц·Ѕ·ЁЅшРРѕд·Ё·ЦОцЈ¬µГµЅЛщУРїЙДЬµДѕд·ЁКчЈ¬ФЩАыУГФ¤ПИКдИлµДґКУпРЕПў¶ФґКУпЅшРРѕд·ЁіЙ·Ц±кЧў,ТФј°№йДЙіцЛьГЗЦ®јдµДУп·ЁЎўУпТеТАґж№ШПµЈ¬ЧоєуАыУГёГДЈРН¶Фѕд·ЁКчЅшРРСЎФсЎЈ
ёГДЈРНФЪЅшРРёЕВКјЖЛгК±ІЙИЎЧФЙП¶шПВ·ЦІгЈ¬ЧФЧуЦБУТµДЛг·ЁЎЈЙиA±нКѕµ±З°ґКЈ¬TA±нКѕЖдґКРФЈ¬B, C, D, Ў±нКѕФЪAЙПІгєНЗ°ГжµДґКЈ¬TB, TC, TD, Ў±нКѕЛьГЗµДґКРФЎЈјЖЛгМхјюёЕВКЈє

УЙВн¶ыїЙ·тЧеДЈРН[14]µДјЩ¶ЁїЙЦЄЈ¬µ±З°ґКµДіцПЦёЕВКЦ»УлЛьµДґКРФєНЖдЛыґКУР№ШЈ¬¶шУлЖдЛыґКµДґКРФОЮ№ШЎЈЅбєПТАґжУп·ЁїЙТФИПОЄ, µ±З°ґКµДіцПЦёЕВКЦ»УлЛьµДґКРФєНЖдЛыУлёГґКУРУпТеТАґж№ШПµµДєЛРДґКУР№ШЎЈФЪ1ёцѕдЧУЦРЈ¬Ул1ёцґКУРУпТеТАґж№ШПµµДєЛРДґКїЙДЬІ»Ц№1ёцЈ¬ИзЈє
Astronomers saw stars with telescopesЎЈ
ФЪёГѕдЧУЦРЈ¬ґКtelescopesФЪУпТеґоЕдЙПјИУлЖдЦ±ЅУµДєЛРДґКwithУР№ШЈ¬УЦУлХыёцѕдЧУµДєЛРДґКsawУР№ШЎЈµ±И»Ј¬ТАґжЗї¶ИїЙДЬУРЛщЗш±рЎЈ¶шУлТ»ёцґКУРУп·Ё№ШПµµДєЛРДґКЦ»ДЬУР1ёцЈ¬ТтФЪУГёЕВКЙППВОДОЮ№ШУп·ЁЅшРРѕд·Ё·ЦОцК±Ј¬У¦УГУЪГїёцґКµДІъЙъКЅµДЧжПИЅбµгЦ»УР1ёцЎЈ
І»·БЙиУлґКAУРУп·Ё№ШПµµДєЛРДґКОЄBЈ¬Уп·Ё№ШПµОЄRЈ¬УлЖдПаБЪµДЗ°Гж2ёцґКОЄCєНDЈ¬ПВГжјЖЛгКЅ(12)УТ±ЯµДµЪ2ёцМхјюёЕВКЈє
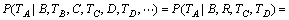
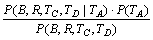 ЎЈ (13)
ЎЈ (13)
јЩ¶ЁBЈ¬RЈ¬TCЈ¬TDП໥¶АБўЈ¬µ±И»ЛьГЗ№ШУЪМхјюTAТІП໥¶АБўЈ¬ФтУРЈє
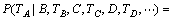
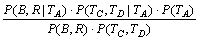 ЎЈ (14)
ЎЈ (14)
ФЩУЙ±ґТ¶Л№№«КЅЈ¬УРЈє
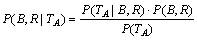 Ј»
Ј»
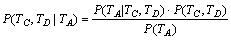 ЎЈ(15)
ЎЈ(15)
Ѕ«КЅ(15)ґъИлКЅ(14)Ј¬УРЈє
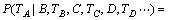
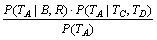 ЎЈ (16)
ЎЈ (16)
МхјюёЕВК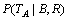 Паµ±УЪФЪЙППВОДОЮ№Ш№жФтµДёЕВКјЖЛгЦРТэИлГїёц¶МУпµДєЛРДґКРЕПўЈ¬ИзІъЙъКЅVPЎъV NP ёДЅшОЄЈє
Паµ±УЪФЪЙППВОДОЮ№Ш№жФтµДёЕВКјЖЛгЦРТэИлГїёц¶МУпµДєЛРДґКРЕПўЈ¬ИзІъЙъКЅVPЎъV NP ёДЅшОЄЈє
VP (saw) ЎъV(saw)NP(president)ЎЈ
УЙУЪКэѕЭПЎКиОКМв, єЛРДґКїЙУГєЛРДґКµДУп·ЁАа(УРПаН¬Уп·ЁґоЕд№ШПµµДТ»АаґК)АґґъМжЎЈ¶ш 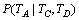 јґОЄґКРФ±кЧўЦРіЈУГµДИэФЄДЈРНЎЈТтґЛЈ¬КЅ(16)ТвТеГчИ·ЎЈ
јґОЄґКРФ±кЧўЦРіЈУГµДИэФЄДЈРНЎЈТтґЛЈ¬КЅ(16)ТвТеГчИ·ЎЈ
ЙиУлґКAУРУпТеТАґж№ШПµµДєЛРДґКОЄEєНFЈ¬ ТАґж№ШПµОЄrelEЈ¬relFЈ¬ФтКЅ(12)УТ±ЯµДµЪТ»ёцМхјюёЕВКОЄЈє
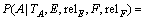
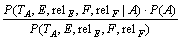 ЎЈ (17)
ЎЈ (17)
ѕУлЙПГжАаЛЖµДјЖЛгїЙµГЈє
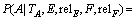
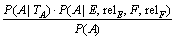 ЎЈ (18)
ЎЈ (18)
ОЄБЛјхЙЩІОКэЅП¶аТэЖрµДКэѕЭПЎКиОКМв, МхјюёЕВК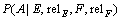 їЙК№УГІеЦµ·Ѕ·ЁјЖЛгЈє
їЙК№УГІеЦµ·Ѕ·ЁјЖЛгЈє
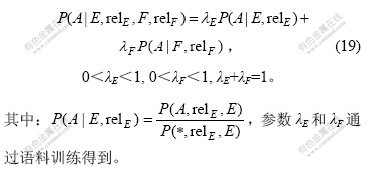
ОЄБЛЅшТ»ІЅјхЙЩКэѕЭПЎКиЈ¬їЙУГґКAЈ¬EєНF№йКфµДУпТеАаWAЈ¬WEЈ¬WFґъМжAЈ¬EєНFЎЈ
ЧЫЙПЛщКцЈ¬ёГДЈРНµДјЖЛгЦчТЄ°ьАЁКЅ(16)єНКЅ(18)Хв2ёцІї·ЦЎЈёГДЈРНФЪЅ«УпСФЦЄК¶УлНіјЖ·Ѕ·ЁИЪєП·ЅГжµГµЅіЙ№¦У¦УГЈ¬ДЈРНµДёЕВКТвТеТІ·ЗіЈГчИ·ЎЈ
4 КµСйЅб№ы
±ѕОДµДКµСйКЗФЪ±цЦЭЦРОДКчївChinese Treebank (CTB)5.0ЙПЅшРРµДЎЈCTBКЗУЙУпСФКэѕЭБЄГЛ(LDC)№«їЄ·ўµДТ»ёцУпБПївЈ¬ОЄєєУпѕд·Ё·ЦОцСРѕїМṩБЛТ»ёц№«№ІµДСµБ·єНІвКФЖЅМЁЎЈёГКчїв°ьє¬БЛ507 222ёцґКЈ¬824 983ёцєєЧЦЈ¬18 782ёцѕдЧУЈ¬УР890ёцКэѕЭОДјюЎЈЧчХЯЅ«ОДјю301~325(353ёцѕдЧУЈ¬6 776ёцґК) ЧчОЄµчКФјЇЈ¬Ѕ«ОДјю271~300(348ёцѕдЧУЈ¬7 980ёцґК)ЧчОЄІвКФјЇЈ¬ЖдУаОДјюЧчОЄСµБ·јЇЎЈ±ѕОДµДЛщУРКµСйЦРЈ¬ДЈРНµДІОКэ¶јКЗґУСµБ·јЇЦРІЙУГј«ґуЛЖИ»·Ё№АјЖіц АґµДЎЈ
¶ФІвКФµДЅб№ыІЙИЎіЈУГµД3ёцЖАІвЦё±кЈ¬јґЧјИ·ВКPЎўХЩ»ШВКRЎўЧЫєПЦё±кFЎЈѕ«И·ВК(Precision)УГАґєвБїѕд·Ё·ЦОцПµНіЛщ·ЦОцµДЛщУРіЙ·ЦЦРХэИ·іЙ·ЦµД±ИАэЈ»ХЩ»ШВК(Recall)УГАґєвБїѕд·Ё·ЦОцПµНі·ЦОціцµДЛщУРХэИ·іЙ·ЦФЪКµјКіЙ·ЦЦРµД±ИАэЈ»ЧЫєПЦё±к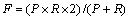 ЎЈ
ЎЈ
КµСй1 ±ѕСРѕїКЧПИАыУГґК»г»ЇДЈРН¶ФІвКФјЇЦРµДѕдЧУЅшРР·ЦґКєНґКРФ±кЧўЈ¬УлЧоіЈУГµДТюВн¶ыїЙ·тґКРФ±кЧўДЈРН(HMM)ЅшРР¶Ф±ИЎЈ±н1ЛщКѕОЄКµСйЅб№ыЎЈїЙТФїґµЅЈ¬ґК»г»ЇДЈРНµДґКРФ±кЧўР§№ыТЄєГУЪHMMµДґКРФ±кЧўР§№ыЎЈ
±н 1 ґКРФ±кЧўКµСйЅб№ы
Table 1 Experimental results of POS tagging
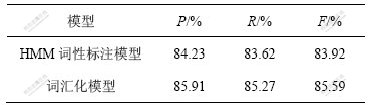
ТюВн¶ыїЙ·тґКРФ±кЧўДЈРНјЩ¶Ёµ±З°ґКАа±кјЗµДіцПЦёЕВКЦ»УлЛьЅфБЪµДЗ°1ёц»тјёёцґКАа±кјЗУР№ШЈ»ґК»г»ЇґКРФ±кЧўДЈРНИПОЄµ±З°ґКАа±кјЗµДіцПЦёЕВКІ»µ«УлЛьЅфБЪµДЗ°ГжґКАа±кјЗУР№ШЈ¬¶шЗТУлµ±З°ґК±ѕЙнµДґКАаМШРФУР№ШЎЈґУНіјЖС§µДЅЗ¶ИАґЛµЈ¬УлґК»г»ЇДЈРНµДјЩЙиПа±ИЈ¬ТюВн¶ыїЙ·тґКРФ±кЧўДЈРНµДјЩЙиКЗ№эЗїјЩЙиЎЈКµСй1µДЅб№ыТІЦ¤ГчБЛґК»г»ЇДЈРНёь·ыєПУпСФПЦПуЎЈ
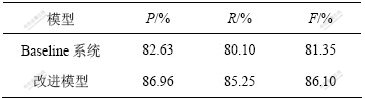
КµСй2 КµСйЦРЧчХЯІЙУГµДѕд·Ё·ЦОцBaselineПµНіКЗDaniel M.Bikel»щУЪCollinsДЈРНКµПЦµДDBParserЎЈ±н2ЛщКѕОЄBaselineПµНієНёДЅшДЈРНµДѕд·Ё·ЦОцКµСйЅб№ыЎЈґУ±н2їЙТФїґіцЈєУЙУЪФЪґКµДѕЫАаЎўѕд·ЁіЙ·Ц±кЧўЦРЈ¬¶аІгґОµШАыУГБЛУп·ЁєНУпТеТАґж№ШПµµИУпСФЦЄК¶Ј¬ёДЅшДЈРНµДЧјИ·ВКPЎўХЩ»ШВКRєНЧЫєПЦё±кFУлCollinsµДН·Зэ¶Їѕд·Ё·ЦОцДЈРНПа±ИУРГчПФМбёЯЎЈ
±н2 ѕд·Ё·ЦОцКµСйЅб№ы
Table 2 Experimental results of language parsing
5 Ѕб ВЫ
a. УпСФМШХчЦЄК¶µДУ¦УГ¶ФНіјЖѕд·Ё·ЦОцУРєЬґуµДУ°ПмЈ¬ХвґУТ»ёцІаГжЦёіцБЛєєУпНіјЖѕд·Ё·ЦОцСРѕїµДТ»ёц·ЅПтЈ¬јґґУУпСФС§ЅЗ¶ИС°ХТёь¶аµДМШХчЦЄК¶ЎЈґУНіјЖѕд·Ё·ЦОцµДЅЗ¶ИАґїґЈ¬Т»ёцєГµДјЖЛгДЈРНјУЙП·бё»µДУпСФМШХчЦЄК¶ІЕКЗЧојССЎФсЎЈ
b. ТАґжУп·Ё·ЦОцѕдЧУµД·ЅКЅЈ¬КЗНЁ№э·ЦОцѕдЧУіЙ·ЦјдµДУп·ЁєНУпТеТАґж№ШПµЈ¬ЅЁБўТФѕдЧУіЙ·ЦОЄЅЪµгµДТАґжУп·ЁКчЈ¬ТФґЛ±нґпѕдЧУµДЅб№№ЎЈЛщТФЈ¬КЧПИТЄЅвѕцµДОКМвКЗЈ¬И·¶ЁТАґжУп·ЁЦРѕдЧУіЙ·ЦµДЦЦАаєНіЙ·ЦЦ®јдµДТАґж№ШПµАаРНЎЈНЁіЈФЪНіјЖѕд·Ё·ЦОцЦРИЪИлУпТеЦЄК¶µДДЈРН(јґ»щУЪУпТеТАґж№ШПµµДѕд·Ё·ЦОц ДЈРН)ЎЈ
c. АыУГУпТеєНУп·ЁµИУпСФЦЄК¶Ј¬ЅЁБўБЛТ»ЦЦ»щУЪТАґж№ШПµµДѕд·Ё·ЦОцНіјЖДЈРНЈ¬ІўЅбєП·ЦґКєНґКРФ±кЧўЅшРРѕд·Ё·ЦОцЎЈФЪёЕВКЙППВОДОЮ№ШУп·ЁЦРЈ¬УЙёЕВКµДЙППВОДОЮ№ШРФјЩЙиєНЧжПИЅбµгОЮ№ШРФјЩЙиТэЖрµДОКМвФЪёГДЈРНЦеõЅУРР§ЅвѕцЎЈУлCollinsµДН·Зэ¶Їѕд·Ё·ЦОцДЈРНПа±ИЈ¬УЙУЪФЪґКµДѕЫАаєНѕд·ЁіЙ·Ц±кЧўЦР,¶аІгґОµШАыУГБЛУп·ЁєНУпТеТАґж№ШПµµИУпСФЦЄК¶Ј¬ёДЅшДЈРНµДРФДЬУРГчПФМбёЯЎЈ
d. ФЪН·Зэ¶ЇµДѕд·Ё·ЦОцДЈРНЦРЅвѕцКэѕЭПЎКиОКМвКЗМбёЯѕд·Ё·ЦОцРФДЬµД№ШјьЎЈАыУГТАґж№ШПµЎў»ҐРЕПў¶ФґКѕЫАаЈ¬ЅПєГµШЅвѕцБЛКэѕЭПЎКиОКМвЎЈ
ІОїјОДПЧЈє
[1] Manning C D, Schutze H. Foundations of statistical natural language processing[M]. London: The MIT Press, 1999.
[2] ЦУТеРЕ. №ШУЪЎ°РЕПўЎЄЦЄК¶ЎЄЦЗДЬЧЄ»»№жВЙЎ±µДСРѕї[J]. µзЧУС§±Ё, 2004, 32(4): 601-605.
ZHONG Yi-xin. A study on informationЎЄknowledgeЎЄintelligence transformation[J] Chinese Journal of Electronics, 2004, 32(4): 601-605.
[3] Chelba C, Jelinek F. Structured language modeling[J]. Computer Speech and Language, 2000, 14(4): 283-332.
[4] XUE Nian-wen, XIA Fei, CHIOU Fu-dong, et al. The Penn Chinese treebank: Phrase structure annotation of a large corpus[J]. Natural Language Engineering, 2005, 11(2): 207-208.
[5] Fung P, Ngai G, YANG Yong-sheng, et al. A maximum-entropy Chinese parser augmented by transformation-based learning[J]. ACM Trans on Asian Language Processing, 2004, 3(2): 159-168.
[6] Goodman J T. A bit of progress in language modeling[J]. Computer Speech and Language, 2001, 10: 403-434.
[7] ХФ ѕь, »ЖІэДю. єєУп»щ±ѕГыґК¶МУпЅб№№·ЦОцДЈРН[J]. јЖЛг»ъС§±Ё, 1999, 22(2): 141-146.
ZHAO Jun, HUANG Chang-ning. The model for Chinese basenp structure analysis[J]. Chinese Journal of Computers, 1999, 22(2): 141-146.
[8] ГП ТЈ, Ао Йъ, ХФМъѕь, µИ. ЛДЦЦ»щ±ѕНіјЖѕд·Ё·ЦОцДЈРНФЪєєУпѕд·Ё·ЦОцЦРµДРФДЬ±ИЅП[J]. ЦРОДРЕПўС§±Ё, 2003, 17(3): 1-8.
MENG Yao, LI Sheng, ZHAO Tie-jun, et al. A comparative study of four primary statistical models in Chinese parsing[J]. Journal of Chinese Information Processing, 2003, 17(3): 1-8.
[9] СоїЄіЗ. Т»ЦЦ»щУЪѕд·ЁУпТеМШХчµДєєУпѕд·Ё·ЦОцЖч[J]. ЦРОДРЕПўС§±Ё, 2000, 14(3): 46-53.
YANG Kai-cheng. A syntax parser based on syntax-semantic properties[J]. Journal of Chinese Information Processing, 2000, 14(3): 46-53.
[10] Collins M. Head-driven statistical models for natural language parsing[D]. Pennsylvania: The University of Pennsylvania, 1999.
[11] Seo K J, Nam K C, Choi K S. A probalistic model of the dependency parse of the variable-word-order languages by using ascending dependency[J]. Computer Processing of Oriental Languages, 2000, 12(3): 309-322.
[12] Lee L. Similarity-based approaches to natural language processing[D]. Cambridge, MA: Harvard University, 1997.
[13] GAO Jian-feng, Goodman J, MIAO Jiang-bo. The use of clustering techniques for language modelЎЄApplication to Asian language[J]. Computational Linguistics and Chinese Language Processing, 2001, 6(1): 27-60.
[14] Ф¬АпіЫ. »щУЪёДЅшµДТюВн¶ыїЖ·тДЈРНµДУпТфК¶±р·Ѕ·Ё[J]. ЦРДПґуѧѧ±Ё: ЧФИ»їЖС§°ж, 2008, 39(6): 1303-1308.
YUAN Li-chi. A speech recognition method based on improved hidden Markov model[J]. Journal of Central South University: Science and Technology, 2008, 39(6): 1303-1308.
КХёеИХЖЪЈє2009-03-23Ј»РЮ»ШИХЖЪЈє2009-06-12
»щЅрПоДїЈє№ъјТЧФИ»їЖС§»щЅрЧКЦъПоДї(60763001Ј¬60663007)Ј»ЦРДПґуС§І©КїєуїЖС§»щЅрЧКЦъПоДї(2007Дк)
НЁРЕЧчХЯЈєФ¬АпіЫ(1973-), ДРЈ¬єюДПЙЫСфИЛЈ¬І©КїЈ¬ё±ЅМКЪЈ¬ґУКВЧФИ»УпСФґ¦АнУлУпТфК¶±рСРѕїЈ»µз»°Јє13576126095Ј»E-mail: yuanlichi@sohu.com

