Gait recognition based on Wasserstein generating adversarial image inpainting network
来源期刊:中南大学学报(英文版)2019年第10期
论文作者:夏利民 王浩 郭炜婷
文章页码:2759 - 2770
Key words:gait recognition; image inpainting; generating adversarial network; stacking automatic encoder
Abstract: Aiming at the problem of small area human occlusion in gait recognition, a method based on generating adversarial image inpainting network was proposed which can generate a context consistent image for gait occlusion area. In order to reduce the effect of noise on feature extraction, the stacked automatic encoder with robustness was used. In order to improve the ability of gait classification, the sparse coding was used to express and classify the gait features. Experiments results showed the effectiveness of the proposed method in comparison with other state-of-the-art methods on the public databases CASIA-B and TUM-GAID for gait recognition.
Cite this article as: XIA Li-min, WANG Hao, GUO Wei-ting. Gait recognition based on Wasserstein generating adversarial image inpainting network [J]. Journal of Central South University, 2019, 26(10): 2759-2770. DOI: https://doi.org/10.1007/s11771-019-4211-7.

J. Cent. South Univ. (2019) 26: 2759-2770
DOI: https://doi.org/10.1007/s11771-019-4211-7
XIA Li-min(夏利民), WANG Hao(王浩), GUO Wei-ting(郭炜婷)
School of Automation, Central South University, Changsha 410075, China
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2019
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2019
Abstract: Aiming at the problem of small area human occlusion in gait recognition, a method based on generating adversarial image inpainting network was proposed which can generate a context consistent image for gait occlusion area. In order to reduce the effect of noise on feature extraction, the stacked automatic encoder with robustness was used. In order to improve the ability of gait classification, the sparse coding was used to express and classify the gait features. Experiments results showed the effectiveness of the proposed method in comparison with other state-of-the-art methods on the public databases CASIA-B and TUM-GAID for gait recognition.
Key words: gait recognition; image inpainting; generating adversarial network; stacking automatic encoder
Cite this article as: XIA Li-min, WANG Hao, GUO Wei-ting. Gait recognition based on Wasserstein generating adversarial image inpainting network [J]. Journal of Central South University, 2019, 26(10): 2759-2770. DOI: https://doi.org/10.1007/s11771-019-4211-7.
1 Introduction
Gait recognition is a long-range biometric identification technology. Compared with other biometric methods, such as face recognition, fingerprint recognition and iris recognition, it has great potential due to the advantages of long-distance recognition and difficult camouflage. In recent years, it has attracted more and more attention in the field of machine vision.
In general, gait recognition methods can be classified into two categories: one is model-based method, and the other is appearance-based method.
The model-based method used the parameters taken from the body structure and the motion data of different parts to build model. For example, DENG et al [1] used a five-link model to simulate the human body and extract the joint angles as features for classification. LU et al [2] extracted the positions of each joint from the silhouettes according to the proportion of the human body and calculated the joint angles as features for classification. FRANCESCO et al [3] obtained human skeleton graph by skeletonization and polygonal approximation, and then classified by LSTM network. The Kinect camera was used to extract the joint points for constructing the body model [4, 5]. This method has high requirement for the collection of images, so it cannot be used widely. LOPEZ-FERNANDEZ et al [6] reconstructed a three-dimensional gait model from multiple perspectives and intercepted two-dimensional gait silhouettes for analysis. LUO et al [7] used multi-view gait silhouettes to construct 3D gait model and extracted the motion data to construct features dictionary for classification.
Through the model-based methods, the movement relations and the changes of various parts of the human body can be well expressed, and the relations between frames also can be well reflected. Theoretically, it can achieve a good recognition rate, but the calculation is complex, and the positions of the human joint points are determined by proportion of body, so the model-based methods are limited.
Most of the current methods are focused on appearance. One of the most common methods is the gait energy image (GEI) which was used by LI et al [8]. It was obtained by averaging the gait silhouettes in one period. Then the gait features are extracted and classified on it. This method is simple, effective but vulnerable to the changes in appearance. DAS CHOUDHURY et al [9] proposed an average gait key-phase image, which is obtained by five key-phases. AMER et al [10] proposed an edge-masked active energy image as a gait representation which had removed the appearance change parts in the image. YU et al [11] used a stacked automatic encoder to transfer gait energy images of different visual angles and appearances to a normal gait energy image which corresponded to the angle of 90° in normal walking. WU et al [12] used a similar learning convolutional network to extract features of two gait energy images with different visual angles or appearances, and identified whether they are the same individual. These model-free gait representation methods are the trade-off of computational complexity and recognition performance which are widely used in gait recognition, and the recognition rate has been improved. However, the appearance-based methods are easily affected by the appearance changes, especially the part occlusions will cause some effective information to be loss in the walking process which will reduce the recognition rate.
In order to solve the occlusion problem during walking, PRATIK et al [13] captured the front and back views of each subject by Kinect camera, then extracted features from them, which cannot repair the missing information and relies on equipment. Therefore, the methods of repairing the missing area are currently under consideration. For example, XIE et al [14] proposed an approach which combined with sparse encoding and de-noising encoder to repair images, but the silhouettes contain unique pedestrian walking posture which cannot get through other parts by the image synthesis. PATHAK et al [15] proposed a CNN-based image context information encoding and decoding network, which can repair the images according to the unshielded part. YEH et al [16] used generating adversarial network to generate images that are consistent with the context.
In this paper, a gait silhouette inpainting approach is proposed. Firstly, the Wasserstein generating adversarial network (WGAN) is trained to generate the gait silhouettes consistent with the training database. Secondly, the hidden variable z in the generator is optimized with the occlusion silhouettes, so that the generator can generate a complete silhouette which is similar with the occlusion one. Then the occlusion area is replaced by the corresponding area of the generated silhouette. After repairing the silhouettes, the gait energy images are calculated and the motion features are extracted by the stacking automatic encoder. Finally, the features are sparse encoded and reconstructed, which are classified according to the reconstruction error.
The main contributions of this article include: 1) aiming at the problem of partial occlusion of the human body during walking, the Wasserstein generating adversarial network is used for gait silhouettes inpainting; 2) the stacked automatic encoder is used to extract the gait features, which is more robust; 3) the sparse representation of gait feature is constructed and the classification of gait energy image is realized according to the reconstruction error, which can improve the ability of gait classification.
2 Inpainting of gait silhouettes by WGAN
In order to solve the problem of partial occlusion of the human body during walking, the WGAN is used as an inpainting network. Firstly, the network is trained by complete gait silhouettes, so that it can generate the gait silhouettes which are close to the real one. Then, the hidden variable z in the generator is optimized by the occlusion gait silhouettes, so that the generated gait silhouette will be similar with the occlusion one. Finally, the corresponding area in the generated silhouette is extracted as an inpainting image.
2.1 Generative adversarial networks
Generative adversarial network (GAN) is a generation model proposed by GOODFELLOW et al [17] in 2014. Unlike the traditional generative models, it not only includes a generation network G, but also includes a discrimination network D, as is shown in Figure 1. The generation network G is used to generate the sample G(z) which obeys the distribution probability Pdata of real data x from random noise z. And the discrimination network D is used to discriminate whether the input sample is the real data x or the generated data G(z). Among them, G and D can be nonlinear mapping functions.
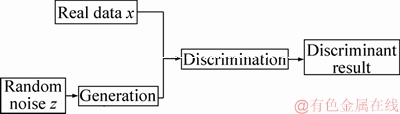
Figure 1 Flow chart of generative adversarial networks
The optimization goal of generative adversarial networks is:
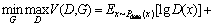
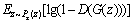 (1)
(1)
where E(・) represents the expectation calculation; x represents the real data with a distribution probability of Pdata(x); z is sampled in prior distribution pz(z).
In the generative adversarial networks, D represents the discrimination network and D(x) represents the probability that the sample is judged as a real sample; G represents the generation network and G(z) represents the generated sample from the noise z through the network G. According to the above, D(G(z)) represents the probability that the generated samples are judged as real samples by the discrimination network. Therefore, the generation network is used to make the sample closer to the real sample, which will make D(G(z)) closer to 1 by optimizing G. On the other hand, the purpose of the discrimination network is used to distinguish the generated samples, which will make D(G(z)) closer to 0 by optimizing D.
2.2 Wasserstein generating adversarial network
When training GAN, the generator will lose its gradient due to the good performance of the discriminator. In order to solve the problem of the disappearance of training gradient, the Wasserstein GAN was proposed, which proved that the Jensen-Shannon divergence of the objective function is a constant when there is little or no overlap between the distribution of real sample and the generated sample, which resulting in discontinuation of the optimization goal [18]. And they used the Wasserstein distance instead of Jensen-Shannon divergence to measure the distance between the distribution of the real sample and the generated sample. But the WGAN does not change the structure of the GAN model, only improved the optimization method to make the model train easier. In order to make the image in painting network easier to train, we also use the network based on WGAN for gait silhouettes in painting.
Due to the wide use of 100-dimensional noises [19, 20], we also use 100-dimensional noises from a uniform distribution between [-1, 1] for image generation, which is represented as 100z in Figure 2. Figure 2 shows the structure of the networks: the generation network consists of a fully connected layer (FC) with 512×4×6 neurons, followed by five convolutional layers, which have 512, 256, 128, 64 and 1 filter respectively. The size of filter is 5×5, and the stride is 2 pixels. The structure of discrimination network is symmetry with the generation network, but the fully connected layer has only one neuron.
The definition of the Wasserstein distance is:
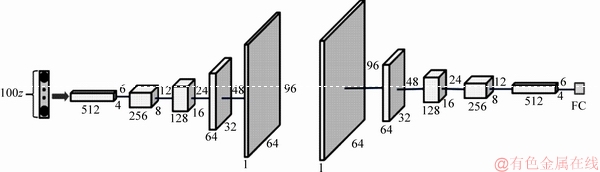
Figure 2 Model diagram of generative adversarial network
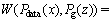
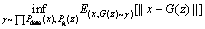 (2)
(2)
where pg(z) represents the distribution of the generated data;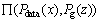 is a set of all possible joint probability distributions γ with Pdata(x) and Pg(z); W(Pdata(x), Pg(z)) represents the lower bound of expectation γ(x, G(z)), which indicates the distance of moving Pg(z) to Pdata(x). However, it is difficult to directly calculate the distance between arbitrary distributions, so the dual form of Kantorovich-Rubinstein is considered as follows:
is a set of all possible joint probability distributions γ with Pdata(x) and Pg(z); W(Pdata(x), Pg(z)) represents the lower bound of expectation γ(x, G(z)), which indicates the distance of moving Pg(z) to Pdata(x). However, it is difficult to directly calculate the distance between arbitrary distributions, so the dual form of Kantorovich-Rubinstein is considered as follows:
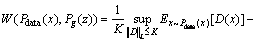
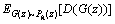 (3)
(3)
where D(x) is a function that satisfies the K-Lipschitz continuum arbitrarily and first derivative of D(x) has the upper limit. The discrimination network D is determined by discrimination network parameter θD, and the generation network G(z)z~Pz is determined by generation network parameter θG. The optimal function of the discrimination network can be obtained:
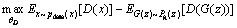 (4)
(4)
And the optimization function of the generation network is:
 (5)
(5)
In order to satisfy the constraint of the K-Lipschitz continuous (||D||L≤K) function, all the generation network’s weights are limited to a certain range [-c, c], and updated using the RMSProp [21] optimization algorithm after each gradient update. When training the discrimination network, the parameters of the generation network are fixed; the process of generator network training is similar, as shown in algorithm 1.
Algorithm 1 Training image inpainting network
Input. z: the hidden variable; T: training database; b: batch size;a: learning rate; c: gradient clipping parameters of discriminator network; K: the number of discriminator network updates in the generator network optimization process.
Output. θD: the parameters of the discrimination network; θG: the parameters of the generation network.
1:
Random initializing θD and θG;
2:
Repeat
3:
For t=0 to K do
4:
Sampling b samples zi from distributed
N(0,1);
5:
Sampling b samples xi from training
set T;
6:
Calculation of loss function of discriminator LD;
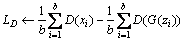
7:
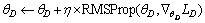
8:
if ||θD||≥c then
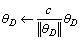
9:
end if
10:
end for
11:
Sampling b samples zi from N(0,1);
12:
Calculating loss function of generator LG;
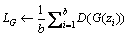
13:
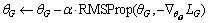
14:
Until discriminator network convergence.
2.3 Inpainting of gait silhouettes
Firstly, the silhouettes of the pedestrians are extracted from the video by the background subtraction method. And then a circumscribed rectangle is drawn according to the outline with the size of H×W. In order to maintain the ratio of the silhouettes and adjust to the same size, the image is expanded to 64×96 pixels from the center axis with the pixels of extended part is 0, as shown in Figure 3.

Figure 3 Three different gait silhouettes
Before training the inpainting network, we assumed that we had already known the location of the occlusion. The occlusion image is formed by multiplying a binary mask matrix which has the same size 64×96 with the corresponding point of the original image. Element 0 in the matrix corresponds to the occluded part in Figure 3, and element 1 is the unshielded part. For silhouette in painting, the occlusion image and the mask matrix Ma are used as the input of the inpainting algorithm.
The real loss function is shown as Eq. (6):
Lr=D(G(z, θG)) (6)
where z~N(0, 1) represents the input data of the generator; G(z, θG) represents the binarized gait silhouettes which is generated by the generator;D(・) indicates that the discriminator judges the probability of the input picture as the real picture. During the continuous training of the network, the generated images are getting closer to the real pictures in the training database. Secondly, in order to repair the binarized gait silhouettes, we define the similar loss on the unshielded area of the original image:
Ls=δ(G(z; θG) Θ(1-Ma), x Θ(1-Ma)) (7)
where δ(・) denotes using L2 norm to measure similarity between matrices; x represents the original gait silhouettes; Ma represents a binary mask matrix; Θ denotes the Hadamard product of the matrix Ma and the corresponding point of the original image. The overall optimization goal is:
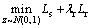 (8)
(8)
where λr represents the weight of real loss.
When repairing the silhouettes, the parameters of the generation network and discrimination network are fixed. Meanwhile, the hidden variable z is optimized by Eq. (8). Finally, the repaired image 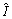 consists of the occlusion image and the generated image in the occlusion area. Algorithm 2 shows the process.
consists of the occlusion image and the generated image in the occlusion area. Algorithm 2 shows the process.
 xΘMa+G(z; θG)Θ(1-Ma) (9)
xΘMa+G(z; θG)Θ(1-Ma) (9)
Algorithm 2 Inpainting algorithm of gait silhouettes
Input. z: the hidden variable; P: gait silhouettes; M: mask matrix set; θD: trained discrimination network parameters; θG: trained generation network parameters; lr: weight of real loss;a: learning rate; K: optimizing the number of updates of hidden variables z.
Output. P: the repaired set of images.
1:
Sampling b samples zi from N(0,1);
2:
For k=0 to K do
3:
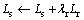
4:
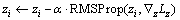
5:
End for
6:
For all 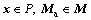 do
do
7:
 xΘMa+G(z; θG)Θ(1-Ma)
xΘMa+G(z; θG)Θ(1-Ma)
8:
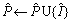
9:
End for
Gait energy image is the average of all gait silhouettes in one period, which has good recognition and robustness to noise. Therefore, after repairing the image data set  gait energy images should be calculated.
gait energy images should be calculated.
At the t moment, the binary gait silhouette in the gait sequence can be represented by 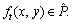 Then the gait energy images (GEI, Ige) can be expressed as:
Then the gait energy images (GEI, Ige) can be expressed as:
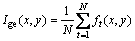 (10)
(10)
where N represents the total frame number of a complete gait period; x and y are the coordinate values of the image. The gait cycle is determined according to the walking step length.
3 Gait features extraction based on stacked automatic encoder
There are some noises on the binarized gait silhouettes generated by the generating adversarial image inpainting network, so the stacked automatic encoder with robustness is used to extract feature.
3.1 Automatic encoder
The automatic encoder is composed of the input layer, hidden layer and output layer. Compared with the traditional neural network, the input and output layers of the automatic encoder have the same size. It can encode the input data, that is feature extraction, and recover encoded features into raw data. We can train the connection weight parameters by the back-propagation algorithm with the input data as the labels. As shown in Figure 4, it is the structure of automatic encoder. The bottom half of the structure symmetry is called encoder, and the upper half is called a decoder.
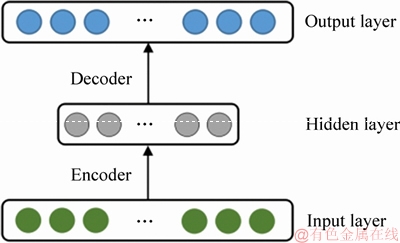
Figure 4 Structure of automatic encoder
The encoder can convert the data into a new representation in the hidden layer which is usually composed of linear and non-linear transforms:
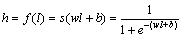 (11)
(11)
where f(・) represents coding function; w represents weight; b represents bias; s(・) is non linear activation function; l represents gait energy image.
The decoder can transform the features of hidden layer into raw data:
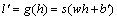 (12)
(12)
where g(・) represents decoder; w' represents weight; b' represents bias. The automatic encoder network is trained by stochastic gradient descent algorithm, and its cost function is the mean square error function:
 (13)
(13)
where li represents the i-th training sample; l′i is the corresponding output of li.
The features of input data can be obtained through encoder which is mapping data to the feature space by encoder. Then, the input data can be reconstructed by the decoder, and the encoded data in the feature space can be restored to the sample space. The training process of automatic encoder is used to find the optimal network parameters for encoding and reconstructing data.
3.2 Feature extraction based on stacked automatic encoder
Because the ability of single layer encoder to extract features is limited, the feature extraction method in this paper is stacking multiple automatic encoders to form stacked automatic encoders. After the stacked automatic coder is trained from the bottom to the top layer, the network can only retain the coded part of the network to extract the feature from the input data which have good anti- interference performance.
In this paper, we extract features from gait energy images for classification. The input data of encoder are the gait energy images with size as 64×96. Then the number of nodes with each layer gradually decreases until the bottleneck hidden layer, and the output of which are used as the recognized features. In the experiment, when the number of layers is 5, the detection rate is the highest, and the number of hidden nodes is 1000, 500, 250, 125 and 75, respectively. Therefore, the feature dimension of a gait energy image is 75 dimensions. The structure of the decoder is symmetrical with the encoder structure. After training, only the encoder part is used for feature extraction.
4 Feature representation and classification
As an accurate and effective classification algorithm, the sparse representation algorithm is widely used for image classification. The core idea of the algorithm is to construct the test sample by the linear combination of all training samples and seek the sparser coefficient for the test samples. In this paper, the advantages of deep learning in feature extraction and the advantages of sparse representation in image classification are fully combined.
4.1 Sparse representation algorithm
In the section 3, the stacked automatic encoder is used to extract the 75-dimensional feature vectors from gait energy images. Therefore, the feature sets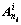 of the i-th sample can be obtained, where ni represents the number of gait energy images of the i-th sample and Ai represents the feature vector of the gait energy images of class i.
of the i-th sample can be obtained, where ni represents the number of gait energy images of the i-th sample and Ai represents the feature vector of the gait energy images of class i.
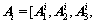 …,
…, 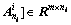 (14)
(14)
Then the training feature matrix A can be obtained:
A=[A1, A2, A3, …, Ai, …, Ak]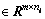 (15)
(15)
where N=Σni; m represents the dimension of the feature vector which is 75; k represents the number of test objects.
The test gait energy images are processed in the same way, and the corresponding test sample feature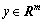 will be obtained. Then the process to solve the sparse expression y=Cα of test sample feature y as follows:
will be obtained. Then the process to solve the sparse expression y=Cα of test sample feature y as follows:
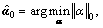 s.t. y=Cα (16)
s.t. y=Cα (16)
where C is the dictionary which initializes by feature set A; α represents the sparse coefficient.
Here, 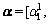 …,
…,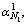 …,
…,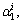 …,
…,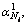 …,
…,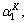 …,
…,  denotes the sparse linear representation of y;
denotes the sparse linear representation of y; 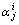 is the sparse coding coefficient that is associated
is the sparse coding coefficient that is associated
with the j-th training gait video of the i-th human. However, the solution of Eq. (16) is difficult. According to the compressed sensing theory, when the coefficients are sparse enough, the NP problem of minimizing the l0 norm can be transformed to the following formula, where λ1 is the control parameter:
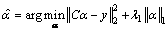 (17)
(17)
In order to solve the sparse coding coefficient α, the orthogonal matching pursuit algorithm [22] is used. However, the optimized sparse coefficient α cannot be obtained from the input features by the way of fixing dictionary. AHARON et al [23] proposed the K-SVD algorithm which can obtain a dictionary that allows all input vectors to be optimally represented. Therefore, the algorithm contains two parts: sparse coding and dictionary updating.
1) Constructing an initial dictionary C by random selecting K features from feature set A;
2) Fixing C and using orthogonal matching pursuit algorithm to solve α by 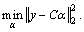 ;
;
3) Fixing α and the k-th atom of the dictionary and its corresponding column vector are separated as Eq. (19), then the zero elements in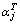 are deleted to obtain
are deleted to obtain 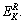
4) Applying SVD decomposition 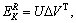 using the first column to update dictionary C and update the coefficient vector
using the first column to update dictionary C and update the coefficient vector with the first column of V multiplied △(1, 1).
with the first column of V multiplied △(1, 1).
5) Repeating the Steps 3, 4 until convergence, then outputting dictionary C and the sparse coefficient α.
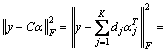
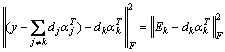 (18)
(18)
4.2 Feature reconstruction and classification
The residual error ri(y) of sparse reconstruction is calculated after obtaining the optimized sparse coding α of the test feature y through dictionary C. There, ri is the residual error of the i-th human, and
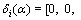 …,0,
…,0,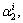 …,
…,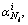 0, …, 0]T is a
0, …, 0]T is a
vector whose only nonzero entries are the entries in α that associated with i-th human.
If the reconstruction error is less than the threshold value ε, then this paper selects the sample with the smallest error as the last classification value:
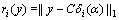 (19)
(19)
identity(y)=arg min ri(y), i=1, 2, …, k (20)
5 Experiments and results
In order to evaluate the performance of proposed method, the experiments were executed on the CASIA-B database and the TUM-GAID database. Then the method was compared with the other advanced methods to prove its effectiveness.
5.1 Introduction of databases
5.1.1 CASIA-B database
The database included 124 objects, each with 110 sequences which were taken in 11 angles (0°,18°,…, 180°). Among them, each object contains 10 sequences; six sequences were taken under normal walking conditions; two sequences were taken under the condition of wearing a coat; and the remaining two sequences were taken under the condition of the knapsack. In the experiment, we selected 124 recognition objects, and used the sequence of 90° normal walking sequences 1 and 2 as the sample sequence. 90° normal walking sequences 3, 4, 5, 6 were matched as the test sequences.
5.1.2 TUM-GAID database
The TUM-GAID database was recorded in two different time periods and contained 3370 walking sequences. There were 305 objects, 32 of which were recorded two times. Among them, each object had 2 kinds of sequences with backpack variation, 6 normal walking sequences and another 2 sequences with shoes variation.
We selected the normal walking sequence of 305 objects, in which the odd sequence direction of each object was from left to right, and the even sequence direction of walking was from right to left. In the experiment, the sequence 1 with direction from left to right was used as the sample, and the corresponding 3 and 5 were the test sequences; the sequence 2 with direction from right to left was used as the sample, and the corresponding 4 and 6 were the test sequences.
Firstly, the background subtraction method was used to extract the gait silhouettes of the pedestrians in the database. Figure 5(a) shows a binarized gait silhouettes extracted from the CASIA-B database and Figure 6(a) shows a binarized gait silhouettes extracted from the TUM-GAID database. Then the circumscribed rectangle was drawn according to the human body contour in the binarization image. Assume that the circumscribed rectangle size was H×W, and the clipped human binary contour part was scaled to 64×(96/H×W). Finally, the width of the 64×(96/H×W) image was expanded to 64 pixels with the central axis as the axis of symmetry, and the gray values of the extended portion were all 0. The image was finally normalized to an image with 64×96 pixels.
5.2 Image inpainting
In order to generate a masking gait binarization silhouettes, we need to set some mask matrix sets M with the same size as the silhouettes, and multiplied them with the corresponding pixel values of the silhouettes to obtain the masking silhouettes. In the experiment, we randomly set the masking matrixes M which has the same size, but the values in the matrix are different. In order to calculate the area conveniently, the occlusion area is set to a rectangle.
After the occlusive image was generated, the masking gait binarization silhouettes, the original images, and the corresponding masking matrixes were used to train the image inpainting network. The dimension of the hidden variable z was set to 100; the learning rate α was set to 0.00005; the loss of authenticity λr was set to 1.0; the batch size was set to 64; and the gradient clipping parameters c was set to 0.01.
Figure 5 shows the partial result of the experiment on the CASIA-B database, where Figure 5(a) represents a real image and the foreground objects; Figure 5(b) represents four kinds of mask matrices; Figure 5(c) represents four kinds of occlusive gait silhouettes; Figure 5(d) represents four repaired silhouettes with optimized for 50 times; and Figure 5(e) represents the final four repaired silhouettes.
Figure 6 shows the partial result of the experiment on the TUM-GAID database, where Figure 6(a) shows a binarized gait silhouettes extracted from the TUM-GAID database;Figure 6(b) represents four kinds of masking gait silhouettes; Figure 6(c) represents four repaired silhouettes with optimized for 50 times; and Figure 6(d) represents the final four repaired silhouettes.
In order to prove the validity of the methods, the experiment was compared with the following repaired methods:
1) XIE et al [14] proposed a combination of sparse coding and denoising autoencoder for image inpainting.
2) PATHAK et al [15] proposed a network based on CNN to encode and decode the context information of images, which can repair the images by combining image occlusive parts and other parts.
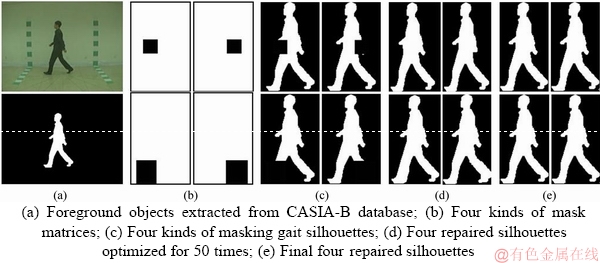
Figure 5 CASIA-B database:
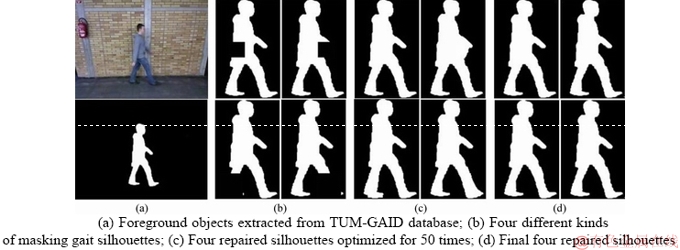
Figure 6 TUM-GAID database:
3) LI et al [24] proposed a generative image inpainting algorithm based on automatic encoder.
In order to evaluate the performance of this methods, the correct repaired area was defined as Scorrect as Eq. (21). And the ratio between the correct repaired area and the occlusive area was defined as Rcorrect and calculated by Eq. (22).
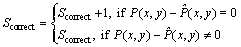 (21)
(21)
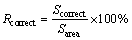 (22)
(22)
where P(x, y) represents the pixel at the point (x, y) of the real image; 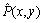 represents the pixel at the point (x, y) of the repaired image and
represents the pixel at the point (x, y) of the repaired image and 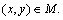 Sarea represents the area of occlusive parts.
Sarea represents the area of occlusive parts.
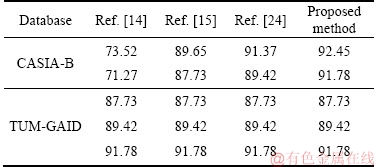
Table 1 shows the results of image inpainting by different methods on CASIA-B database and TUM-GAID database. The effect of image inpainting by generating adversarial image inpainting network is more prominent. Compared with the other three image inpainting methods, the Wasserstein generating adversarial network was used to generate the gait silhouettes which were more realistic. The method also set two loss items to measure image authenticity and context similarity, which further enhanced the quality of image inpainting. Therefore, the repaired images had less noises and were closer to the real gait silhouettes.
Table 1 Rcorrect value of different methods on CASIA-B database and TUM-GAID database (%)
5.3 Different feature extraction methods
In order to verify the robustness of automatic encoder, the experiments were executed by comparing with the following feature extraction methods on CASIA-B database and TUM-GAID database. Firstly, some interference noise should be added to the gait energy images. The automatic encoder needs to be trained to remove noise. Meanwhile, the encoder can not only encode the gait energy images, but also can restore the raw gait energy images through the decoder. The number of gait energy images to train was less. In order to expand the experimental data, we randomly rotated the existing datasets with the range between (±15°). During the learning process, the batch size was set to 64; the maximum number of iterations was 60000 and the learning rate was set to 0.01. The sparse representation of gait features was constructed after features extracting, and the gait energy images were classified according to reconstruction errors in the finally.
The experiments were executed by comparing with the following feature extraction methods to verify the robustness of automatic encoder.
1) LISHANI et al [25] extracted Haralick features on the gait energy images for identification.
2) ALOTAIBI et al [26] used convolutional neural networks to extract features from gait energy images.
3) KAREN et al [27] proposed a VGG neural network model for large-scale image recognition.
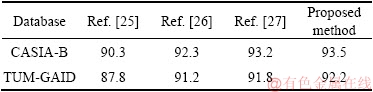
Table 2 shows that the encoder can extract the effective features with removing most of the interference noise after being trained from the bottom to the top layer. Compared with other feature extraction methods, the stacked automatic encoder has strong anti-interference and high robustness.
Table 2 Recognition rate of 4 methods with different feature extraction on CASIA-B database and TUM-GAID database (%)
5.4 Comparison with and without image inpainting
At present, there were no methods for repairing the occlusive area in gait silhouettes, so some other advanced gait recognition methods were selected to compare with the proposed method. The experiments contained two parts: the first part was used the advanced methods to experiment on the occlusive datasets; the second part was used the inpainting method to repair the gait silhouettes. And then compared the proposed method with the advanced methods which are as follow:
1) SHI [28] extracted gait features such as the heights, the stride widths and the joint angles which were classified by LMNN.
2) ZHANG et al [29] recognized gait information by capturing the change of the data during the gait sequence in a low dimensional tensor subspace space.
3) RIDA et al [30] proposed a supervised feature selection method to select relevant features to reduce the influence of covariates and improve the recognition performance.
4) CHEN et al [31] combined the method of sparse coding with evaluation model to improve the robustness of recognizing under different walking conditions.
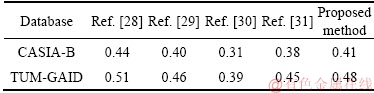
As seen from Figure 7, the proposed method can achieve better performance in the occlusion databases for gait recognition compared with other advanced methods. Firstly, methods in Refs. [28-31] only extracted the features of personal information on gait silhouettes or gait energy images, but the information of the missing part cannot be fully repaired, which caused some personal features to be lost, so the extracted information is incomplete. Especially for method in Ref. [28], there is a large error to extract the joints in occlusive gait silhouettes. In this paper, the Wasserstein generating adversarial network was used to generate the gait silhouettes, which were used to repair the image by extracting the corresponding area of the occlusion parts. It made a good repair to the missing information, so the extracted features are more complete.
Secondly, due to the existence of partial interference noise in the generated gait silhouettes, methods in Refs. [28-31] cannot remove the interference noise when extracting features. Therefore, the stacked automatic encoder was used to extract features in this paper, which can reduce the interference noise and extract the features with robustness. Moreover, the method gave full play to the advantage of sparse representation which can reconstruct the test object through fewer features, so it is better than other methods.
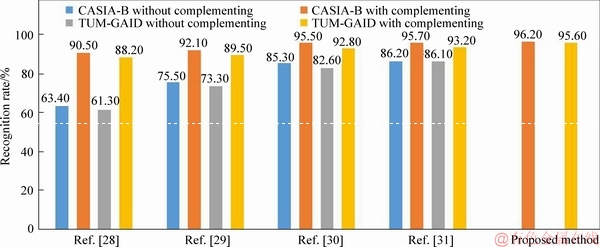
Figure 7 Comparison of different recognition methods on CASIA-B database and TUM-GAID database
5.5 Comparison of computational complexity
Finally, we trained the networks on an NVIDIA TitanX GPU and calculated the average computational complexity of the method on the CASIA-B database and TUM-GAID. Five methods were calculated the average time of features extraction and classification in the two databases respectively. It can be seen from Table 3 that the appearance-based methods were dissimilar in the recognition time, mainly caused by the differences in the process of extracting features. The features extracted method of the paper is based on the deep learning, and the size of the convolution kernel is strictly controlled, so the computation speed is fast relatively. And the computational cost of occlusion repainting was about 0.15 s, the computational cost of feature extraction was about 0.25 s and the computational cost of recognition was about 0.01 s.
Table 3 Computational complexity of five different methods on CASIA-B database and TUM-GAID database (s)
6 Conclusions
1) Aiming at the problem of partial occlusion of the human body during walking, the Wasserstein generating adversarial network is used to repair the occlusive gait silhouettes which made a good inpainting for the missing information.
2) The features of gait energy images are extracted by stacked automatic encoder with strong anti-interference, which are more robust.
3) The sparse representation algorithm is used to encode the gait features and the gait energy images are classified according to the reconstruction error, which can improve the ability of gait classification.
4) The CASIA-B database and TUM-GAID database are used to test the proposed method. And the experimental results demonstrate the effectiveness and feasibility of the method.
References
[1] DENG M, WANG C, CHENG F. Fusion of spatial-temporal and kinematic features for gait recognition with deterministic learning [J]. Pattern Recognition, 2017, 67: 186-200.
[2] LU W, ZONG W, XING W, BAO E. Gait recognition based on joint distribution of motion angles [J]. Journal of Visual Languages & Computing, 2014, 25(6): 754-763.
[3] FRANCESCO B, ALFREDO P. TGLSTM: A time based graph deep learning approach to gait recognition [J]. Pattern Recognition letters, 2019, 126(4): 132-138.
[4] SUN B L, ZHANG Z, LIU X Y, HU B, ZHU T S. Self-esteem recognition based on gait pattern using Kinect [J]. Gait & Posture, 2017, 58(3): 428-432.
[5] YANG K, DOU Y, LV S, ZHANG F, LV Q. Relative distance features for gait recognition with Kinect [J]. Journal of Visual Communication and Image Representation, 2016, 39: 209-217.
[6] LOPEZ-FERNANDEZ D, MADRID-CUEVAS F J, CARMONA-POYATO A, MUNOZ-SALINA S, MEDINA-CARNICER R. A new approach for multi-view gait recognition on unconstrained paths [J]. Journal of Visual Communication and Image Representation, 2016, 38(7): 396-406.
[7] LUO J, TANG J, TJAHJADI T, XIAO X. Robust arbitrary view gait recognition based on parametric 3D human body reconstruction and virtual posture synthesis [J]. Pattern Recognition, 2016, 60: 361-377.
[8] LI W, KUO J, PENG J. Gait recognition via GEI subspace projections and collaborative representation classification [J]. Neurocomputing, 2018, 275: 1932-1945.
[9] DAS CHOUDHURY S, TJAHJADI T. Clothing and carrying condition invariant gait recognition based on rotation forest [J]. Pattern Recognition Letters, 2016, 80: 1-7.
[10] AMER A T, KHALED A, SHANABLEH T. Decision-level fusion for single-view gait recognition with various carrying and clothing conditions [J]. Image and Vision Computing, 2017, 61: 54-69.
[11] YU S, CHEN H, WANG Q, SHEN L, HUANG Y. Invariant feature extraction for gait recognition using only one uniform model [J]. Neurocomputing, 2017, 239: 81-93.
[12] WU Z, HUANG Y, WANG L. A comprehensive study on cross-view gait based human identification with deep CNNs [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(2): 209-226.
[13] PRATIK C, SHAMIK S, JAYANTA M. Frontal gait recognition from occluded scenes [J]. Pattern Recognition Letters, 2015, 63: 9-15.
[14] XIE J, XU L, CHEN E. Image denoising and inpainting with deep neural networks [C]// 26th Annual Conference on Neural Information Processing Systems 2012. Lake Tahoe, Nevada: IEEE, 2012: 341-349.
[15] PATHAK D, KRAHENBUHL P, DONAHUE J, DARRELL T, EFROS A A. Context encoders: feature learning by inpainting [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016: 2536-2544.
[16] YEH R A, CHEN C, LIM T Y, SCHWING A G, HASEGAWA-JOHNSON M, DO M N. Semantic Image Inpainting with Deep Generative Models [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI: IEEE, 2017: 6882-6890.
[17] GOODFELLOW I J, POUGET A J, MIRZA M. Generative ad-versarial nets [C]// Proceedings of the 26th Annual Conference on Neural Information Processing Systems. Montreal, Canada: IEEE, 2014: 2672-2680.
[18] ARJOVSKY M, CHINTALA S, BOTTOU L. Wasserstein GAN [EB/OL]. [2018-07-18]. https://arxiv.org/abs/1701. 07875.
[19] LUO J, XU Y, TANG C, LV J. Learning inverse mapping by autoencoder based generative adversarial nets [C]// International Conference on Neural Information Processing. Germany: Springer, 2017: 207-216.
[20] MOHAMMAD A K, DENNIS S M, MINHO L. Coupled generative adversarial stacked auto-encoder: CoGASA [J]. Neural Networks, 2018, 100: 1-9.
[21] HINTON G, SRIVASTAVA N, SWERSKY K. Neural networks for machine learning: overview of mini-batch gradient descent [EB/OL]. [2018-07-18]. http://www.cs. toronto.edu/tijmen/csc321/slides/lectureslideslec6.pdf.
[22] WANG Jun, ZHOU Si-chao, XIA Li-min. Human interaction recognition based on sparse representation of feature covariance matrices [J]. Journal of Central South University, 2018, 25(2): 304-314.
[23] AHARON M, ELAD M, BRUCKSTEIN A. k-SVD: An algorithm for designing overcomplete dictionaries for sparse representation [J]. IEEE Transactions on Signal Processing, 2006, 54(11): 4311-4322.
[24] LI Y, LIU S, YANG J, YANG M. Generative face completion [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017: 5892-5900.
[25] LISHANI A O, BOUBCHIR L, KHALIFA E, BOURIDANE A. Human gait recognition based on Haralick features [J]. Signal Image and Video Processing, 2017, 11(6): 1123-1130.
[26] ALOTAIBI M, MAHMOOD A. Improved Gait recognition based on specialized deep convolutional neural networks [J]. Computer Vision and Image Understanding, 2017, 164: 103-110.
[27] KAREN S, ANDREW Z. Very deep convolutional networks for large-scale image recognition [C]// 3rd International Conference on Learning Representations. San Diego: ICLR, 2015: 178-184.
[28] SHI D K. Gait recognition algorithm research and application platform design based on human geometric characteristics [D]. Zhejiang: Zhejiang University, 2017. (in Chinese)
[29] ZHANG L, ZHANG L, TAO D, DU B. A sparse and discriminative tensor to vector projection for human gait feature representation [J]. Signal Processing, 2015, 106(C): 245 A.252.
[30] RIDA I, MAADEED S A, BOURIDANE A. Unsupervised feature selection method for improved human gait recognition [C]// 2015 23rd European Signal Processing Conference (EUSIPCO). Nice, New York, USA: IEEE, 2015: 1128-1132.
[31] CHEN X, XU J. Uncooperative gait recognition: Re-ranking based on sparse coding and multi-view hypergraph learning [J]. Pattern Recognition, 2016, 53:116-129.
(Edited by ZHENG Yu-tong)
中文导读
基于生成对抗图像补全网络的步态识别
摘要:针对步态识别中小面积人体遮挡问题,提出了一种基于Wasserstein GAN的图像补全网。该网络能够为图像中遮挡区域生成上下文一致的补全图像。为了减少噪声对特征提取的影响,采用具有鲁棒性的堆叠自动编码器进行特征提取。为了提高分类的能力,采用稀疏编码的方法对步态特征进行表示与分类。在公共数据集CASIA-B和TUM-GAID上对该方法进行了验证,并与其他方法进行了对比试验,结果表明了该方法的有效性。
关键词:步态识别;图像补全;生成式对抗网络;堆叠自动编码器
Foundation item: Project(51678075) supported by the National Natural Science Foundation of China; Project(2017GK2271) supported by Hunan Provincial Science and Technology Department, China
Received date: 2018-07-18; Accepted date: 2019-02-22
Corresponding author: XIA Li-min, PhD, Professor; Tel: +86-13974961656; E-mail: xlm@mail.csu.edu.cn; ORCID: 0000-0002-2249- 449X

