考虑多项定量描述指标的岩体结构面组数和间距研究
曹洋兵,晏鄂川,吕飞飞,李兴明
(中国地质大学(武汉) 工程学院,湖北 武汉,430074)
摘要:岩体结构面组数和间距是分析岩体结构类型、渗流特性及稳定性等的关键参数。基于迭代自组织数据分析技术算法,依据结构面数据处理的基本要求对其进行改进,再将模糊隶属度和模糊加权指数引入其中,并在欧氏距离和标准偏差2个关键算式中增加指标权重,构建起可考虑多项分组指标及其重要程度的结构面自组织模糊聚类分组模型。基于空间架构关系,推导该分组模型下的结构面间距计算式。利用C#语言对算法进行编程实现,开发DSSIA软件。结合山东某地下水封石油洞库工程,对分组指标的选择、指标权重的确定及算法参数的设置等问题进行了分析,计算结果体现了分组模型及间距算法的可靠性、必要性及优越性。
关键词:结构面组数;结构面间距;自组织聚类;模糊数学
中图分类号:P642.3 文献标志码:A 文章编号:1672-7207(2014)12-4348-07
Study on sets and spacing of rock mass discontinuity considering multiple indexes of quantitative description
CAO Yangbing, YAN Echuan, L Feifei, LI Xingming
Feifei, LI Xingming
(Faculty of Engineering, China University of Geosciences, Wuhan 430074, China)
Abstract: Discontinuities sets and spacing of rock mass are critical parameters in analyzing structure type, seepage property and stability of rock mass. Based on iterative self-organizing data analysis technique algorithm, a discontinuity grouping model named self-organizing fuzzy clustering was established. This model can consider multiple indexes of discontinuity quantitative description and their weights. For details of this model, firstly iterative self-organizing data analysis technique algorithm was improved according to basic requirements of discontinuities data treatment, secondly fuzzy membership and fuzzy weighted index were added to the improved algorithm, thirdly index weight was included in Euclidean distance equation and standard deviation equation. Based on space architecture relation, calculation formula of discontinuities spacing was given under the grouping model. Taking advantage of C# programming language, the above discontinuities sets and spacing algorithm DSSIA were developed. Combining with one underground water-sealing rock caverns for oil storage in Shandong Province, some key questions such as how to choose grouping index, how to determine index weighting, and how to set up algorithm parameters were analyzed. Calculation results show that the discontinuity grouping model and proposed spacing algorithm have reliability, necessity and superiority.
Key words: discontinuity set; discontinuity spacing; self-organizing clustering; fuzzy mathematics
国际岩石力学协会(ISRM)针对岩体结构面建议了10项定量描述指标及其调查方法[1],按各指标针对的对象看,产状、连续性、粗糙度、张开度、水流状况、充填状况和面壁抗压强度共7项只针对单个结构面,组数和间距则针对多个结构面,块体大小是由产状、连续性、组数和间距等综合确定。该建议所阐述的结构面组数是基于产状单因素而得,分组方法主要有玫瑰花图、极点等密度图和统计聚类等,Shanley等[2-4]对此进行了深入研究。为克服分组方法中存在的局部最优值问题,研究人员提出了基于变换群关系和性质的优势产状反演[5]、改进的产状表示方法[6]、在聚类算法中引入全局优化算法[7-9]等一系列改进方法。部分研究人员认为基于产状单指标的结构面分组不够准确和全面,也不利于工程应用,应选取更多的定量描述指标进行分组,Tokhmechi等[10-12]在该思路下进行了深入研究,取得了重大的进展。但在上述考虑多项指标的岩体结构面分组研究中仍未很好地解决以下3个问题:1) 结构面分组不仅是基于某种模型或算法将分组指标按某种程度的共性进行区分,而应该更多地是为岩体稳定性分析和灾害防治等提供依据和参考,即分组应具有目的性和针对性,因此,需要建立一个能考虑任意个数分组指标的普适性分组模型以适应不同的分组目标;2) 各分组指标对于某个分组目标的影响程度是不同的,且同一个分组指标对不同的分组目标的影响程度也是不同的,这需要在分组模型中予以考虑;3) 结构面间距是在同一结构面组内计算而得的。因此,在建立的多项指标分组模型中需要考虑各结构面的归属问题且避免同一组内的结构面产状差异悬殊。基于上述认识,本文作者建立考虑多项定量描述指标及其重要程度的结构面自组织模糊聚类分组模型,给出该模型下的结构面间距计算方法,并通过工程实例对分组指标的选择、指标权重的确定等问题进行阐述和讨论。
1 自组织模糊聚类分组模型
迭代自组织数据分析技术算法[13](ISODATA)因具有聚类中心的合并、分裂等功能而具有较好的自组织性、对初始聚类中心不敏感等优点,但也存在确定性的数据点归属计算而导致的聚类精度不高等问题。本文基于统计过程中不删除原始结构面数据的前提条件,首先对ISODATA算法进行改进;再引入模糊隶属度和模糊加权指数[14]以提高分组过程的自适应性;最后,增加分组指标的权重系数以考虑其对分组目标的影响程度,构建出具有普适性的结构面自组织模糊聚类分组模型,其基本流程如图1所示。
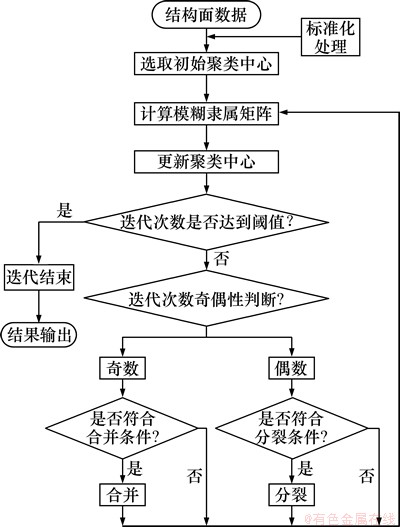
图1 自组织模糊聚类分组的流程图
Fig. 1 Flow chart of self-organized fuzzy clustering
分组模型的关键问题及主要步骤如下所述。
步骤1:分组指标的数据标准化。
采用归一化方式进行各分组指标的数据标准化处理。由于产状是倾向和倾角的组合表示而不同于其它分组指标,故对此采用不同的归一化方式。
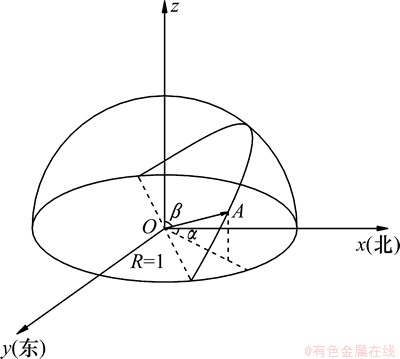
图2 结构面产状的单位法向量表征示意图(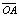 为结构面的单位法向量;α和β分别为结构面的倾向和倾角)
为结构面的单位法向量;α和β分别为结构面的倾向和倾角)
Fig. 2 Schematic diagram of unit normal vector of discontinuity orientation
采用结构面的单位法向量(图2)来表征其产状,其归一化方式如下:
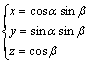 (1)
(1)
式中:x,y和z为单位法向量的坐标;α为倾向;β为倾角。
其他分组指标采用式(2)进行归一化处理。
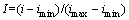 (2)
(2)
式中:i为指标归一化前的数值;I为指标归一化后的数值;imin为归一化前所有数值中的最小值;imax为归一化前所有数值中的最大值。
步骤2:分组模型中的指标权重。
在分组模型中引入指标权重以反映不同分组指标对于具体工程问题影响程度的差异,其具体体现在分组模型的欧氏距离(式(3))和标准偏差(式(9))中,并通过这2个核心算式影响整个分组模型。
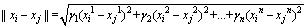 (3)
(3)
式中:||・||为欧氏距离;xi为编号为i的结构面;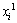 的上标1表示第1项分组指标;n为归一化后的指标总数,γ1,γ2和γn表示各项指标对应的权重。
的上标1表示第1项分组指标;n为归一化后的指标总数,γ1,γ2和γn表示各项指标对应的权重。
由于初始数据均经过归一化处理,因而指标权重对分组结果有重要影响;而指标权重绝对值对分组结果影响不大,只影响分组阈值和合并阈值的合理设置。当某项指标的权重与其他指标权重相对比例越大时,则欧氏距离和标准偏差的数值受该指标的影响越明显,导致该指标在分组中的重要性加强、对分组结果的影响越显著。
步骤3:选取初始聚类中心。
对于初始聚类中心的选择,在确定初始聚类中心数目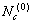 参数后,其具体流程为如下。
参数后,其具体流程为如下。
基于式(3),首先选取整个样本集中欧氏距离最大的2个点作为初始聚类中心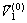 和
和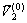 ,数学描述为
,数学描述为
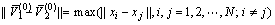 (4)
(4)
式中:N为总的结构面数目。
第3个初始聚类中心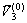 为其到和距离的较小值等于所有其余样本到和较小值的最大值,数学描述为
为其到和距离的较小值等于所有其余样本到和较小值的最大值,数学描述为
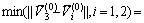
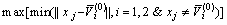 (5)
(5)
其余初始聚类中心的选取方法依此原则类推,直至选取个初始聚类中心为止。
步骤4:计算模糊隶属矩阵。
将FCM中模糊数学应用较为成功的形式[14]引用至改进后的ISODATA算法,再基于式(3),可得各结构面对于聚类中心的模糊隶属度为
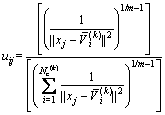 (6)
(6)
式中:uij为编号为j的结构面对于编号为i的聚类中心的隶属度; 为第k次迭代中的聚类中心数目;
为第k次迭代中的聚类中心数目;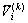 为第k次迭代中编号为i的聚类中心;m为模糊加权指数。
为第k次迭代中编号为i的聚类中心;m为模糊加权指数。
步骤5:更新聚类中心。
基于上述模糊隶属度及其形成的矩阵,聚类中心更新为
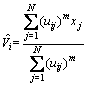 (7)
(7)
式中: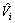 为更新后的编号为i的聚类中心。
为更新后的编号为i的聚类中心。
对于产状指标,在进行聚类中心更新后,需要按式(8)再次进行归一化处理,以保证其能被反归一化输出,即三维坐标需满足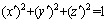 。
。
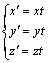 (8)
(8)
式中: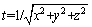 。
。
步骤6:判断是否达到设置的迭代次数,是则转步骤8;否则转步骤7。
步骤7:迭代步数为偶数时,判断是否符合分裂的条件,若符合则执行分裂(式(10)),然后转步骤4,不符合则直接转步骤4;迭代步数为奇数时,判断是否符合合并的条件,若符合则执行合并(式(11)),然后转步骤4,不符合则直接转步骤4。
分裂的条件为:若某项分组指标对于某聚类中心的标准偏差(式(9))大于设置的分裂阈值,则为符合分裂条件;若已有的组数大于2倍的期望组数,则不再执行分裂判断和操作。
 (9)
(9)
式中: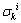 表示编号为k的聚类中心的第i项指标的标准偏差。
表示编号为k的聚类中心的第i项指标的标准偏差。
分裂的执行过程为:若某聚类中心的某项分组指标需要分裂,则该聚类中心的该指标数据以其标准偏差的一半而分成2个新的聚类中心,2新聚类中心的其余指标数据与原聚类中心相同(式(10))。若产状进行了分裂,则分裂后再按式(8)进行处理。
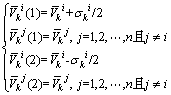 (10)
(10)
式中: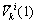 和
和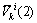 表示原第k个聚类中心分裂后,形成的2个新聚类中心编号为i的指标;
表示原第k个聚类中心分裂后,形成的2个新聚类中心编号为i的指标;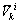 为原第k个聚类中心编号为
为原第k个聚类中心编号为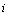 的需要分裂的指标;
的需要分裂的指标;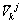 为原第k个聚类中心其余不需要分裂的指标。
为原第k个聚类中心其余不需要分裂的指标。
合并的条件为:若2个聚类中心的欧氏距离(同式(3))小于设置的合并阈值,则为符合合并条件。
合并的执行过程为:基于所有数据对2个需合并的聚类中心的隶属度和模糊加权指数进行加权求和,得出新的聚类中心(式(11))。针对产状特性,合并之后再按式(8)进行处理。
 (11)
(11)
式中: 为原2个需要合并的聚类中心(编号为l和k)合并而成的新聚类中心。
为原2个需要合并的聚类中心(编号为l和k)合并而成的新聚类中心。
步骤8:程序迭代结束,输出最终结果。
基于步骤(1),反归一化方式也对应地分为2类。对于产状,倾向的反归一化公式根据x和y取值的不同而不同,为式(12),倾角的反归一化为式(13)。对于其它分组指标,反归一化为式(14)。
 (12)
(12)
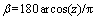 (13)
(13)
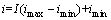 (14)
(14)
2 间距算法
同一组内2相邻结构面的垂直距离为结构面的间距(标量),通过空间方位关系,可将其转换为任意测线(或钻孔)方向上的方位间距[15](具有矢量特性),并通过线性叠加,可求得任意测线(或钻孔)方向上的多组结构面交切后的方位密度[16]、RQD取值等参数。由于上述结构面分组模型考虑了多项分组指标且采用模糊隶属度确定结构面归属,因而需要研究该分组模型下的间距算法,并反馈分析考虑多项指标进行分组的可行性、可靠性和优劣势。
间距算法的关键步骤如下所述。
步骤1:确定各结构面组及其所含的结构面。
根据式(6)所形成的矩阵,采用最大隶属度原则确定各结构面所归属的结构面组,即将结构面对于各聚类中心的隶属度数值进行排序,对某聚类中心隶属度都是最大值的结构面构成1组。各组的聚类中心即为该组结构面的优势特性。
步骤2:计算各组内结构面间距。
构建同图2的空间直角坐标系NEZ(xyz),建立结构面间距计算模型(图3)。两相邻结构面平均产状的单位法向量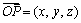 计算方式同式(1),测线产状的单位向量
计算方式同式(1),测线产状的单位向量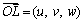 为
为
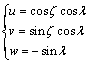 (15)
(15)
式中:ζ为测线的倾伏向,λ为测线的倾伏角。
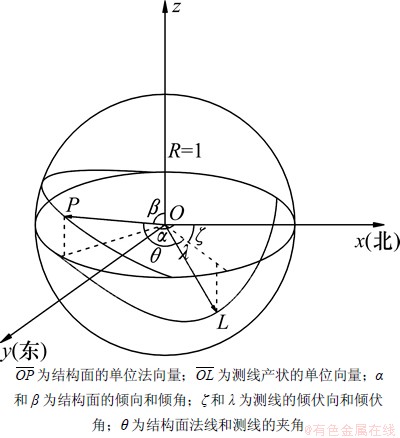
图3 结构面间距计算模型
Fig. 3 Calculation model of discontinuity spacing
假定θ为结构面的法向量与测线向量之间的夹角,则:
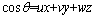 (16)
(16)
将式(1)和(15)代入式(16),可得:
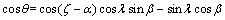 (17)
(17)
式中:α和β表示2相邻结构面的倾向平均值和倾角平均值。
由于结构面间距d总是正数,因而有
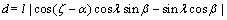 (18)
(18)
式中:l表示沿测线方向上2相邻结构面的距离,通过现场测量所记录的各结构面位置计算而得。
3 算法的程序化实现
基于Microsoft Visual Studio平台,利用C#语言对上述算法进行编程,开发DSSIA软件。其采用Microsoft Office Excel作为数据输入文件类型,根据工程问题的需要输入相应的指标名称、权重及数据;采用交互式操作方式,通过界面多选框实现分组指标的选择,下拉菜单和弹出菜单实现测线方位及其他算法参数的输入;通过界面表格、图形和文本文档等形式进行结果的输出。
4 地下岩体工程应用实例
山东某地下水封石油洞库位于牟平―即墨断裂带南缘,基岩为花岗岩和花岗片麻岩,区域主要发育走向为北东和近东西向的断裂,其中西侧为北东向的老君塔山断裂,东侧为北东向的孙家沟断裂,北侧为近东西向的前马连沟断裂。断裂分布对洞库位置起控制作用,在选址避开断裂的情况下,对洞库工程建设影响较大的是次级结构面(小断层、破碎带、节理等)。小断层主要有:F1,倾向南东,倾角为50°~55°;F2,倾向南东,倾角为68°;F3,倾向南东,倾角为53°~70°;F4,倾向北东,倾角为72°;F7,右旋走滑。破碎带主要有:F8,倾向北东,倾角为80°;F9,倾向南东,倾角为52°。
本文根据实例探讨如何应用上述分组模型和间距算法,并验证其可靠性、分析其优越性。选取地表半迹长测线法所得的数据量较少的第7条测线数据(表1)进行研究,但得出的应用准则可相应地应用于数据量大、指标复杂且多样的结构面分析中。该测线剖面所出露的岩性为细粒花岗片麻岩,剖面长度×宽度约为20 m×6 m,剖面产状为151°∠70°,测线产状为52°∠13°。
表1 现场测量和定量描述的结构面数据
Table 1 Discontinuities data of field measurement and quantitative description
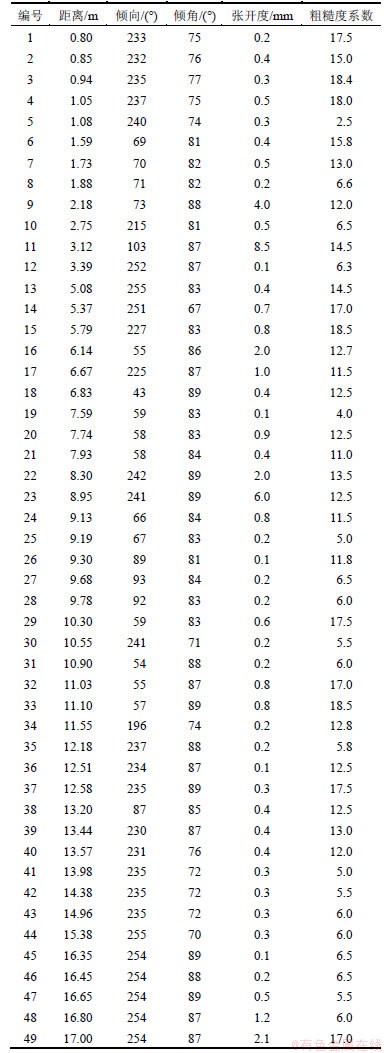
在考虑多项指标进行结构面分组的研究和应用时,并不是考虑的分组指标越多越好。原因在于考虑的指标越多,会得出过多的组数,有的不具有工程应用价值且存在同组内产状差异悬殊而无法合理计算间距等问题,因而在分组指标的选择上,应结合具体工程问题,抓住主控因素,合理地进行综合确定。
地下水封石油洞库的基本要求是控制围岩中的水压力,使其始终大于洞库储存介质的饱和蒸汽压。由此可知,场区水封条件、围岩稳定性等对工程具有决定性作用。根据光滑平行板模型的立方定律,张开度是影响岩体水力学特性的重要参数,且对于洞库涌水量、地下水位动态变化及降落漏斗规模等具有重要影响,并最终决定水幕系统的有效性、经济性和工程成败,因而是该工程在建设过程中需要重点关注和研究的参数。据现场调查,场区结构面基本未被充填,结构面两面壁被风化和蚀变的程度较轻,面壁抗压强度与新鲜岩石的近似,因而从Barton-Bandis抗剪准则和块体理论可知,围岩稳定性程度的区别主要在于粗糙度系数(JRC)和产状。据以上分析,该工程的结构面分组应该考虑产状、张开度和粗糙度系数这3个指标。
某分组指标的权重越大,则该指标在整个指标体系中的重要性越高,且分组结果受该指标的数据分布特性影响越大。因此,在确定指标权重时需要考虑以下2个基本原则:1) 为得到合理、准确的间距,需要适当增大产状的权重,在一般情况下,产状的权重是所有分组指标权重的最大值;2) 除产状外,其余分组指标按其对所分析的岩体工程问题影响程度赋值,影响越显著,权重相对越大。总体而言,指标权重需要结合岩体力学理论、工程问题和实践经验进行综合确定,且有时需要经过一定的试算和反馈调整以赋予较优的权重。本次确定的指标权重如下:产状为1.5,张开度为1.3,粗糙度系数为1.0。
在分组模型中含有的其它参数(自组织模糊聚类算法本身的参数)及取值方法如下:初始聚类中心数对最终的结果影响较小,一般取[2,5],由于本文算法具有较好的自组织性,因而该值对分组结果影响不显著;迭代次数由结构面数据规模及其统计特性决定,一般取200,在保证迭代达到稳定的条件下,增大该值对结果无影响;分裂阈值和合并阈值是保证算法自组织性和自适应性的关键,这2个阈值越小,则得出的组数越多,各组的内聚性越高,反之则组数越少,内聚性越低;期望组数控制着最终分组数量(不超过期望组数的2倍),一般岩体工程的取值范围为[2,5];模糊加权指数的合适取值范围为[1.5,2.5],在一般情况下取2.0是最优选择。本次设置情况如睛:初始聚类中心数为3,迭代次数为200,分裂阈值为0.2,合并阈值为0.15,期望组数为3,模糊加权指数为2.0。
在间距算法中还需要输入的参数为测线产状(本例为52°∠13°)和结构面在测线上的位置(表12),这2个参数为结构面调查中所记录的数据。根据以上分析和参数设置,得出的结果如表2所示。
表2 结构面组数和间距计算结果
Table 2 Calculation results of discontinuity sets and spacing

通过DIPS软件进行只考虑产状的结构面分组,结果如图4所示。对比表2和图4可知,各组的优势产状及优势程度(各组含有的结构面数量)相当接近,表明本文分组模型及间距算法是可靠的,编制的程序是正确的。同时,由于产状与其他特性(如张开度、JRC等)之间的相关性及相关程度等问题目前还无明确结论,因而图4也表明只采用产状进行分组的缺点,即产状相当接近甚或可能被划分为同一组的结构面,可能在其它特性上存在巨大差异,只有采用多项指标进行分组才能显示这种差别、区分各结构面。
在组数划分中考虑某项指标的实质效果为,使得该指标在结构面组内的内聚性增强,在分组过程中的重要性增加。对于本工程实例而言,在用关键块体理论和Barton-Bandis准则进行洞库围岩局部稳定性分析时,由于各结构面组在面壁抗压强度上差别甚微,则在表2所示的分组结果下,可输入更准确的抗剪强度参数和更合理地判识块体稳定性状况;在用Snow模型计算岩体渗透张量时,若在表2的组数和间距结果下进行计算,则可对渗透张量进行更准确表达。上述分析表明考虑多项定量描述指标进行结构面组数和间距研究的必要性及优越性。
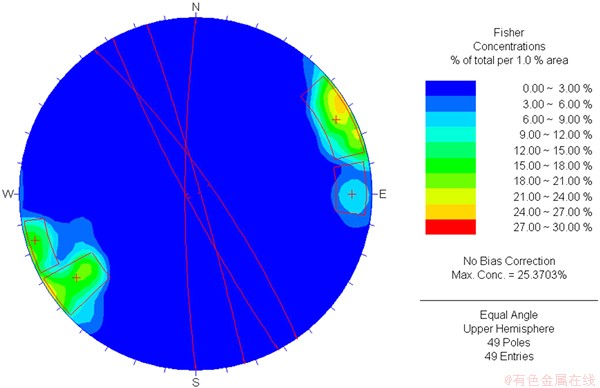
图4 结构面产状等密度图
Fig. 4 Isodensity graph of discontinuity orientation
5 结论
1) 对迭代自组织数据分析技术算法进行改进,并将模糊隶属度、指标权重等引入其中,构建的可考虑多项指标及其重要程度的自组织模糊聚类分组模型及其间距算法具有优越性和较高的可靠性。
2) 在分组模型的欧氏距离和标准偏差这2个核心算式中考虑指标权重是合理的,可通过这2个算式影响整个分组结果,其中权重相对越大表明该指标的重要性增强,对分组结果影响越显著。
3) 在分组中考虑某项指标的实质效果为使其在结构面组内的内聚性增强,且在分组指标的选择上并非越多越好,应结合具体岩体工程问题和岩石力学理论进行综合确定。
4) 在确定指标权重时应考虑的2个基本原则为:一般情况下,产状的权重是所有分组指标权重的最大值;其余分组指标按其对所分析的岩体工程问题影响程度赋值,影响越显著,赋值便越大。
参考文献:
[1] International Society for Rock Mechanics Commission on Standardization of Laboratory and Field Tests. Suggested methods for the quantitative description of discontinuities in rock mass[J]. International Journal of Rock Mechanics and Mining Science & Geomechanics Abstracts, 1978, 15(6): 319-368.
[2] Shanley R J, Mahtab M A. Delineation and analysis of clusters in orientation data[J]. Mathematical Geology, 1976, 8(3): 9-23.
[3] Hammah R E, Curran J H. On distance measures for the fuzzy K-means algorithm for joint data[J]. Rock Mechanics and Rock Engineering, 1999, 32(1): 1-27.
[4] 范雷, 王亮清, 唐辉明. 节理岩体结构面产状的动态聚类分析[J]. 岩土力学, 2007, 28(11): 2405-2408.
FAN Lei, WANG Liangqing, TANG Huiming. Dynamic cluster analysis of discontinuity orientations of joint rock mass[J]. Rock and Soil Mechanics, 2007, 28(11): 2405-2408.
[5] 王渭明, 李先炜. 裂隙岩体优势结构面产状反演[J]. 岩石力学与工程学报, 2004, 23(11): 1832-1835.
WANG Weiming, LI Xianwei. Inverse study on occurrence of dominant texture plane in jointed rock masses[J]. Chinese Journal of Rock Mechanics and Engineering, 2004, 23(11): 1832-1835.
[6] 陈剑平, 石丙飞, 王清. 工程岩体随机结构面优势方向的表示法初探[J]. 岩石力学与工程学报, 2005, 24(2): 241-245.
CHEN Jianping, SHI Bingfei, WANG Qing. Study on the dominant orientation of random fractures of fractured rock masses[J]. Chinese Journal of Rock Mechanics and Engineering, 2005, 24(2): 241-245.
[7] 卢波, 丁秀丽, 邬爱清. 岩体随机不连续面产状数据划分方法研究[J]. 岩石力学与工程学报, 2007, 26(9): 1809-1816.
LU Bo, DING Xiuli, WU Aiqing. Study on method of orientation data partitioning of randomly distributed discontinuities of rocks[J]. Chinese Journal of Rock Mechanics and Engineering, 2007, 26(9): 1809-1816.
[8] 董贵明, 束龙仓, 王茂枚, 等. 模糊信息分配法在裂隙结构面特征统计中的应用[J]. 中南大学学报(自然科学版), 2011, 42(8): 2493-2498.
DONG Guiming, SHU Longcang, WANG Maomei, et al. Application of fuzzy information diffusion method in fissure structural plane analysis[J]. Journal of Central South University (Science and Technology), 2011, 42(8): 2493-2498.
[9] 宋金龙, 黄润秋, 裴向军. 基于粒子群算法的岩体结构面产状模糊C均值聚类分析[J]. 工程地质学报, 2012, 20(4): 591-598.
SONG Jinlong, HUANG Runqiu, PEI Xiangjun. Particle swarm optimization algorithm based fuzzy C-means cluster analysis for discontinuities occurrence in rock mass[J]. Journal of Engineering Geology, 2012, 20(4): 591-598.
[10] Tokhmechi B, Memarian H, Moshiri B, et al. New logic in joint set classification using MLP neural network and discussing their uncertainties[J]. Journal of the Earth, 2009, 4(1): 11-27.
[11] Tokhmechi B, Memarian H, Moshiri B, et al. Investigating the validity of conventional joint set clustering methods[J]. Engineering Geology, 2011, 118(3): 75-81.
[12] 徐黎明, 陈剑平, 王清. 多参数岩体结构面优势分组方法研究[J]. 岩土力学, 2013, 34(1): 189-195.
XU Liming, CHEN Jianping, WANG Qing. Study of method for multivariate parameter dominant partitioning of discontinuities of rock mass[J]. Rock and Soil Mechanics, 2013, 34(1): 189-195.
[13] 边肇祺,张学工. 模式识别[M]. 北京: 清华大学出版社, 2000.
BIAN Zhaoqi, ZHANG Xuegong. Pattern recogmtion[M]. Beijing: Tsinghai University Press, 2000: 338-353.
[14] 张敏, 于剑. 基于划分的模糊聚类算法[J]. 软件学报, 2004, 15(6): 858-868.
ZHANG Min, YU Jian. Fuzzy Partitional clustering algorithms[J]. Journal of Software, 2004, 15(6): 858-869.
[15] Priest S D, Hudson J A. Discontinuity spaces in rock[J]. International Journal of Rock Mechanics and Mining Sciences & Geomechanics Abstracts, 1976, 13(5): 135-148.
[16] Hudson J A, Priest S D. Discontinuity frequency in rock masses[J]. International Journal of Rock Mechanics and Mining Sciences & Geomechanics Abstracts, 1983, 20(2): 73-89.
(编辑 邓履翔)
收稿日期:2014-01-10;修回日期:2014-03-23
基金项目(Foundation item):国家重点基础研究发展计划(“973”计划)项目(2011CB710605);国家自然科学基金资助项目(41172282);北京市科学技术委员会重点资助项目(20090102-2796)(Project (2011CB710605) supported by the National Basic Research and Development Program (973 Program), China; Project (41172282) supported by the National Natural Science Foundation of China; Project (20090102-2796) supported by the Science and Technology Committee of Beijing, China)
通信作者:曹洋兵(1987-),男,江西九江人,博士研究生,从事岩体稳定性评价与防治研究;电话:13659891513;E-mail:cybing1140504@163.com

