
J. Cent. South Univ. (2019) 26: 2495-2503
DOI: https://doi.org/10.1007/s11771-019-4189-1
Recognition of newspaper printed in Gurumukhi script
Rupinder Pal Kaur1, Manish Kumar Jindal2, Munish Kumar3
1. Post Graduate Department of Computer Science, Guru Nanak College for Girls,Sri Muktsar Sahib, Punjab, India;
2. Department of Computer Science & Applications, Panjab University Regional Centre,Sri Muktsar Sahib, Punjab, India;
3. Department of Computational Sciences, Maharaja Ranjit Singh Punjab Technical University,Bathinda, Punjab, India
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2019
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2019
Abstract: In this work, a system for recognition of newspaper printed in Gurumukhi script is presented. Four feature extraction techniques, namely, zoning features, diagonal features, parabola curve fitting based features, and power curve fitting based features are considered for extracting the statistical properties of the characters printed in the newspaper. Different combinations of these features are also applied to improve the recognition accuracy. For recognition, four classification techniques, namely, k-NN, linear-SVM, decision tree, and random forest are used. A database for the experiments is collected from three major Gurumukhi script newspapers which are Ajit, Jagbani and Punjabi Tribune. Using 5-fold cross validation and random forest classifier, a recognition accuracy of 96.19% with a combination of zoning features, diagonal features and parabola curve fitting based features has been reported. A recognition accuracy of 95.21% with a partitioning strategy of data set (70% data as training data and remaining 30% data as testing data) has been achieved.
Key words: newspaper recognition; feature extraction; classification; Gurumukhi script; random forest
Cite this article as: Rupinder Pal Kaur, Manish Kumar Jindal, Munish Kumar. Recognition of newspaper printed in Gurumukhi script [J]. Journal of Central South University, 2019, 26(9): 2495-2503. DOI: https://doi.org/10.1007/ s11771-019-4189-1.
1 Introduction
Optical character recognition (OCR) is a process which is used to convert the scanned text document either printed or handwritten into the machine processable format. Many of the OCRs are being developed to work on recognition of text printed/handwritten in different scripts across the nation and also worldwide. Database to feed to OCRs training may be varied according to the requirement of users, database can be of books, general pages, post office letters, handwritten manuscripts, ancient text documents, etc. A lot of work has been done on all these fields and still in progress. Many of the researchers are also working on the development of OCR for newspapers so that people could be enabled to store a lot of information in digital and most important in searchable form. Large research project is established in the United States to digitize historic newspapers from 1836 to 1922 and working on providing more searchable data. Many more projects are running to digitize newspapers. If we discuss about digitization of newspapers printed in Indian scripts, a few research works are reported on the Bangla script as best to our knowledge. Text graphic segmentation of an article in few Indian scripts is performed by GARG et al [1]. Gurumukhi (Punjabi) newspapers are read by a large number of people in the north India as well as abroad. So, this has motivated us to digitize and recognize newspapers printed in Gurumukhi script so that we can store valuable historical as well as eventual information. To recognize scripts of any newspaper, three phases are considered, namely, segmentation, feature extraction, and classification. Segmentation is a process which is used for dividing any article image into various blocks such as headline and columns, and further segmentation of columns into lines, line into words and words into characters, i.e., until the smallest unit is not received, and segmentation process carries on. After segmentation phase, various features are extracted from the smallest units of text printed in the newspaper. Feature extraction is a very important phase of an OCR because recognition accuracy generally depends upon the quality of the extracted features. Features are distinct properties of any character that helps in recognizing the class of character and differentiate it from other characters. Recognition of any character depends upon the type of feature extracted and how many features are extracted. Both structural as well as statistical features can be used for the purpose. Finally, classification phase is used to classify/recognize the characters based on the extracted features.
2 Reported work
A good number of research works on feature extraction techniques for handwritten as well as printed text are available in literature, for example, hybrid feature extraction technique of structural, statistical and correlation techniques are used for handwritten roman documents by AYYAZ et al [2]. A detailed review of feature extraction techniques is presented by KUMAR et al [3]. In this paper, authors have discussed various statistical, global transformation and series expansion, geometrical and topological features. After discussing the types of features, authors have explained methods of feature extraction like diagonal based feature extraction, Fourier descriptor, principal component analysis (PCA), independent component analysis (ICA), Gabor filter, Fractal theory technique, shadow features, extraction of distance, angle features, etc. DAS et al [4] have worked for recognition of handwritten Bangla characters. They considered a convex hull based feature set and a dataset of approximately 10000 samples for experimental work. They used Graham scan algorithm [5] for computation of convex hull and extracted 125 features on different bays and lakes of convex hull to recognize a character. Using this technique, they achieved maximum recognition accuracy of 76.86% with 10000 samples of the dataset. MAITRA et al [6] have used convolution neural network (CNN) based feature vector for recognizing text printed in multiple scripts like Bangla, Devanagari, Oriya, Roman and Telugu. They have achieved maximum recognition accuracy of 99.10% for multiple scripts using SVM classifier. Handwritten Devanagari numeral recognition is dealt by PRABHANJAN et al [7]. Features of characters and numerals are extracted by using Fourier descriptors which are applied in boundary coordinates of the planer curve and derived zonal features by dividing the image into 16 blocks. Further, five classifiers are used for recognizing based on the extracted features. These five classifiers are Na ve Bayes, Instance Based Learner, Random Forest, Sequential Minimal Optimization and Stacking. They have reported maximum recognition accuracy of 99.68% using 10-fold cross validation technique. Various experiments using different features for offline handwritten Gurumukhi characters are carried out by KUMAR et al [8] and they have also proposed a few new feature extraction methods for character recognition. KUMAR et al [9] have also proposed parabola curve fitting and power curve fitting techniques for handwritten character recognition. They have also presented a comparative study of the proposed techniques and various other feature extraction techniques like zoning, directional and transition. Authors have claimed that parabola curve fitting and power curve fitting techniques are performing better than other existing techniques for offline handwritten Gurmukhi character recognition. JINDAL et al [10] presented some structural features to recognize printed text in degraded Gurmukhi script documents. They defined nine structural features based on topology and geometry property of the Gurumukhi script. These features are in presence of full sidebar, half sidebar, presence of headline, number of junctions with the headline and baseline, profile direction codes, directional distance distribution, transition features, etc. For classification, they considered two classifiers, namely, k-NN and SVM and achieved maximum recognition accuracy of 83.6% using k-NN classifier. DHIMAN et al [11] have presented discrete cosine transform (DCT) and Gabor filter feature extraction techniques for recognition of Gurmukhi script recognition. They have extracted 100 features using DCT and 189 features from 50 classes and 1600 samples. They achieved 92.6% and 96.9% recognition accuracy using k-NN classifier with Gabor filter and DCT features, respectively. In this paper, we have used four statistical feature extraction techniques, namely, zoning features, diagonal features, curve fitting based features (parabola curve fitting and power curve fitting) for recognition of newspaper printed in Gurmukhi script. In classification phase, there are four classifiers, namely, k-NN, linear-SVM, decision tree, and random forest. For experimental results, the entire dataset is experimenting with two methodologies, namely, k-fold cross validation and 70%-30% (training set-testing set) partitioning.
ve Bayes, Instance Based Learner, Random Forest, Sequential Minimal Optimization and Stacking. They have reported maximum recognition accuracy of 99.68% using 10-fold cross validation technique. Various experiments using different features for offline handwritten Gurumukhi characters are carried out by KUMAR et al [8] and they have also proposed a few new feature extraction methods for character recognition. KUMAR et al [9] have also proposed parabola curve fitting and power curve fitting techniques for handwritten character recognition. They have also presented a comparative study of the proposed techniques and various other feature extraction techniques like zoning, directional and transition. Authors have claimed that parabola curve fitting and power curve fitting techniques are performing better than other existing techniques for offline handwritten Gurmukhi character recognition. JINDAL et al [10] presented some structural features to recognize printed text in degraded Gurmukhi script documents. They defined nine structural features based on topology and geometry property of the Gurumukhi script. These features are in presence of full sidebar, half sidebar, presence of headline, number of junctions with the headline and baseline, profile direction codes, directional distance distribution, transition features, etc. For classification, they considered two classifiers, namely, k-NN and SVM and achieved maximum recognition accuracy of 83.6% using k-NN classifier. DHIMAN et al [11] have presented discrete cosine transform (DCT) and Gabor filter feature extraction techniques for recognition of Gurmukhi script recognition. They have extracted 100 features using DCT and 189 features from 50 classes and 1600 samples. They achieved 92.6% and 96.9% recognition accuracy using k-NN classifier with Gabor filter and DCT features, respectively. In this paper, we have used four statistical feature extraction techniques, namely, zoning features, diagonal features, curve fitting based features (parabola curve fitting and power curve fitting) for recognition of newspaper printed in Gurmukhi script. In classification phase, there are four classifiers, namely, k-NN, linear-SVM, decision tree, and random forest. For experimental results, the entire dataset is experimenting with two methodologies, namely, k-fold cross validation and 70%-30% (training set-testing set) partitioning.
3 Characteristics of Gurumukhi script
Gurumukhi script is mainly used for writing the Punjabi language and sometimes for Sindhi language. A few features of Gurumukhi characters are as following:
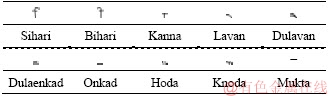
1) Gurumukhi script consists of 35 consonants (known as Akhar). Among these consonants first three characters are basics for vowels.
2) Other than 35 consonants, Gurumukhi script also consists of 10 vowels (known as Lagamatra).
3) There are some vowel modifiers like for nasal sound Tippi (M) and Bindi (W), and one vowel is for duplicating the sound of any character, i.e., Adhak ( ` )
4) Other than ‘Akhar’ and ‘LagaMatras’ there are six characters formed by placing a dot in foot of the consonants. These characters are  ,
,  ,
,  ,
,  ,
,  and
and  .
.
5) The writing style of Gurmukhi script is similar to a few other Indian scripts in respect to the headline. The headline is the main line above the characters which combine to constitute a word.
6) Most of the characters in Gurumukhi have either full or half vertical sidebar. This is the main structural feature of characters. Another feature is open or closed loops among the many other features.

Figure 1 Gurmukhi consonants
Table 1 Vowels (LagaMatras) in Gurumukhi script
4 Data collection and pre-processing
We have digitized more than one hundred articles of different newspapers like Ajit, Jagbani and Punjabi Tribune printed in Gurmukhi script. After digitization task, we have performed segmentation on all articles. An article is segmented into headline and columns and further segmentation into the smallest unit. In this work, we have considered 50 samples per class (each character). We have faced a major problem during the segmentation process which is the quality of the text printing as shown in Figures 2-5. Various fonts are used for printing of newspaper text, like for headline and body text are depicted in Figure 2 and text printing style also varies from newspaper to newspaper. We collected samples from Ajit, Jagbani and Punjabi Tribune. Sometimes these samples are also broken due to degraded quality of printing or paper as shown in Figure 3. Newspaper text sometimes may be heavily inked or touched and poses a difficulty in recognition of the character as depicted in Figures 4-5. In the present work, we have considered all types of these problems. In pre-processing phase, the size of samples is normalized into 64×64 pixels by using nearest neighborhood interpolation algorithm and normalized sample of character is converted into a thinned bitmap image.

Figure 2 Different shapes of a character printed in Gurmukhi script

Figure 3 Broken character due to printing or paper quality

Figure 4 Heavily printed characters in Gurmukhi script

Figure 5 Touching characters in Gurmukhi scrip
5 Feature extraction
Feature extraction is an important task of the character recognition process which is used to measure the relevant shape contained in the character. The performance of the recognition system depends on the quality of features which are being extracted. In OCR applications, it is essential to extract those features that will make the system possible to differentiate between all the character classes that exist. In the present paper, four statistical feature extraction techniques, namely, zoning features, diagonal features, parabola curve fitting based features and power curve fitting based features are considered. Various fusions of these techniques are also experimented in this paper.
5.1 Zoning features
In zoning feature extraction technique, a character image is divided into multiple zones, each of equal size. In the present work, a character image of 64×64 is divided into 4 zones, and then each zone is further divided into 16 zones. After that, each block among the 16 zones are further divided into 4 blocks as shown in Figure 6. So, total 85 zones of a character image are used to calculate the foreground pixel density of a character image. The following steps are considered for extracting the zoning features of a character image:
Step 1: Input the digitized image of a character and convert it into the binary image;
Step 2: Divide the bitmapped character image into n number of equal sized zones in hierarchical order;
Step 3: Count black pixels in each zone and calculate density of the zone.Density of a zone=(Total number of foreground pixels (black pixels) in a zone)/(Total number of pixels in a zone)
Step 4: Store the density value of each zone into a feature vector.Finally, we have extracted 85 features of a character image.
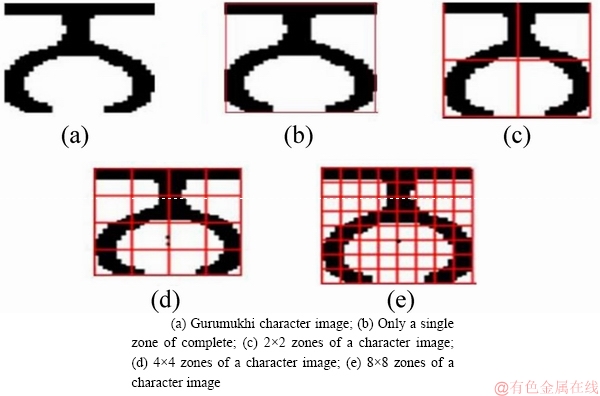
Figure 6 Zones of a character printed in Gurumukhi script:
5.2 Diagonal features
In diagonal feature extraction technique, each character image is divided into equal sized zones as discussed in zoning based feature extraction technique. Here, features are extracted along with diagonals of each zone. Pixels around each diagonal contribute in calculating value for feature vector of each zone as shown in Figure 7. The following steps have been used for extracting the diagonal features:
Step 1: Input the digitized image of a character and convert it into the binary image;
Step 2: Divide the bitmapped character image into n number of equal sized zones in hierarchical order;
Step 3: Each zone has n number of diagonals. Calculate number of foreground pixels along with each diagonal to extract sub-feature values of each zone;
Step 4: If a zone does not have any foreground pixels, then the feature value is taken as zero;
Step 5: Sum up all the sub feature values of each diagonal and calculate average featured value of all sub value to form a single feature value for the particular zone.

Figure 7 Diagonal features of a Gurmukhi character
Using these steps, we have extracted 85 features of a character image.
5.3 Parabola curve fitting based features
In parabola curve fitting, a best fit curve is formed based on foreground pixels in each zone. We have divided a character image of 64×64 into 85 equal sized zones as discussed in zoning based features. Calculate the values of a, b and c using least square method according to the parabola curve fitting equations as explained in Ref. [9] and normalize feature value in the scale of [0, 1] to create a feature vector for each sample of a character image. Following steps are used for extracting the parabolic curve fitting based features:
Step 1: Input the digitized image of a character and convert it into the binary image;
Step 2: Divide the bitmapped character image into n number of equal sized zones in hierarchical order;
Step 3: For each zone, find the best fit curve (parabola) using the equation y=a+bx+cx2. Find the values of variables a, b and c using the least square method (LSM), see Figure 8.
Step 4: If any zone does not have any foreground pixel, then set the value of a, b and c equal to zero;
Step 5: Normalize feature value in the scale of [0,1].
Using these steps, we have extracted 255 (85 values of a, 85 values of b, and 85 values of c) features of a character image.
5.4 Power curve fitting based features
For power curve fitting method [9], the image is again divided into n number of zones. In power curve fitting, the equation logy=loga+blogx is used which forms a linear relationship between x and y. The value of a and b are calculated using LSM method. Using these values of a and b, the power curve is generated in each zone of a character image. Then, normalize the values of feature vector in the scale of [0, 1]. For extracting the power curve fitting based features, following steps are considered:
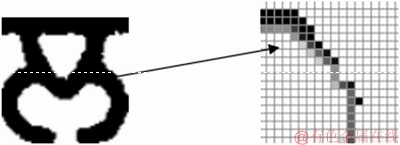
Figure 8 Parabola curve fitting based features of a Gurmukhi character
Step 1: Input the digitized image of a character and convert it into the binary image;
Step 2: Divide the bitmapped character image into n number of equal sized zones in hierarchical order;
Step 3: For each zone find the best fit curve (power curve) using the equation logy=loga+blogx. Find the values of variables a, and b using LSM;
Step 4: If any zone does not have any foreground pixel, then set the value of a and b equal to zero;
Step 5: Normalize feature value in the scale of [0, 1].
Using these steps, we have extracted 85 features of a character image.
6 Classification
After feature extraction phase, classification phase is used to recognize the class of unknown character based on the features extracted in the previous phase. For any classifier to identify the unknown character, initially, we have to train the classifier with a certain set of training dataset so that classifier must be able to match the extracted features with preset rules. In this work, we have used four classifiers that are k-nearest neighbor (k-NN), linear support vector machine (SVM), decision tree and random forest classifier. These classifiers are briefly discussed in the following sub-sections.
6.1 K-nearest neighbor
K-nearest neighbor classifier is also known as k-NN. In NN classifier the Euclidean distance is computed. The Euclidean distance d can be measured as:
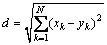
where k can be the total number of features in a feature set, x is features stored in training data and y is the candidate feature vector. Nearest feature vector with minimum Euclidean distance will vote for candidate feature to recognize its class. K is the number of sub-feature vector stored in a feature vector which will be the deciding factors for recognition of a pattern of an unknown character. It is probabily that any candidate feature will be of similar pattern as to the nearest feature vectors in the training dataset. In our work, we have kept the value of k as 1.
6.2 Support vector machine
This classifier is generally known as SVM. The working of SVM is based on supervised learning algorithms which can be used for both classification and regression. Basically, in SVM, we train it with separate classes of patterns. When we feed any input for the classification, SVM tries to match the pattern of input with pre-feed labeled patterns and produce output of recognized class.In this work, we have considered SVM with linear-kernel because it is a fast classifier for multi-class dataset with large number of features.
6.3 Decision tree
The decision tree is an efficient and simple classifier again based on supervised learning to recognize the class of a pattern. Decision tree uses a tree like graph, where on each node a question is crafted. According to feature set received in input, the decision tree tries to match the pattern through a series of questions. Decision tree classifier repeatedly classifies the problem in sub-parts until it reaches the conclusion.
6.4 Random forest
Random forest classifier works in an ensemble learning algorithm. Ensemble learning uses multiple algorithms to produce better classification results rather than using any single algorithm. Based on multiple algorithms, random forest constructs multiple decision trees at the time of training. Output from random forest is received as class of pattern which is an average of all the outputs received from the multiple classifiers. Random forest handles the problem of over fitting which is sometimes caused in the decision tree classifier. Nowadays, random forest is commonly used as an efficient classifier in the field of pattern recognition. So, we have used this classifier for newspaper text recognition printed in Gurmukhi script.
7 Experimental results and discussion
To train the classifiers, two methodologies are experimented, namely, k-fold cross validation and 70%-30% (training set-testing set) partitioning. In general, k-fold cross validation technique divides the entire data set into k equal sub-sets. Then one sub-set is taken as testing data and remaining (k-1) sub-sets are taken as training data. In partitioning category, we have considered 70% data of entire data as training dataset and the remaining data is considered as testing dataset. Total 1605 samples are experimented in this work. Four statistical feature extraction techniques, namely, zoning features, diagonal features, parabola curve fitting based features and power curve fitting based features are considered for recognition purpose. Various combinations of these techniques are also experimented in this paper and classifier wise recognition results are depicted in Tables 2 and 3. In Table 2, we have presented recognition results using 5-fold cross validation technique and Table 3, depicted the recognition results using partitioning strategy. These results are graphically depicted in Figures 9 and 10. Using 5-fold cross validation and random forest classifier, we have achieved maximum recognition accuracy of 96.19% with a combination of zoning features, diagonal features and parabola curve fitting based features. A recognition accuracy of 95.21% has been achieved with the same combination of features, when we considered 70% data as training dataset and remaining data as testing dataset.
8 Conclusions and future work
A recognition system for text recognition of newspaper printed in Gurmukhi script is presented in this paper. Four feature extraction techniques, namely, zoning features, diagonal features, parabola curve fitting based features, and power curve fitting based features are taken for extracting the statistical properties of characters. Various combinations are also attempted to improve the recognition accuracy. For recognition, four classification techniques, namely, k-NN, linear-SVM, decision tree, and random forest are used. Using 5-fold cross validation and random forest classifier, a recognition accuracy of 96.19% with a combination of zoning features, diagonal features and parabola curve fitting based features has been achieved. A recognition accuracy of 95.21% with a partitioning strategy of dataset (70% data as training data and remaining 30% data as testing data) has been achieved. This work can also be extended for newspapers printed in other Indian scripts. We can also use other techniques like multi-factor dimensionality reduction, multi-linear subspace learning, and non-linear dimensionality reduction for reducing the dimension of data and to extract representative features for text recognition.
Table 2 Recognition results using 5-fold cross validation

Table 3 Recognition results using partitioning strategy (70% data as training set and 30% data as testing set)
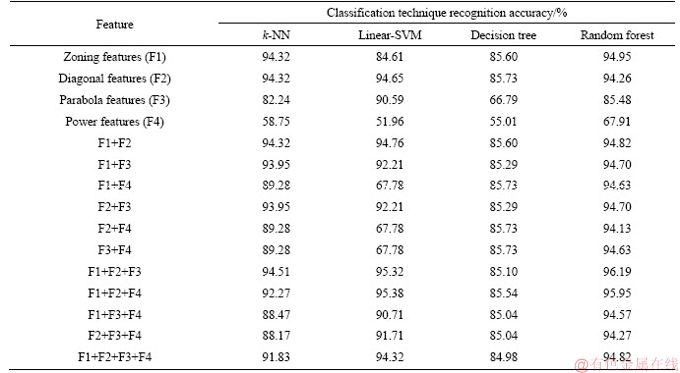
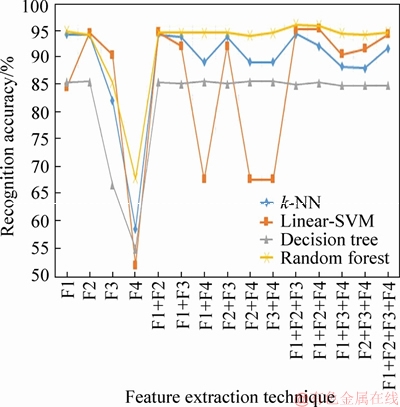
Figure 9 Classifier wise recognition results using 5-fold cross validation

Figure 10 Classifier wise recognition results using portioning strategy
References
[1] GARG R, BANSAL A, CHAUDHURY S, ROY S D. Text graphic separation in Indian newspapers [C]// Proceedings of the 4th International Workshop on Multilingual OCR. Washington D C , USA: ACM. 2013: 1-5.
[2] AYYAZ M N, JAVED I, MAHMOOD W. Handwritten character recognition using multiclass SVM classification with hybrid feature extraction [J]. Pakistan Journal of Engineering and Applied Sciences, 2012, 10: 57-67.
[3] KUMAR G, BHATIA P K. A detailed review of feature extraction in image processing systems [C]//Proceedings of the 2014 Fourth International Conference on Advanced Computing & Communication Technologies. Rohtak, India: IEEE. 2014: 5-12.
[4] DAS N, PRAMANIK S, BASU S, SAHA PK, SARKAR R, KUNDU M, NASIPURI M. Recognition of handwritten Bangla basic characters and digits using convex hull based feature set [C]//Proceedings of the International Conference on Artificial Intelligence and Pattern Recognition. Orlando, USA: Computer Vision and Pattern Recognition. 2014: 380-386.
[5] VY NIAUSKAITE L, VYD
NIAUSKAITE L, VYD NAS . A priori filtration of points for finding convex hull [J].Technological and Economic Development of Economy,2006, 12(4): 341-346.
NAS . A priori filtration of points for finding convex hull [J].Technological and Economic Development of Economy,2006, 12(4): 341-346.
[6] MAITRA D S, BHATTACHARYA U, PARUI S K. CNN based common approach to handwritten character recognition of multiple scripts [C]//Proceedings of the 2015 13th International Conference on Document Analysis and Recognition. Tunis, Tunisia: IEEE. 2015: 1021-1025.
[7] PRABHANJAN S, DINESH R. Handwritten Devanagari numeral recognition by fusion of classifiers [J]. Journal of Computer Engineering & Information Technology, 2015, 4(2): 1-6.
[8] KUMAR M, JINDAL M K, SHARMA R K, JINDAL S R. Offline handwritten pre-segmented character recognition of gurmukhi script [J]. Machine Graphics & Vision, 2016, 25(1-4): 45-55.
[9] KUMAR M, SHARMA R K, JINDAL M K. Efficient feature extraction techniques for offline handwritten Gurmukhi character recognition [J]. National Academy Science Letters, 2014, 37(4): 381-391.
[10] JINDAL M K, SHARMA R K, LEHAL G S. Structural features for recognizing degraded printed Gurmukhi script [C]// Proceedings of the 5th International Conference on Information Technology: New Generations. Las Vegas, USA: IEEE. 2008: 668-673.
[11] DHIMAN S, LEHAL G S. Performance comparison of Gurmukhi script: k-NN classifier with DCT and Gabor filter [J]. International Journal of Advanced Research in Computer Science, 2017, 8(5): 762-764.
(Edited by FANG Jing-hua)
中文导读
Gurumukhi印刷报纸的文字识别
摘要:本文提出了一种基于Gurumukhi字体的报纸识别系统。采用分区特征、对角线特征、抛物线拟合特征和势曲线拟合特征提取技术对报刊印刷字符的统计特性进行提取。为了提高识别精度,还对这些特征进行了不同的组合。在识别方面,采用了k-神经网络、线性支持向量机、决策树和随机森林四种分类技术。实验数据库是从三家主要的Gurumukhi字体报纸Ajit, Jagbani和Punjabi Tribune收集的。采用五倍交叉验证和随机森林分类器,以及分区特征、对角线特征和抛物线拟合特征相结合的方法,识别准确率达96.19%。采用数据集分割策略(70%的数据作为训练数据,其余的30%的数据作为测试数据),识别准确率达到95.21%。
关键词:报纸识别;特征提取;分类;Gurumukhi字体;随机森林算法
Received date: 2018-02-14; Accepted date: 2018-12-24
Corresponding author: Munish Kumar, PhD, Assistant Professor; Tel: +91-98723-19157; E-mail: munishcse@gmail.com; ORCID: 0000-0003-0115-1620

